
一步步教你進行 Python REST API 身份驗證
接下來,我將深入剖析每種 RAG 技術的核心理念、實現細節以及各自的優缺點,旨在幫助大家更全面地理解這些前沿方法。



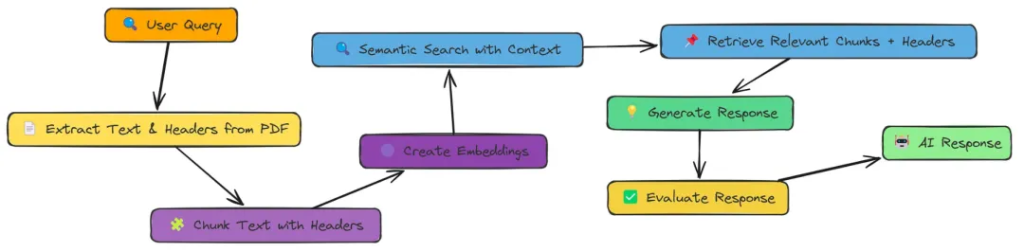
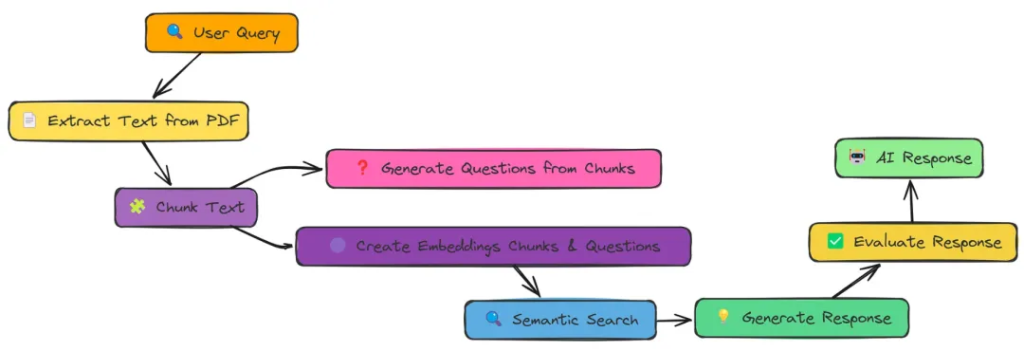




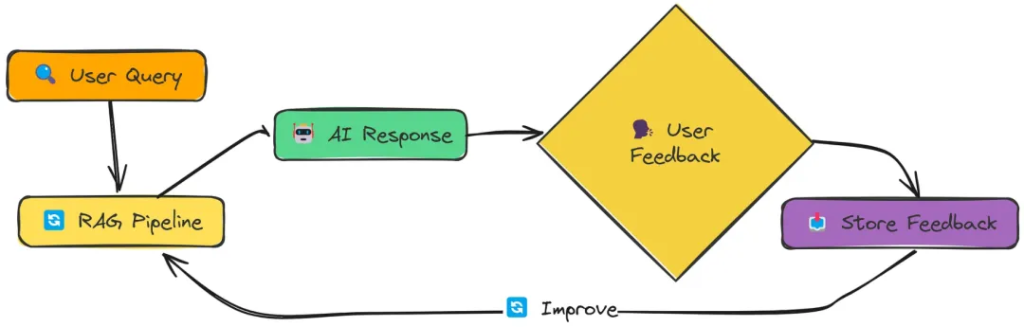




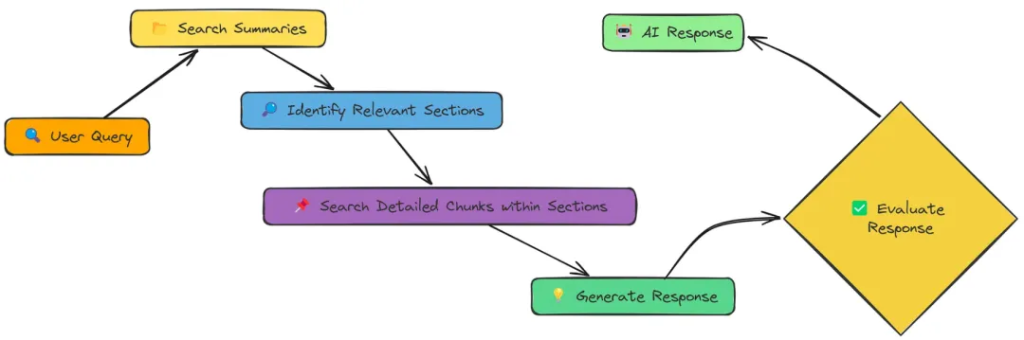




在實驗過程中,我全面測試了上述18種 RAG 技術。每種技術在檢索精度、響應效率以及實現難度上各有優勢,但實驗數據明確指出,Adaptive RAG 憑借其靈活的策略調整和出色的自適應能力,以0.86的高分在綜合性能上拔得頭籌,成為最優選擇。
通過此次實驗,我不僅深入掌握了每種 RAG 技術的核心原理和實際應用場景,還為在不同項目中挑選合適的技術方案積累了豐富經驗。展望未來,隨著生成模型和檢索技術的持續發展,RAG 方法將不斷演進,為問答系統帶來更高的智能化和效率提升。
文章轉載自:經過18次嘗試后,我發現了最佳 RAG 技術
