
如何快速實現REST API集成以優化業務流程
Vanilla RAG 使用最簡單的方式大致如下所示:1)將文本分割成塊;2)然后使用Transformer編碼器模型將這些塊編碼成向量,并將這些所有向量存儲到向量數據庫中;3)最后創建一個LLM提示,并讓模型根據搜索到的上下文來回答用戶的查詢。
在執行交互時,使用相同的編碼器模型對用戶的查詢進行向量化,然后執行向量索引,找到相關性最高的top-k個結果,從向量數據庫中檢索出這些索引對應的文本塊,并將它們作為上下文提供給LLM Prompt。
? ? ? ?Prompt示例如下所示:
def question_answering(context, query):
prompt = f"""
Give the answer to the user query delimited by triple backticks ``{query}``\
using the information given in context delimited by triple backticks ``{context}``.\
If there is no relevant information in the provided context, try to answer yourself,
but tell user that you did not have any relevant context to base your answer on.
Be concise and output the answer of size less than 80 tokens.
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answer提高RAG pipeline最經濟的方式就是Prompt工程,可以參考OpenAI提示工程指南(https://platform.openai.com/docs/guides/prompt-engineering/strategy-write-clear-instructions)。
? ? ? ?現在我們將深入了解一下高級RAG技術的概述。下圖描述了高級RAG的核心步驟和算法。為了保證方案的可讀性,省略了一些邏輯循環和復雜的多步驟代理行為。
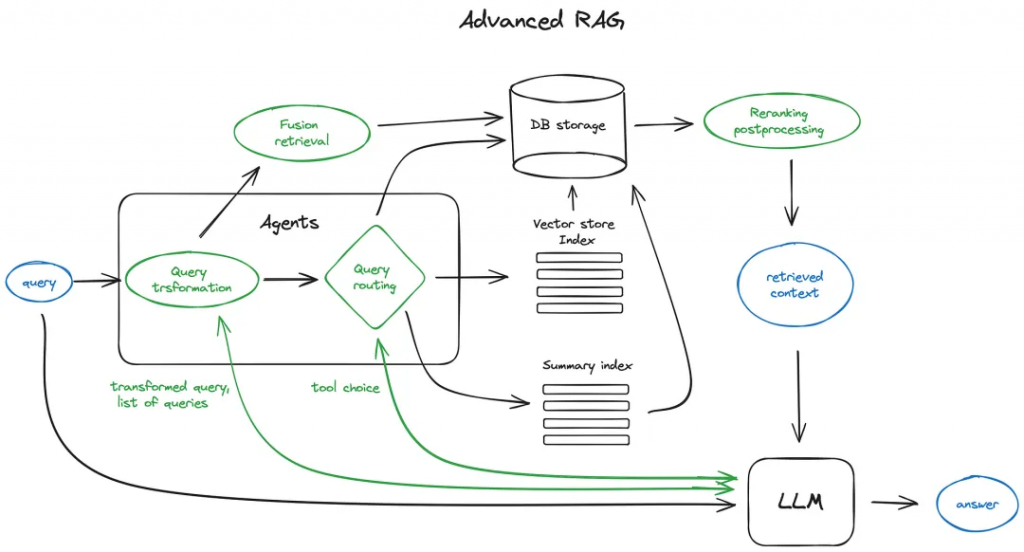
方案中的綠色元素是需要進一步討論的核心RAG技術,藍色元素是文本。上述方案也并沒有包括高級RAG的所有技術,例如,省略了各種上下文擴展方法——我們將在后面深入探討。
首先,我們要創建一個表示文檔內容的向量索引,然后在運行時會從這些向量索引中搜索與查詢向量最小余弦距離的向量。
2.1.1 Chunking
Transformer模型輸入序列長度一般是固定的,即使輸入上下文窗口較大,一個句子或幾個句子的向量也比幾頁文本上平均的向量能更好地表示其語義,因此,最好將原始文檔分為若干大小的塊,盡量不丟失其含義(將文本分為句子或段落,而不是將單個句子分為兩部分)。
? ? ? 分塊的大小是一個超參數,它取決于使用的嵌入模型以及在token的容量。標準的transformer編碼器模型(如基于BERT的sentence?transformer)最多可以使用512個tokens,OpenAI ada-002能夠處理更長的序列,比如8191個tokens,但是,這里需要對LLM在足夠的上下文中推理和有效地執行搜索進行權衡。在(https://www.pinecone.io/learn/chunking-strategies/)可以找到分塊大小選擇問題的研究。在LlamaIndex中,NodeParser類提供了一些高級選項,如定義自己的文本拆分器、元數據、節點/塊關系等。
2.1.2 Vectorisation
接下來需要選擇一個模型來嵌入分塊,優先選擇經過搜索優化的模型,比如bge-large(https://huggingface.co/BAAI/bge-large-en-v1.5)或E5 Embeddengs系列(https://huggingface.co/intfloat/multilingual-e5-large)。最新的模型可以查看MTEB排行榜(https://huggingface.co/spaces/mteb/leaderboard)。
對于分塊和向量化步驟end2end的實現,可以查看LlamaIndex中完整的示例(https://docs.llamaindex.ai/en/latest/module_guides/loading/ingestion_pipeline/root.html#)。
2.2.1 Vector store index
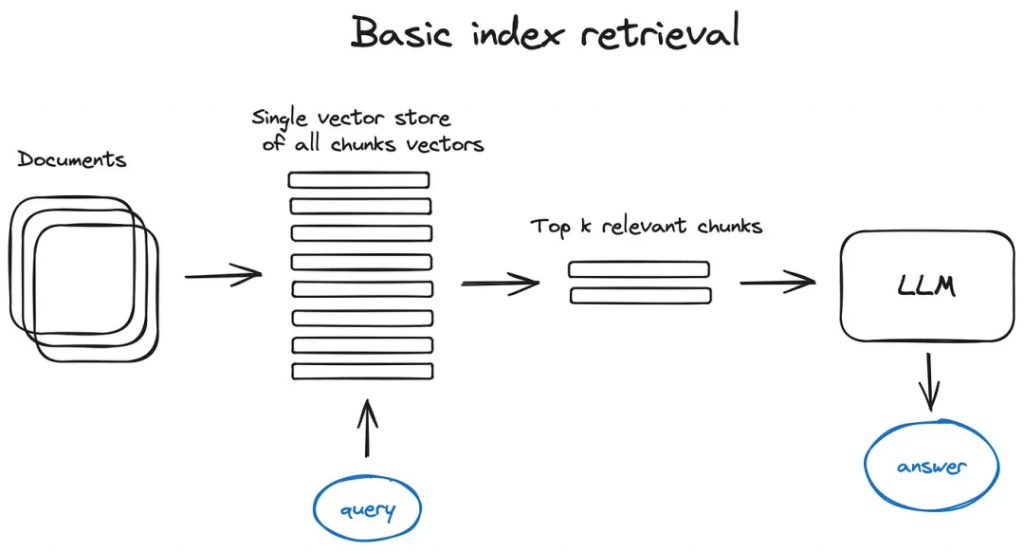
RAG管道的關鍵部分是搜索索引,它存儲我們在上一步中獲得的矢量化內容。最簡單的實現是使用一個平面索引——暴力計算查詢向量和所有塊向量之間的距離。
如果向量數量超過10000多個時,可以采用為高效檢索而優化的向量索引,如faiss、nmslib或annoy,使用一些近似近鄰實現,如clustring、trees或HNSW算法。當然還有一些托管解決方案,如OpenSearch或ElasticSearch和vector數據庫(比如Pinecone、Weaviate或Chroma)。
根據索引選擇、數據和搜索需要,還可以將元數據與向量一起存儲,然后使用元數據過濾器可以搜索例如:某些日期或源中的信息。
LlamaIndex支持許多向量存儲索引,但也支持其他更簡單的索引實現,如列表索引、樹索引和關鍵字表索引—我們將在融合檢索部分討論后者。
2.2.2 Hierarchical indices
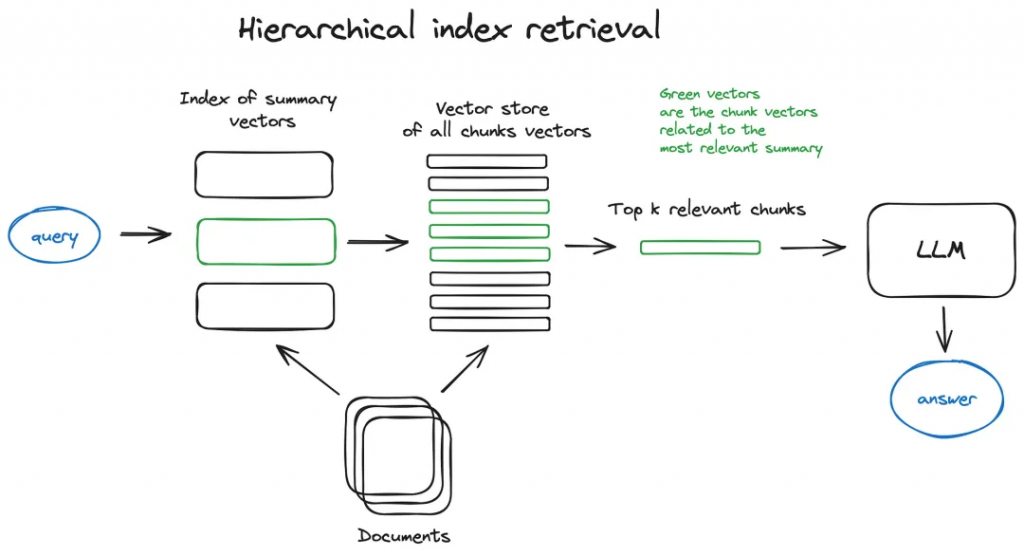
如果有許多文檔要從中檢索,需要能夠有效地在其中搜索,找到相關信息,并在最終的一個答案中綜合這些信息,并引用搜索來源。對于大型數據庫,一種有效的方法是創建兩個索引(一個由摘要組成,另一個由文檔塊組成),并分兩步進行搜索,首先通過摘要過濾出相關文檔,然后在該相關組中進行搜索。
2.2.3 Hypothetical Questions and HyDE
? ? ? ?另一種方法是要求LLM為每個分塊生成一個問題并將這些問題嵌入向量中,在運行時對問題向量的索引執行查詢搜索(將分塊向量替換為索引中的問題向量),然后在檢索后路由到原始文本區塊并將其作為上下文發送給LLM以獲得答案。這種方法提高了搜索質量,因為查詢和假設問題之間的語義相似度比實際塊更高。
? ? ? 還有一種稱為HyDE的反向邏輯方法—您要求LLM生成給定查詢的假設響應,然后使用其向量和查詢向量來提高搜索質量。
2.2.4 Context enrichment
? ? ? 這里的概念是檢索更小的塊以獲得更好的搜索質量,但要將周圍的上下文相加以供LLM推理。
有兩種選擇—通過圍繞較小檢索塊的語句擴展上下文,或者遞歸地將文檔拆分為若干較大的父塊(包含較小的子塊)。
a) Sentence Window Retrieval
在該方案中,文檔中的每個句子都被單獨嵌入,這為上下文余弦距離搜索提供了很高的查詢精度。
? ? ? 為了在獲取最相關的單個句子后更好地對所發現的上下文進行推理,我們在檢索到的句子前后對上下文窗口進行k個句子的擴展,然后將擴展后的上下文發送給LLM。

綠色部分是在索引中搜索時發現的嵌入句子,整個黑色+綠色段落喂給LLM,以擴大其上下文,同時對提供的查詢進行推理
b) Auto-merging Retriever (aka Parent Document Retriever)
? ? ? ?這里的想法非常類似于句子窗口檢索器——搜索更細粒度的信息片段,然后在將所述上下文提供給LLM進行推理之前擴展上下文窗口。文檔被分割成更小的子塊,引用更大的父塊。
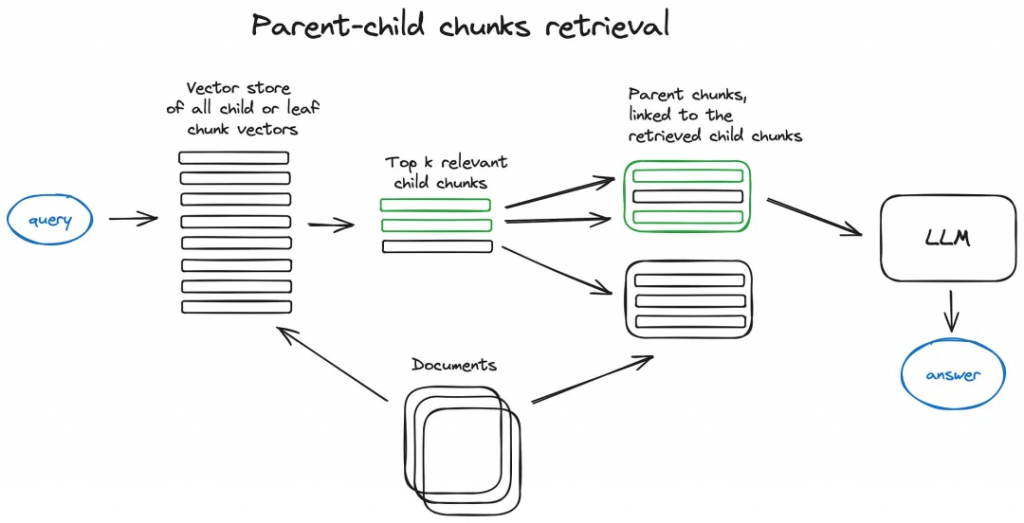
首先在檢索過程中獲取較小的塊,然后如果前k個檢索到的塊中有n個以上的塊鏈接到同一父節點(較大的塊),我們將替換由該父節點提供給LLM的上下文-工作方式類似于將幾個檢索到的塊自動合并到較大的父塊中,從而得到方法名稱。只需注意-搜索僅在子節點索引中執行。關于遞歸檢索器+節點引用,可以參考LlamaIndex教程(https://docs.llamaindex.ai/en/stable/examples/retrievers/recursive_retriever_nodes.html)。
2.2.5 Fusion retrieval or hybrid search
一個相對傳統的想法是,可以從兩個世界中取其精華-基于關鍵字的老式搜索-稀疏檢索算法,如tf-idf或搜索行業標準BM25-和現代語義或向量搜索,并將其組合到一個檢索結果。
? ? ? 這里唯一的技巧是將檢索到的結果與不同的相似性分數正確地結合起來——這個問題通常通過使用?Reciprocal Rank Fusion算法來解決,將檢索到的結果重新排序以獲得最終輸出。
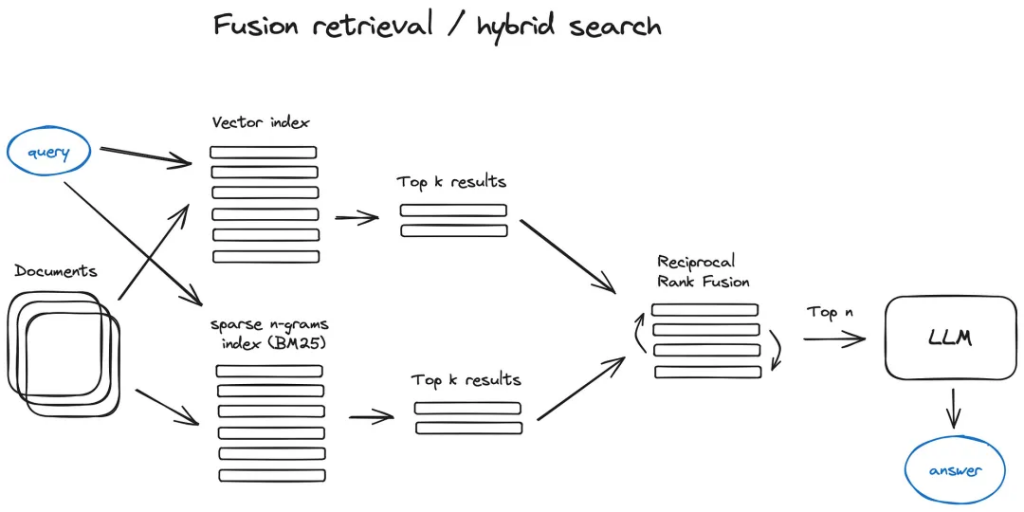
在LangChain中,這是在Ensemble Retriever類(https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble)中實現的,將用戶定義的檢索器列表(例如faiss向量索引和基于BM25的檢索器)結合起來,并使用RRF重新排序。
在LlamaIndex中,也是以非常類似的方式完成的,請參考:https://docs.llamaindex.ai/en/stable/examples/retrievers/reciprocal_rerank_fusion.html。
混合或融合搜索通常通過兩種互補的搜索算法相結合,同時考慮查詢與存儲文檔之間的語義相似度和關鍵字匹配,從而提供更好的檢索結果。
? ? ? ?根據上面章節,我們得到了檢索結果,但結果可能是錯誤的或者是冗余的。本小節我們繼續介紹一些后處理操作,比如過濾,重新排序或一些轉換。在LlamaIndex中,有各種可用的后處理器(https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/root.html),根據相似度得分、關鍵字、元數據過濾出結果,或者使用其他模型對其重新排序,比如LLM,sentence-transformer cross-encoder,重排序端點或者基于元數據,比如日期。常見的方法基本上都可以。
這是將檢索到的上下文提供給LLM以獲得結果答案之前的最后一步。
? ? ? ?現在是時候使用更復雜的RAG技術了,比如查詢轉換和路由,這兩種技術都涉及LLM,因此代表了代理行為——在RAG管道中涉及LLM推理的一些復雜邏輯。
? ? ? 查詢轉換是一系列使用LLM作為推理引擎修改用戶輸入以提高檢索質量的技術。
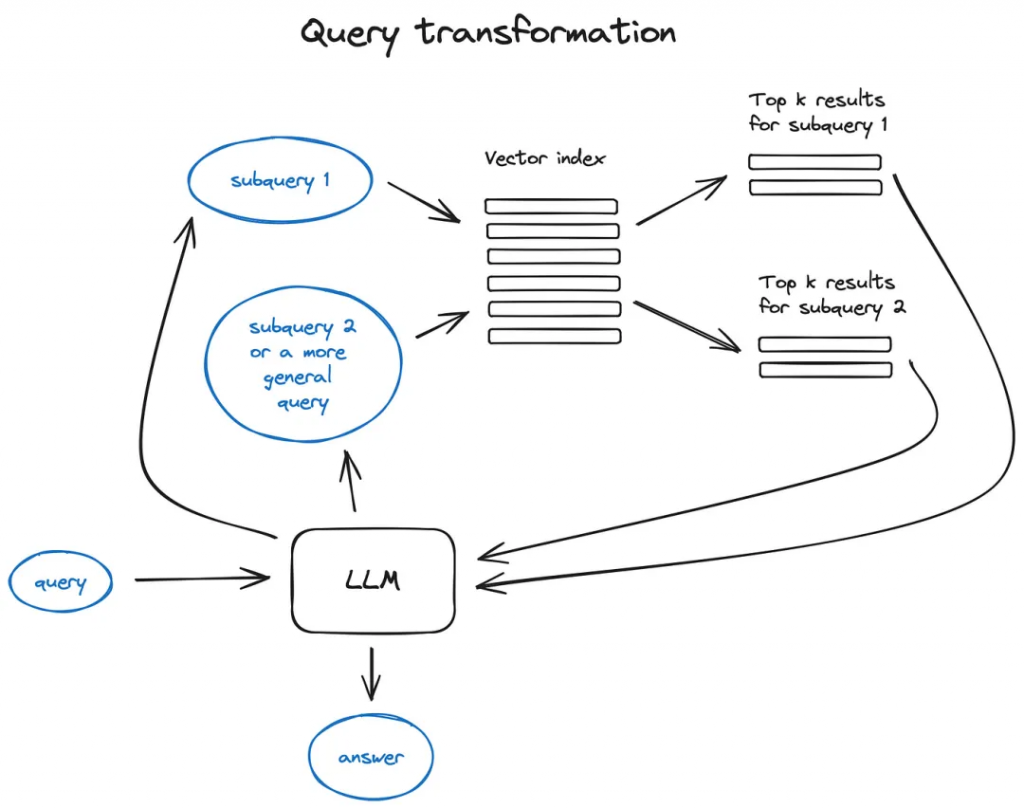
如果查詢很復雜,LLM可以將其分解為多個子查詢。例如,如果您詢問:
-“What framework has more stars on Github, Langchain or LlamaIndex?”,
而且,我們不太可能在語料庫中的某些文本中找到直接比較,因此將此問題分解為兩個子查詢是有意義的,前提是信息檢索更簡單、更具體:
-“How many stars does Langchain have on Github?”
-“How many stars does Llamaindex have on Github?”
? ? ? ?它們將并行執行,然后檢索到的上下文將組合在一個單獨的提示中,供LLM合成初始查詢的最終答案。這兩個庫都實現了這個功能——在Langchain中?使用Multi Query Retriever(https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever?ref=blog.langchain.dev),在Llamaindex中使用Sub Question Query Engine(https://docs.llamaindex.ai/en/stable/examples/query_engine/sub_question_query_engine.html)。
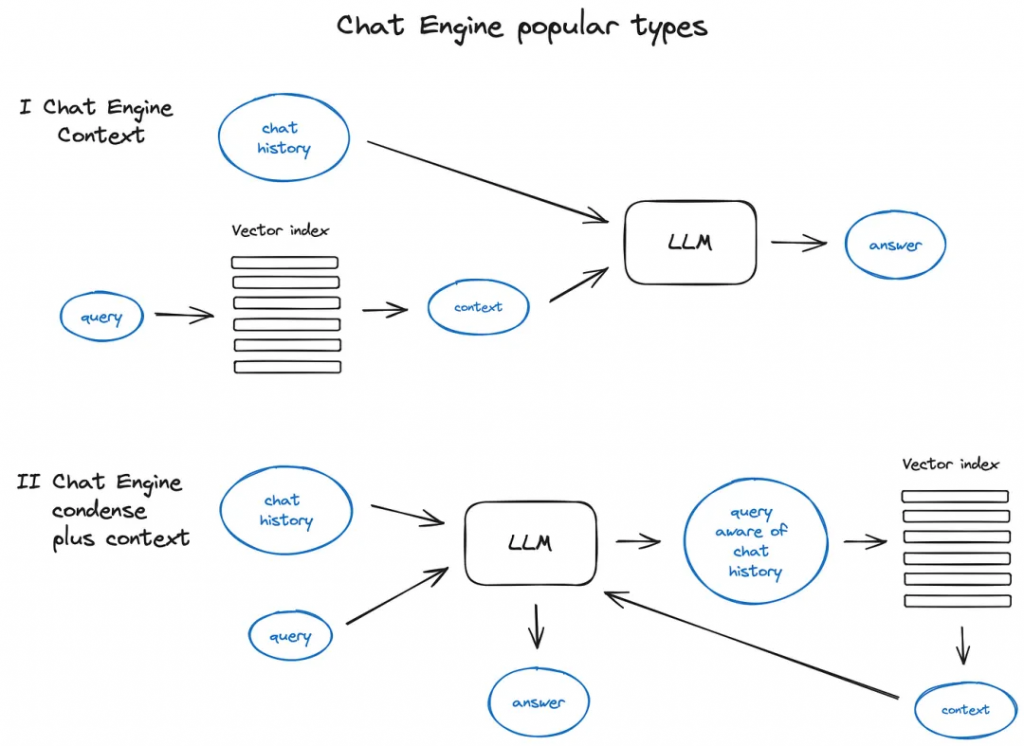
有時間,我們不僅僅要求RAG完成一個任務,也需要進行多輪對話聊天,它與經典的聊天機器人一樣可以考慮對話上下文。這需要跟蹤會話、回指或記錄歷史聊天記錄。該方法采用查詢壓縮技術,結合聊天環境和用戶查詢,解決了該問題。
? ? ? 通常,有幾種方法可以實現上述上下文壓縮-一種流行且相對簡單的ContextChatEngine(https://docs.llamaindex.ai/en/stable/examples/chat_engine/chat_engine_context.html),首先檢索與用戶查詢相關的上下文,然后將其與緩存中的聊天歷史一起輸入給LLM,以便LLM在生成下一個答案的同時考慮歷史聊天記錄。
? ? ? 更復雜一點的例子是CondensePlusContextMode(https://docs.llamaindex.ai/en/stable/examples/chat_engine/chat_engine_condense_plus_context.html)——在每個交互中,聊天歷史和最后一條消息被壓縮成一個新的查詢,然后將這個查詢建立索引再進行檢索,檢索到的上下文與原始用戶消息一起傳遞給LLM以生成答案。
? ? ? ?需要注意的是,LlamaIndex中還支持基于OpenAI代理的聊天引擎(https://docs.llamaindex.ai/en/stable/examples/chat_engine/chat_engine_openai.html),提供了更靈活的聊天模式,Langchain也支持OpenAI函數API(https://python.langchain.com/docs/modules/agents/agent_types/openai_multi_functions_agent)。
還有其他聊天引擎類型,比如ReAct Agent(https://docs.llamaindex.ai/en/stable/examples/chat_engine/chat_engine_react.html),我們將在第7節中介紹Agent。
? ? ? ?查詢路由是LLM支持的決策步驟,決定在給定用戶查詢的情況下接下來要做什么——通常是匯總、對某些數據索引執行搜索或嘗試多個不同的路由,然后在單個答案中綜合它們的輸出。
查詢路由器可以選擇一個索引或者數據存儲來發送用戶的查詢。或者有多個數據源,例如,經典向量存儲和圖形數據庫或關系數據庫,或者您有一個索引層次結構—對于多文檔存儲來說,一個非常經典的例子是摘要索引和另一個文檔塊向量索引。
? ? ? ?定義查詢路由器包括設置它可以做出的選擇。通過LLM調用執行路由選項的選擇,以預定義格式返回其結果,將查詢路由到給定的索引,或者,如果我們采用不相關行為,則路由到子鏈或甚至其他代理,如下面的多文檔代理方案所示。
LlamaIndex(https://docs.llamaindex.ai/en/stable/module_guides/querying/router/root.html)和LangChain(https://python.langchain.com/docs/expression_language/how_to/routing?ref=blog.langchain.dev)都支持查詢路由器。
? ? ? 代理(由Langchain和LlamaIndex支持)幾乎自第一個LLM API發布以來就一直存在——其思想是提供一個LLM,能夠推理,具有一組工具和要完成的任務。這些工具可能包括一些確定性函數,比如任何代碼函數、外部API甚至其他代理——這種LLM鏈接思想就是LangChain得名的地方。
? ? ? ?代理本身是一個龐大的東西,在RAG概述中不可能對這個主題進行足夠深入的研究,因此將繼續介紹基于代理的多文檔檢索案例,在OpenAI助手站稍作停留,因為這是一個相對較新的東西,在最近的OpenAI 的 dev conference as GPTs中介紹(https://openai.com/blog/new-models-and-developer-products-announced-at-devday)的。
? ? ? ?OpenAI助手(https://platform.openai.com/docs/assistants/overview)基本上已經實現了我們以前在開源中使用的LLM所需的許多工具,比如聊天歷史、知識存儲、文檔上傳接口,以及最重要的函數調用API。后者提供了將自然語言轉換為對外部工具或數據庫查詢的API調用的功能。
? ? ? 在LlamaIndex中,有一個OpenAIgent類(https://docs.llamaindex.ai/en/stable/examples/agent/openai_agent.html)將這種高級邏輯與ChatEngine和QueryEngine類相結合,提供基于知識和上下文感知的聊天,以及在一次會話中調用多個OpenAI函數的能力,這真正帶來了智能代理行為。
讓我們看一看多文檔代理方案(https://docs.llamaindex.ai/en/stable/examples/agent/multi_document_agents.html)——一個非常復雜的設置,包括在每個文檔上初始化一個代理(OpenAIAgent(https://docs.llamaindex.ai/en/stable/examples/agent/openai_agent.html)),能夠進行文檔摘要和經典的QA機制,以及一個頂級代理,負責將查詢路由到文檔代理并進行最終答案合成。
每個文檔代理都有兩個工具—向量存儲索引和摘要索引,并根據路由查詢決定使用哪個工具。對于頂級代理,所有文檔代理都是工具。
? ? ? ?該方案展示了一種先進的RAG體系結構,每個代理都會做出大量的路由決策。這種方法的好處是能夠比較不同的解決方案或實體,在不同的文檔及其摘要中進行描述,以及經典的單文檔摘要和QA機制—這基本上涵蓋了與文檔用例集合最頻繁的聊天。

??這樣一個復雜方案的缺點可以從圖中猜測出來——由于在代理中使用LLM進行多次來回迭代,所以有點慢。以防萬一,LLM調用始終是RAG管道中最長的操作-設計優化了搜索速度。因此,對于大型多文檔存儲,建議考慮對該方案進行一些簡化,使其具有可擴展性。
2.8 Response synthesiser
這是任何RAG管道的最后一步——根據檢索的所有上下文和初始用戶查詢生成答案。
? ? ? ?最簡單的方法是將所有獲取的上下文(高于某個相關閾值)與查詢一起串聯并同時提供給LLM。
? ? ? ?但是,還有其他更復雜的選項涉及多個LLM調用,以優化檢索到的上下文并生成更好的答案。
響應綜合的主要方法有:
1、通過逐塊向LLM發送檢索到的上下文,迭代地細化答案;
2、總結檢索到的上下文以適應提示;
3、根據不同的上下文塊生成多個答案,并將其串聯或匯總。
有關更多詳細信息,請查看響應合成器模塊文檔(https://docs.llamaindex.ai/en/stable/module_guides/querying/response_synthesizers/root.html)。
? ? ? ?前面兩章介紹了直接使用現有模型來完成RAG,那么有時候底座模型的性能未必會滿足需求,這時可以考慮對其進行微調。RAG管道中主要涉及到兩個模型,分別是負責嵌入質量和上下文檢索質量的Transformer編碼器,另一個是負責最好地使用所提供的上下文來回答用戶查詢的LLM——幸運的是,后者是一個很好的少量學習者。
? ? ? 現在的一大優勢是可以使用GPT-4等高端LLM生成高質量的合成數據集。
需要注意的是:使用專業研究團隊訓練開源模型收集、清理和驗證的大型數據集,并使用小型合成數據集進行快速微調,可能會降低模型的通用能力。
在LlamaIndex notebook(https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding.html)中測試了bge-large-en-v1.5(撰寫本文時MTEB排行榜的前4名)的微調所帶來的性能提升,結果顯示檢索質量提高了2%。
另一個很好的選擇是,如果您不完全信任基本編碼器,那么可以使用交叉編碼器對檢索到的結果進行重新排序。它的工作方式如下:將查詢和前k個檢索到的文本塊傳遞給交叉編碼器,并用SEP token分隔,然后對其進行微調,將相關塊輸出1,將不相關塊輸出0。這里有個例子(https://docs.llamaindex.ai/en/latest/examples/finetuning/cross_encoder_finetuning/cross_encoder_finetuning.html#),結果顯示,對交叉編碼器微調,評分提高了4%。
? ? ? ?最近OpenAI開始提供LLM FineTunning API(https://platform.openai.com/docs/guides/fine-tuning),LlamaIndex有一個關于在RAG設置中微調GPT-3.5-turbo的教程(https://docs.llamaindex.ai/en/stable/examples/finetuning/openai_fine_tuning.html),可以“蒸餾”一些GPT-4知識。這里的想法是獲取一個文檔,使用GPT-3.5-turbo生成許多問題,然后使用GPT-4根據文檔內容生成這些問題的答案(構建GPT4支持的RAG管道),然后在該問答對數據集上微調GPT-3.5-turbo。用于RAG管道評估的ragas框架(https://docs.ragas.io/en/latest/index.html)顯示忠實性度量增加了5%,這意味著經過微調的GPT 3.5-turbo模型比原始模型更好地利用了提供的上下文來生成其答案。
? ? ? 最近Meta AI的一篇論文《RA-DIT: Retrieval Augmented Dual Instruction Tuning》提出了一種在查詢、上下文和答案的三元組上同時微調LLM和檢索器的方法,原論文采用一個雙編碼器結構,實現細節可以參考:https://docs.llamaindex.ai/en/stable/examples/finetuning/knowledge/finetune_retrieval_aug.html#fine-tuning-with-retrieval-augmentation。該技術用于通過微調API和Llama2開源模型來微調OpenAI LLMs,從而使知識密集型任務度量增加了約5%(相比于使用RAG的Llama2 65B),并使常識推理任務增加了兩個百分點。
有幾個RAG系統性能評估框架,他們思路類似,都采用以下指標來進行評估:比如總體答案相關性、答案有根據性、可信度和檢索到的上下文相關性。
如前一節所述,Ragas使用信度和答案相關性作為生成的答案質量度量,并使用經典上下文精度P和召回率R作為RAG方案的檢索部分。
在Andrew NG、LlamaIndex和評估框架Truelens(https://github.com/truera/trulens/tree/main)最近發布的一個大型短期課程“構建和評估高級RAG(https://learn.deeplearning.ai/building-evaluating-advanced-rag/)”中,他們提出了RAG三元組——檢索到的與查詢相關的上下文、有根據性(所提供的上下文支持LLM答案的多少)和與查詢相關的答案。
? ? ? ?關鍵且最可控的度量是檢索到的上下文相關性——基本上,上面描述的高級RAG管道的第1–7部分以及編碼器和Ranker微調部分旨在改進此度量,而第8部分和LLM微調則側重于答案相關性和基礎性。
? ? ? ?這里(https://github.com/run-llama/finetune-embedding/blob/main/evaluate.ipynb)可以找到一個非常簡單的檢索器評估Pipeline的例子,并將其應用于編碼器微調部分。OpenAI cookbook(https://github.com/openai/openai-cookbook/blob/main/examples/evaluation/Evaluate_RAG_with_LlamaIndex.ipynb)中展示了一種更高級的方法,該方法不僅考慮了命中率,而且還考慮了平均倒數秩(一種常見的搜索引擎度量)以及生成的答案度量(如忠實度和相關性)。
LangChain有一個非常高級的評估框架LangSmith(https://docs.smith.langchain.com/),其中可以實現定制的評估器,并監視RAG管道中的運行狀況,以使系統更加透明。
在LlamaIndex中,有一個rag_evaluator llama pack包(https://github.com/run-llama/llama-hub/tree/dac193254456df699b4c73dd98cdbab3d1dc89b0/llama_hub/llama_packs/rag_evaluator),它提供了一個快速工具,可以使用公共數據集評估管道。
試圖勾勒出RAG的核心算法方法,并舉例說明其中的一些方法,希望這可能會激發一些新的想法,嘗試在RAG管道中,或將一些系統引入到今年發明的各種各樣的技術中——對我來說,2023年是ML迄今為止最激動人心的一年。
? ? ?還有很多其他的東西需要考慮,比如基于web搜索的RAG(由LlamaIndex、webLangChain等開發的RAG),深入研究代理架構(以及最近在游戲中的OpenAI stake),以及一些關于LLMs長期記憶的想法。
? ? ? ?對于RAG系統來說,除了答案的相關性和忠實性之外,主要的生產挑戰是速度,特別是當使用更靈活的基于代理的方案時。ChatGPT和大多數其他助手使用的這種流式功能不是一種隨機的cyberpunk風格,而只是一種縮短感知答案生成時間的方法。這就是為什么我看到了一個非常光明的未來,較小的LLM和最近發布的Mixtral和Phi-2是引導我們在這個方向前進。
參考文獻:
[1]?https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6?source=email-c63e4493b83d-1703617670645-digest.reader-98111c9905da-04d193d8fec6—-0-98——————585a2b75_5c50_49b0_a73f_79ae0baec16e-1
本文章轉載微信公眾號@ArronAI







