?索引過程是為檢索過程準備數(shù)據(jù)。你應(yīng)該收集你想讓你的LLM知道的一切,例如,產(chǎn)品文檔、產(chǎn)品政策、公司網(wǎng)站等,這取決于你想讓聊天機器人做什么。然后你會把它分解成更小的文本塊(這樣你就可以很容易地把這些塊放進LLM的上下文大小)。然后,你將通過嵌入模型將塊轉(zhuǎn)換為矢量表示(這樣以后你就可以很容易地找到類似的塊)。最后,你可以將所有這些文本嵌入對保存在索引或矢量數(shù)據(jù)庫中,以供檢索使用。
? ? ? ?檢索過程發(fā)生在用戶查詢LLM時。在用戶提出問題后,你可以保留該查詢,而不是直接將其發(fā)送到LLM。相反,你將使用索引中文本塊中的一些附加信息來豐富查詢。你將使用相同的嵌入模型對用戶的原始查詢進行編碼,然后執(zhí)行相似性搜索,在數(shù)據(jù)庫中找到最相似(大多數(shù)時候也是最相關(guān))的文本塊。
然后,為了生成,需要將文本塊插入到包括用戶原始查詢的提示中,LLM將使用檢索到的文本塊中提供的信息生成答案。
Answer the following question based on the given information only. If the given information is not enough to answer the question, simply reply "I don't know".
Question: "<user's original query>"
Given information: "<the text chunk you retrieved from the database>"RAG是業(yè)界公認的流程,LlamaIndex[1]和LangChain[2]兩個流行的庫支持上述這些步驟用于RAG流程。RAG需要矢量數(shù)據(jù)庫來創(chuàng)建索引和檢索,如Pinecone[3]和Chroma[4]。
這個過程簡單有效,但在現(xiàn)實世界中,經(jīng)常會面臨以下問題:
在下一節(jié)中,我們將介紹一些克服這些問題并提高RAG性能的技術(shù)。
? ? ? ?經(jīng)過近一年的LLM使用,我學(xué)到了許多提高RAG性能的技術(shù),并總結(jié)了一些使用RAG的經(jīng)驗教訓(xùn)。在本節(jié)中,我將介紹許多在檢索前、檢索中和檢索后提高RAG性能的技術(shù)。
預(yù)檢索技術(shù)包括可以在索引步驟中或在搜索數(shù)據(jù)庫中的塊之前使用的技術(shù)。
? ? ? ?第一種技術(shù)是提高索引數(shù)據(jù)的質(zhì)量。在機器學(xué)習(xí)領(lǐng)域,有一句話叫“垃圾進,垃圾出”,我認為這也適用于RAG,但許多人只是忽略了這一步驟,并在這一非常關(guān)鍵的初始步驟之后專注于優(yōu)化步驟。您不應(yīng)該期望將每一個文檔(無論是否相關(guān))都放入您的矢量數(shù)據(jù)庫,并抱著最好的希望。為了提高索引數(shù)據(jù)的質(zhì)量,您應(yīng)該:(1)刪除與特定任務(wù)無關(guān)的文本/文檔(2)將索引數(shù)據(jù)重新格式化為與最終用戶可能使用的格式類似的格式(3)向文檔中添加元數(shù)據(jù),以實現(xiàn)高效和有針對性的檢索。
這是我自己的一個例子。我需要檢索的文本是數(shù)學(xué)問題,但關(guān)于不同概念的兩個數(shù)學(xué)問題在語義上可能相似。例如,許多問題可能使用“湯姆第一天吃了8個蘋果……”,但它們可能測試加法、乘法和除法,這是非常不同的。在這種情況下,最好使用概念和級別的元數(shù)據(jù)對它們進行標記,并在檢索它們之前檢查正確的概念。
另一個非常典型的情況是,塊在拆分時可能會丟失信息。考慮一篇典型的文章,開頭的句子通過名字介紹實體,而后面的句子只依靠代詞來指代它們。不包含實際實體名稱的分割塊將失去語義,無法通過向量搜索進行檢索。因此,在這種情況下,用實際名稱替換代詞可以提高分割塊的語義意義。
? ? ? ?第二種技術(shù)是分塊優(yōu)化。根據(jù)你的下游任務(wù)是什么,你需要確定塊的最佳長度是多少,以及你希望每個塊有多少重疊。如果你的塊太小,它可能不包括LLM回答用戶查詢所需的所有信息;如果塊太大,它可能包含太多不相關(guān)的信息,從而混淆LLM,或者可能太大而無法適應(yīng)上下文大小。
根據(jù)我自己的經(jīng)驗,對于管道中的所有步驟,您不必拘泥于一種塊優(yōu)化方法。例如,如果您的管道同時涉及高級任務(wù)(如摘要)和低級任務(wù)(如基于函數(shù)定義的編碼),則可以嘗試使用較大的塊大小進行摘要,然而使用較小的塊大小作為編碼參考。
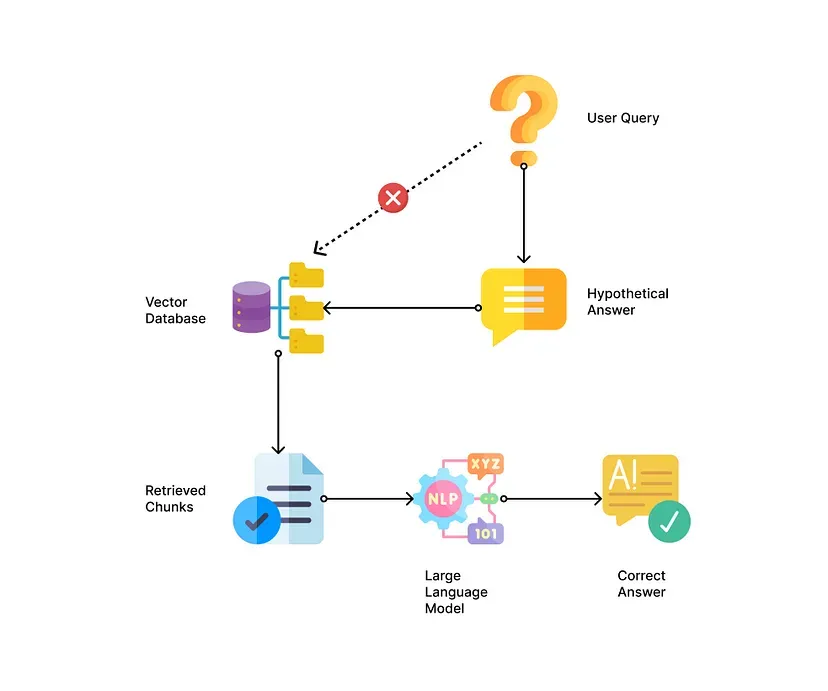
? ? ? ?還有另一種技術(shù)是在嘗試在矢量數(shù)據(jù)庫中匹配用戶的查詢之前重寫該查詢。此步驟的本質(zhì)是將用戶的查詢轉(zhuǎn)換為與矢量數(shù)據(jù)庫中的查詢格式和內(nèi)容類似的格式和內(nèi)容。Query2Doc技術(shù)生成偽文檔,并用這些文檔擴展查詢[5]。類似地,HyDE(假設(shè)文檔嵌入)生成與查詢相關(guān)的假設(shè)文檔[6]。
?以下是一些如何生成假設(shè)文檔的示例:
# if your reference documents are blog articles.
prompt = f"Please generate a paragraph from a blog article on {user_query}"
# if your reference documents are code documentations in markdown.
prompt = f"Please generate a code documentation for {user_query} in markdown format."使用Query2Doc或HyDE技術(shù)時的一個陷阱是,假設(shè)文檔可能與實際文檔相矛盾或完全不一致,這可能導(dǎo)致不準確的檢索。為了解決這個問題,您可以檢索包含和不包含假設(shè)文檔的文檔,這樣您就可以應(yīng)用我稍后將介紹的后期檢索技術(shù)來找到最佳參考文本。
? ? ? ?當用戶的查詢很復(fù)雜,可能需要多個參考文本時,可以使用LLM將其分解為多個子查詢,然后為每個查詢找到相關(guān)的文本塊。例如,如果用戶問兩個不同的問題“ChomaDB和Weaviate之間的區(qū)別是什么?”,可以分為“什么是ChromaDB?”和“什么是Weaviate?”。
? ? ? ? 下面是一個要求LLM分解查詢的示例:
Please rephrase the following query into three or fewer subqueries, so that each sub-query contains only one topic. Show each sub-query in each new line.
Query:"<original user query>"?如果您的聊天機器人或代理可以處理多個下游任務(wù)和不同格式的用戶查詢,您可以考慮使用查詢路由,在該路由中,您可以將查詢動態(tài)路由到不同的RAG進程。例如,如果你的用戶正在詢問一個問題的特定答案,你可以將他們路由到查詢特定的塊;如果你的用戶要求一個整體的摘要,你可以將他們路由到一個遞歸創(chuàng)建的許多檢索到的文檔的摘要;如果您的用戶要求在兩個文檔之間進行比較,您可能需要使用上面提到的子查詢技術(shù)。您可以使用LLM本身進行路由,也可以使用關(guān)鍵字匹配/嵌入相似性進行路由。
? ? ? ?準備好查詢后,可以在RAG管道的第二步中進一步改進檢索結(jié)果。
第一種技術(shù)經(jīng)常被忽視,因為人們只是跟著別人做——一直堅持向量相似性搜索。但是,您可以也應(yīng)該考慮使用其他搜索方法來取代向量相似性搜索,或者通過混合搜索來補充它。盡管矢量相似性搜索在大多數(shù)情況下可以找到相關(guān)文檔,但對于某些情況或數(shù)據(jù)結(jié)構(gòu),最好使用全文搜索、結(jié)構(gòu)化查詢、基于圖的搜索或混合搜索方法。
例如,如果您的文本數(shù)據(jù)包含許多語義非常相似的塊,但僅在某些關(guān)鍵字上有所不同,或者如果您的文字數(shù)據(jù)包含太多通用文字,則最好使用精確的關(guān)鍵字匹配進行搜索。例如,在電子商務(wù)中搜索僅按功能組不同的特定藥物名稱或數(shù)以萬計的類似產(chǎn)品名稱,可能會受益于全文匹配和過濾器。
另一個經(jīng)常被忽視的技術(shù)是針對特定任務(wù)測試和使用不同的嵌入。許多人甚至不會考慮這一點,因為框架/向量數(shù)據(jù)庫有一個默認的嵌入選項,他們只是隨波逐流。但不同的嵌入模型實際上可以捕獲不同的語義信息,并可能適用于不同的任務(wù)。一個有用的嵌入模型是指導(dǎo)嵌入,它允許您提供關(guān)于嵌入的數(shù)據(jù)類型和任務(wù)的具體說明[7][8]。您也可以參考MTEB排行榜,它是文本嵌入模型的基準。一定要測試這些模型,因為在排行榜上排名靠前并不意味著它最適合你的特定任務(wù)[9]。
除此之外,您還可以在檢索過程中進行一些調(diào)整,使檢索更具相關(guān)性。Small2big、遞歸或上下文感知檢索是一種最初檢索較小的數(shù)據(jù)塊,由于更具體和更詳細,這些數(shù)據(jù)塊更有可能與查詢匹配,然后繼續(xù)檢索父文檔或圍繞這些較小數(shù)據(jù)塊的較大文本塊,以包括更多上下文的技術(shù)。它們確保您檢索相關(guān)的塊以及所有重要的上下文。一些框架提供了對這種檢索的支持,如LangChain[2]中的ParentDocumentRetriever、句子窗口和LlamaIndex[1]中的節(jié)點引用。
如果您可以從小到大地檢索文檔,那么您也可以用另一種方式來檢索,分層檢索從更通用到更具體。例如,您可以創(chuàng)建兩層數(shù)據(jù),一層包含原始塊,另一層包含塊的摘要。您首先在摘要索引中搜索最相關(guān)的文檔,然后在這些文檔中再次搜索特定的塊。這樣,你可以在第一關(guān)快速過濾掉不相關(guān)的文檔,然后在第二關(guān)找到實際的信息進行問答。
? ? ? ?類似地,您可以將遞歸搜索與圖形搜索結(jié)合使用。該方法將相似性搜索與圖形數(shù)據(jù)結(jié)構(gòu)相結(jié)合。您首先通過向量相似性搜索找到最相關(guān)的塊,然后探索與這些塊相關(guān)的節(jié)點,以探索更多潛在的有用信息。例如,如果您有一個包含Notion或Obsidian等互連文檔的數(shù)據(jù)庫,則可以通過鏈接輕松找到LLM的相關(guān)文檔。LlamaIndex通過RecursiveRetriever模塊支持類似的搜索。
還有更多的代理方式來執(zhí)行檢索,方法是首先使用查詢文檔的工具/功能創(chuàng)建檢索器代理,并讓它決定是搜索更多信息還是僅將相關(guān)的檢索塊返回給原始代理以回答用戶的查詢。但這些技術(shù)通常需要更長的響應(yīng)時間,而且可能不穩(wěn)定,因此可能不是很好的生產(chǎn)選擇。希望通過更強大的模型和更快的推理,我們可以在這個方向上獲得更好的結(jié)果。
在從數(shù)據(jù)庫中檢索到相關(guān)的塊之后,仍然有更多的技術(shù)可以提高生成質(zhì)量。根據(jù)任務(wù)的性質(zhì)和文本塊的格式,您可以使用以下一種或多種技術(shù)。
? ? ? ?如果你的任務(wù)與一個特定的塊更相關(guān),一種常用的技術(shù)是重新排序或評分。正如我前面提到的,向量相似性搜索中的高分并不意味著它總是具有最高的相關(guān)性。你應(yīng)該進行第二輪重新排序或評分,找出對生成答案真正有用的文本塊。對于重新排序或評分,您可以要求LLM對文檔的相關(guān)性進行排序,也可以使用一些其他方法,如關(guān)鍵字頻率或元數(shù)據(jù)匹配,在將這些文檔傳遞給LLM以生成最終答案之前,對選擇進行細化。
? ? ? ?另一方面,如果你的任務(wù)與多個塊有關(guān)——比如摘要或比較。您可以在將信息傳遞給LLM之前進行一些信息壓縮作為后處理,以減少噪聲或上下文長度。例如,您可以首先從每個塊中總結(jié)、轉(zhuǎn)述或提取關(guān)鍵點,然后將聚合的、濃縮的信息傳遞給LLM進行生成。
? ? ? ?我發(fā)現(xiàn)還有一些其他技巧可以幫助改進和平衡生成質(zhì)量和延遲。在實際生產(chǎn)中,您的用戶可能沒有時間等待多步驟RAG過程完成,尤其是當存在LLM調(diào)用鏈時。如果您想提高RAG管道的延遲,以下選擇可能會有所幫助。
? ? ? ?第一種是在某些步驟中使用更小、更快的模型。對于RAG過程中的所有步驟,您不一定需要使用最強大的模型(通常是最慢的)。例如,對于一些簡單的查詢重寫、假設(shè)文檔的生成或文本塊的匯總,您可能可以使用更快的模型(如7B或13B本地模型)。這些模型中的一些甚至能夠為用戶生成高質(zhì)量的最終輸出。
? ? ? 如果你感興趣,你可以閱讀更多關(guān)于如何運行本地模型的信息[11],并在這個GitHub Repo[12]中查看我對一些小型LLM的評級。
? ? ? ?下一個技術(shù)是使一些中間步驟并行運行。你不必總是等到一步完成后再進入第二步。您可以進行一些中間步驟,如并行混合搜索或多個塊并行的摘要。要做到這一點,您可能需要大量修改RAG框架或自己創(chuàng)建RAG管道,但這可以大大減少最終輸出的時間。
? ? ??第三種技術(shù)是如果可能的話,讓LLM做出多項選擇,而不是生成長文本。例如,在重新排序/評分時,您可以要求LLM僅列出文本塊的分數(shù)/排名,而不是將其生成或包括詳細解釋。
? ? ? ?另一個有用的提示是為常見問題或常見查詢實現(xiàn)緩存。如果新查詢與舊查詢非常相似或幾乎相同,則系統(tǒng)可以提供即時答案,而無需每次都經(jīng)過整個RAG過程。如果新查詢有點相似,但仍然相關(guān),您甚至可以將上一個查詢的答案包含到LLM中,作為生成新答案的參考。
? ? ? ?在本文中,我介紹了許多可以在LLM支持的應(yīng)用程序中改進RAG管道的技術(shù),包括:
-RAG的基本過程:索引、檢索和生成
-預(yù)檢索技術(shù):
-檢索技術(shù)
-后期檢索技術(shù)
-平衡質(zhì)量和延遲
? ? ? 您可以在RAG管道中使用其中一種或多種技術(shù),使其更加準確和高效。我希望這些技術(shù)可以幫助你為你的應(yīng)用程序構(gòu)建一個更好的RAG管道。
[1] http://www.llamaindex.ai/
[2] http://www.langchain.com/
[3] http://www.pinecone.io/
[4] http://www.trychroma.com/
[5] https://browse.arxiv.org/abs/2303.07678
[6] https://browse.arxiv.org/abs/2212.10496
[7] https://browse.arxiv.org/abs/2212.09741
[8] https://github.com/xlang-ai/instructor-embedding
[9] https://huggingface.co/spaces/mteb/leaderboard
[10] https://doi.org/10.48550/arXiv.2312.10997
[11] https://medium.com/design-bootcamp/a-complete-guide-to-running-local-llm-models-3225e4913620
[12] https://github.com/Troyanovsky/Local-LLM-Comparison-Colab-UI
[13]?https://bootcamp.uxdesign.cc/how-to-improve-rag-results-in-your-llm-apps-from-basics-to-advanced-822818014144
本文章轉(zhuǎn)載微信公眾號@ArronAI