
全網都在要Manus AI邀請碼,可能是 DeepSeek 后最大驚喜
DeepSeek 開源周的第三天,帶來了專為 Hopper 架構 GPU 優化的矩陣乘法庫 — DeepGEMM。這一庫支持標準矩陣計算和混合專家模型(MoE)計算,為 DeepSeek-V3/R1 的訓練和推理提供強大支持,在 Hopper GPU 上達到 1350+FP8 TFLOPS 的高性能。
DeepGEMM 的設計理念是簡潔高效,核心代碼僅約 300 行,同時在大多數矩陣尺寸下性能優于現有解決方案。該庫支持三種數據排列方式:標準排列和兩種專為混合專家模型設計的特殊排列(連續排列和掩碼排列)。DeepGEMM 采用即時編譯技術,不需要在安裝時進行編譯,代碼結構清晰易懂,非常適合學習 GPU 優化技術。
DeepGEMM 在各種計算場景下表現出色。 對于標準矩陣乘法,與基于 CUTLASS 3.6 的優化實現相比,速度提升 1.0 到 2.7 倍不等。小批量數據處理(M=64 或 128)獲得了最顯著的加速,最高達到 2.7 倍。
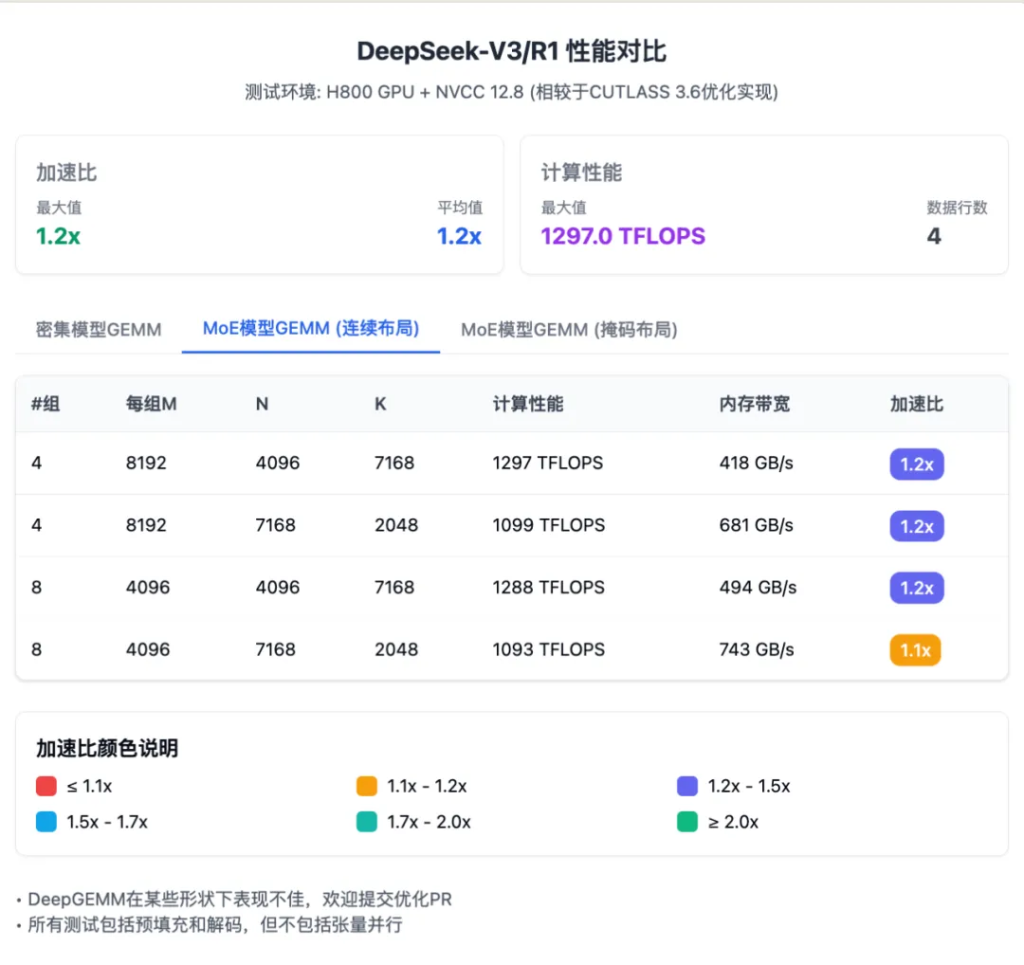
對于混合專家模型的計算,DeepGEMM 提供的兩種特殊數據排列方式也有明顯優勢。 連續排列方式適用于訓練和批量推理階段,速度提升約 1.1 到 1.2 倍;掩碼排列方式專為實時推理設計,支持與 CUDA 圖技術配合使用,同樣能提速 1.1 到 1.2 倍。
考慮到官方的數據不太易讀,我給重新做了 3 張,請叫我賽博菩薩:


在計算機中,數值需要用二進制位存儲,存儲方式決定了精度和所需空間。傳統上,AI 計算使用 32 位浮點數(FP32),這提供了很高的精度,但占用較多存儲空間和計算資源。
研究表明,很多 AI 任務實際上不需要這么高的精度。16 位浮點數(FP16)已被廣泛采用,而 8 位浮點數(FP8)是更進一步的精度降低。雖然 FP8 精度較低,但對許多 AI 任務已經足夠,同時能大大減少內存使用并提高計算速度。 這就像用較粗的刻度測量大物體,雖然精度降低,但速度快得多,且在大多數情況下已經足夠準確。
GEMM(通用矩陣乘法)是深度學習中最基礎也最常見的計算操作。簡單來說,它計算兩個數據表格(矩陣)相乘的結果。這看似簡單,但在 AI 計算中,這些矩陣可能非常龐大,含有數百萬個元素,使得矩陣乘法成為整個系統中最耗時的部分之一。幾乎所有神經網絡層的計算本質上都包含矩陣乘法操作。
DeepGEMM 專門優化了 FP8 精度的矩陣乘法,同時解決了 Hopper 架構在處理 FP8 計算時可能出現的精度問題,確保計算結果準確可靠。
標準矩陣乘法處理的是完整矩陣之間的運算,適用于傳統神經網絡架構,所有數據都經過統一處理。
而混合專家模型(MoE)是一種特殊的神經網絡架構,它包含多個”專家”網絡和一個”門控”網絡。 門控網絡負責決定將輸入數據分配給哪些專家處理,而不是所有數據都經過所有專家。這種方法允許模型規模大幅增長,同時保持計算效率,因為每次處理只激活部分模型而非全部。
針對 MoE 模型,DeepGEMM 提供了兩種特殊數據排列方式:
NVIDIA 的 Hopper GPU 是專為人工智能和高性能計算設計的最新硬件平臺,提供了多項關鍵技術改進:
張量核心是 GPU 內部的特殊計算單元,專門針對矩陣運算進行了優化,能大幅加速深度學習計算。Hopper 架構的張量核心支持 FP8 計算,比前代產品提供更高性能。
TMA(張量內存加速器)是 Hopper 架構引入的新功能,用于更快速、異步地移動數據。DeepGEMM 充分利用 TMA 技術加載和存儲數據,并使用 TMA 多播和描述符預取等高級功能進一步提升性能。
即時編譯(Just-In-Time)是一種程序在運行時才進行編譯的技術,而非傳統的在安裝或部署時預先編譯。DeepGEMM 采用完全即時編譯設計,所有計算內核都在實際運行時進行編譯,這帶來幾個優勢:
這種即時編譯方法顯著提高了小矩陣形狀的計算性能,技術思路類似于 Triton 等現代編譯器。
CUDA 是 NVIDIA 開發的并行計算平臺和編程模型,允許開發者利用 GPU 強大的并行處理能力。這是編寫 GPU 程序的基礎工具。
CUTLASS 是 NVIDIA 的開源矩陣乘法庫,提供了高性能的矩陣計算模板。DeepGEMM 借鑒了 CUTLASS 的一些思路,但沒有直接依賴其復雜的模板系統,而是自行實現了一套更簡潔的代碼,既保證性能又易于理解和學習。
DeepGEMM 采用了線程專業化技術,這是一種高效的任務分工方法。在這種設計中,不同的計算線程被分配專門負責特定任務:一些負責數據移動,一些負責核心計算,一些負責結果處理。
這種分工使得數據移動、計算和后處理能夠同時進行,形成高效的流水線,大大提高整體性能。

DeepGEMM 包含多項先進技術創新:
傳統上,GPU 計算通常使用標準大小的數據塊(如 128×128)。DeepGEMM 支持非標準塊大小(如 112×128),這能更好地適應特定矩陣形狀,提高硬件資源利用率。例如,對于 M=256,N=7168 的矩陣,標準塊大小只能利用 112 個計算單元,而使用非標準塊大小可以利用 128 個,效率提升明顯。
通過分析不同編譯器版本產生的機器代碼,DeepGEMM 團隊發現并實現了特殊的指令排序優化。這種底層優化調整了計算指令的執行方式,使計算單元能更高效地并行工作,顯著提升了 FP8 計算性能。
DeepGEMM 設計了一套統一的計算任務調度系統,采用特殊的排布策略,增強緩存重用效率,減少內存訪問,提高整體性能。
使用 DeepGEMM 需要支持 sm_90a 的 Hopper 架構 GPU、Python 3.8 以上、CUDA 12.3 以上(推薦 12.8 以上獲得最佳性能)、PyTorch 2.1 以上以及 CUTLASS 3.6 以上。
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.pypython setup.py install
最后, import deep_gemm 就行了
DeepGEMM 提供了清晰的 Python 編程接口,包括:
同時,庫提供多個實用工具函數,用于設置計算資源和數據格式,讓開發者能根據具體需求進行配置。
DeepGEMM 作為 DeepSeek 開源周的第三日發布,為 Hopper 架構 GPU 提供了高效的 FP8 矩陣乘法實現。 通過精心設計的 300 行核心代碼,這個庫在多種場景下超越了現有解決方案,為普通神經網絡和混合專家模型提供了強大的計算基礎。
同時,其清晰的代碼,也堪稱是學習 GPU 優化技術的優質資源。
目前,DeepGEMM 專門針對 Hopper 架構 GPU 優化,未來可能擴展到更多硬件平臺。
文章轉載自:一文詳解:DeepSeek 第三天開源的 DeepGEMM







