
如何快速實現REST API集成以優化業務流程
? ? ? 在檢索增強生成 (RAG) 的上下文中,Graph RAG 引入了一項重大增強功能:使用大型語言模型 (LLM(最好是 GPT-4) 將源文檔塊轉換為實體和關系。這個預處理步驟至關重要,因為實體及其之間關系的準確提取對于后續的知識圖譜構建至關重要,這因領域而異。
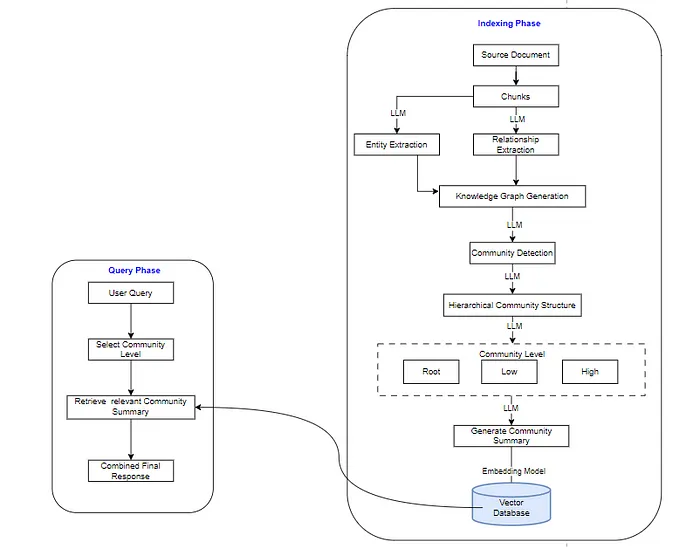
?當我們仔細觀察架構時,我們可以看到,首先將文檔拆分為可管理的塊,并將這些塊轉換為實體和關系,這些實體和關系構成了知識圖譜的基礎。利用 LLM,我們為每個節點確定最接近的社區,從而創建分層結構。此層次結構允許模型生成社區級別的摘要,然后將其存儲在向量數據庫中。
? ? ? 當用戶提交查詢時,將對其進行處理以標識最相關的社區級別。系統從排名最高的社區檢索摘要,并使用 LLM。
? ? ? ?RAG(檢索增強生成)和 Graph RAG 都有自己的優點和缺點。從我審查過的幾個測試用例來看,每種方法產生的響應都存在顯著差異。
? ? ? 與傳統 RAG 相比,Graph RAG 的主要優勢在于它能夠檢索有關查詢中提到的實體的全面詳細信息。Graph RAG 不僅獲取有關查詢實體的詳細信息,還標識并將其與其他連接的實體相關聯。相比之下,標準 RAG 檢索的信息僅限于特定文檔塊,更廣泛的關系和聯系捕獲不足。
? ? ? ?Graph RAG 的增強功能也有其自身的挑戰。在我的實驗中,我提取了一個包含大約 83,000 個令牌的文件,這些令牌需要分塊和嵌入。使用標準的 RAG 方法,使用大致相同數量的令牌創建嵌入。當我使用 Graph RAG 攝取同一個文件時,該過程涉及大量的提示和處理,產生了大約 1,000,000 個令牌——幾乎是單個文件原始令牌計數的 12 倍。
本文章轉載微信公眾號@ArronAI







