
如何快速實現REST API集成以優化業務流程
如果您已經知道如何使用 GPT 3.5 模型下的 OpenAI API 以及如何使用 Streamlit 設計 Web 應用程序,建議您跳過第 1 部分和第 2 部分以節省閱讀時間。
如果您已經擁有一個 OpenAI API 密鑰,請堅持使用它而不是創建一個新密鑰。但是,如果您是 OpenAI 新手,請注冊一個新帳戶并在您的帳戶菜單中找到以下頁面:
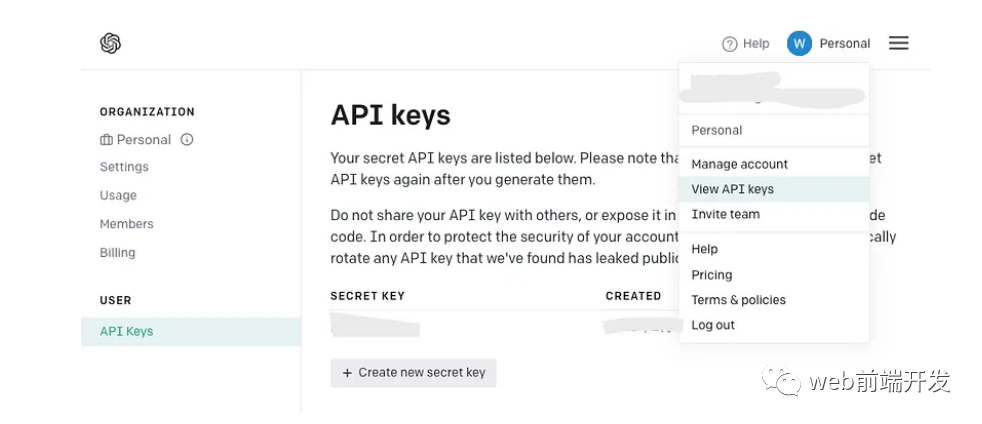
生成 API 密鑰后,請記住它只會顯示一次,因此請確保將其復制到安全的地方以備將來使用。
目前GPT-4.0剛剛發布,該模型的API還沒有完全發布,所以我將介紹開發仍然是GPT 3.5模型,它足以完成我們的AI語音Chatbot演示。現在讓我們看一下來自 OpenAI 的最簡單的演示,以了解 ChatCompletion API(或稱為 gpt-3.5 API 或 ChatGPT API)的基本定義:安裝包:
!pip install opena如果您之前從 OpenAI 開發了一些遺留 GPT 模型,您可能必須通過 pip 升級您的包:
!pip install --upgrade openai創建并發送提示:
import openai
complete = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)接收文本響應:
message=complete.choices[0].message.content因為 GPT 3.5 API 是基于聊天的文本完成 API,所以請確保 ChatCompletion 請求的消息正文包含對話歷史記錄作為上下文,您希望模型參考更上下文相關的響應來響應您的當前請求。為了實現此功能,消息體的列表對象應按以下順序組織:
我們將繼續使用強大的 Streamlit 庫來構建 Web 應用程序。

Streamlit 是一個開源框架,它使數據科學家和開發人員能夠快速構建和共享用于機器學習和數據科學項目的交互式 Web 應用程序。它還提供了一堆小部件,只需要一行 python 代碼即可創建,如 st.table(…)。
如果您不太擅長 Web 開發并且不愿意像我一樣構建大型商業應用程序,Streamlit 始終是您的最佳選擇之一,因為它幾乎不需要 HTML 方面的專業知識。
讓我們看一個構建 Streamlit Web 應用程序的快速示例:
安裝包:
!pip install streamlit創建一個 Python 文件“demo.py”:
import streamlit as st
st.write("""
# My First App
Hello *world!*
""")在本地機器或遠程服務器上運行:
!python -m streamlit run demo.py打印此輸出后,您可以通過列出的地址和端口訪問您的網站:
You can now view your Streamlit app in your browser.
Network URL: http://xxx.xxx.xxx.xxx:8501
External URL: http://xxx.xxx.xxx.xxx:8501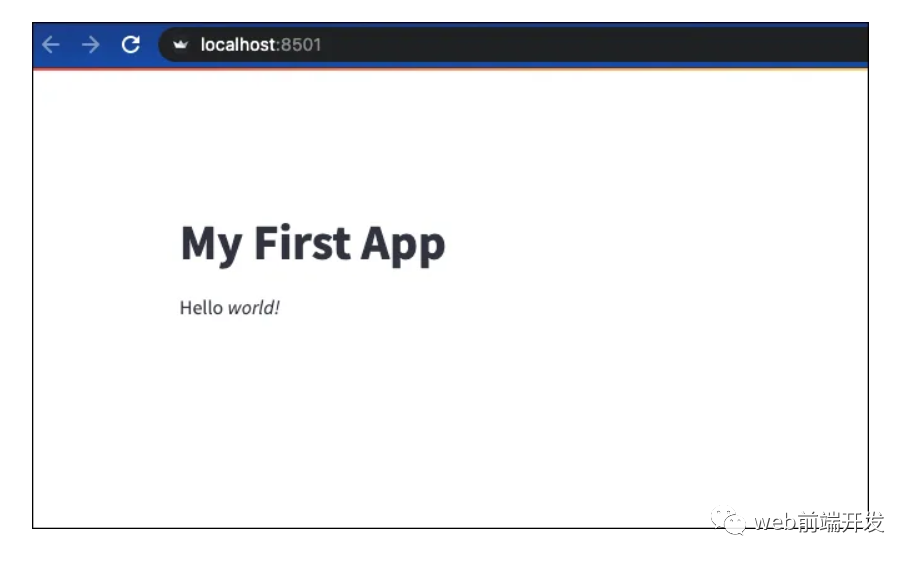
Streamlit 提供的所有小部件的用法可以在其文檔頁面中找到:https://docs.streamlit.io/library/api-reference
此 AI 語音聊天機器人的主要功能之一是它能夠識別用戶語音并生成我們的 ChatCompletion API 可用作輸入的適當文本。
OpenAI 的 Whisper API 提供的高質量語音識別是一個很好的選擇,但它是有代價的。或者,來自 Javascript 的免費 Web Speech API 提供可靠的多語言支持和令人印象深刻的性能。
雖然開發 Python 項目似乎與定制的 Javascript 不兼容,但不要害怕!在下一部分中,我將介紹一種在 Python 程序中調用 Javascript 代碼的簡單技術。
不管怎樣,讓我們看看如何使用 Web Speech API 快速開發語音轉文本演示。您可以找到它的文檔(地址:https://wicg.github.io/speech-api/)。
語音識別的實現可以很容易地完成,如下所示。
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
recognition.start();通過方法 webkitSpeechRecognition() 初始化識別對象后,需要定義一些有用的屬性。continuous 屬性表示您是否希望 SpeechRecognition 函數在語音輸入的一種模式處理成功完成后繼續工作。
我將其設置為 false,因為我希望語音聊天機器人能夠以穩定的速度根據用戶語音輸入生成每個答案。
設置為 true 的 interimResults 屬性將在用戶語音期間生成一些中間結果,以便用戶可以看到從他們的語音輸入輸出的動態消息。
lang 屬性將設置請求識別的語言。請注意,如果它在代碼中是未設置,則默認語言將來自 HTML 文檔根元素和關聯的層次結構,因此在其系統中使用不同語言設置的用戶可能會有不同的體驗。
識別對象有多個事件,我們使用 .onresult 回調來處理來自中間結果和最終結果的文本生成結果。
recognition.onresult = function (e) {
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
}從用戶界面的定義來看,我們想設計一個按鈕來啟動我們在上一節中已經用 Javascript 實現的語音識別。

Streamlit 庫不支持自定義 JS 代碼,所以我們引入了 Bokeh。Bokeh 庫是另一個強大的 Python 數據可視化工具。可以支持我們的演示的最佳部分之一是嵌入自定義 Javascript 代碼,這意味著我們可以在 Bokeh 的按鈕小部件下運行我們的語音識別腳本。
為此,我們應該安裝 Bokeh 包。為了兼容后面會提到的streamlit-bokeh-events庫,Bokeh的版本應該是2.4.2:
!pip install bokeh==2.4.2導入按鈕和 CustomJS:
from bokeh.models.widgets import Button
from bokeh.models import CustomJS創建按鈕小部件:
spk_button = Button(label='SPEAK', button_type='success')定義按鈕點擊事件:
spk_button.js_on_event("button_click", CustomJS(code="""
...js code...
"""))定義了.js_on_event()方法來注冊spk_button的事件。
在這種情況下,我們注冊了“button_click”事件,該事件將在用戶單擊后觸發由 CustomJS() 方法嵌入的 JS 代碼塊…js 代碼…的執行。
Streamlit_bokeh_event
speak 按鈕及其回調方法實現后,下一步是將 Bokeh 事件輸出(識別的文本)連接到其他功能塊,以便將提示文本發送到 ChatGPT API。
幸運的是,有一個名為“Streamlit Bokeh Events”的開源項目專為此目的而設計,它提供與 Bokeh 小部件的雙向通信。你可以在這里(地址:https://github.com/ash2shukla/streamlit-bokeh-events)找到它的 GitHub 頁面。
這個庫的使用非常簡單。首先安裝包:
!pip install streamlit-bokeh-events通過 streamlit_bokeh_events 方法創建結果對象。
result = streamlit_bokeh_events(
bokeh_plot = spk_button,
events="GET_TEXT,GET_ONREC,GET_INTRM",
key="listen",
refresh_on_update=False,
override_height=75,
debounce_time=0)使用 bokeh_plot 屬性來注冊我們在上一節中創建的 spk_button。使用 events 屬性來標記多個自定義的 HTML 文檔事件
我們可以使用 JS 函數 document.dispatchEvent(new CustomEvent(…)) 來生成事件,例如 GET_TEXT 和 GET_INTRM 事件:
spk_button.js_on_event("button_click", CustomJS(code="""
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
recognition.start();
}
"""))并且,檢查事件 GET_INTRM 處理的 result.get() 方法,例如:
tr = st.empty()
if result:
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", result.get("GET_INTRM"))這兩個代碼片段表明,當用戶正在講話時,任何臨時識別文本都將顯示在 Streamlit text_area 小部件上:
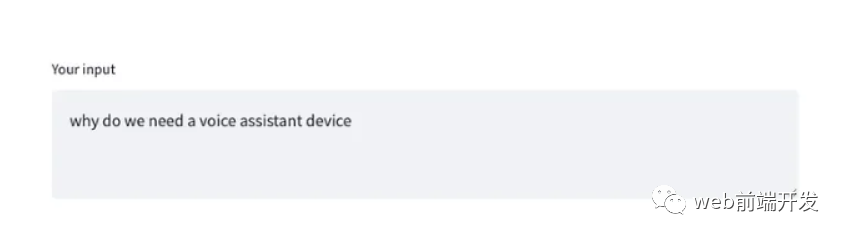
提示請求完成,GPT-3.5模型通過ChatGPT API生成響應后,我們通過Streamlit st.write()方法將響應文本直接顯示在網頁上。
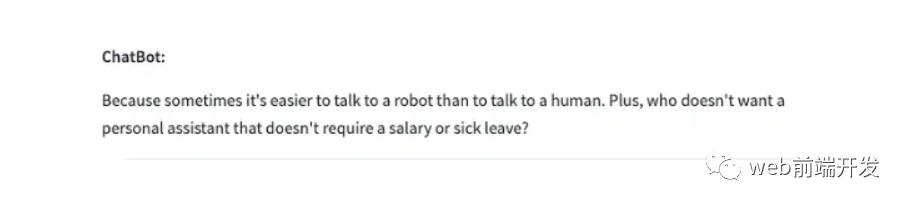
但是,我們需要將文本轉換為語音,這樣我們的 AI 語音 Chatbot 的雙向功能才能完全完成。
有一個名為“gTTS”的流行 Python 庫能夠完美地完成這項工作。在與谷歌翻譯的文本轉語音 API 接口后,它支持多種格式的語音數據輸出,包括 mp3 或 stdout。你可以在這里(地址:https://github.com/pndurette/gTTS/blob/main/docs/index.rst)找到它的 GitHub 頁面。
只需幾行代碼即可完成轉換。首先安裝包:
!pip install gTTS在這個演示中,我們不想將語音數據保存到文件中,所以我們可以調用 BytesIO() 來臨時存儲語音數據:
sound = BytesIO()
tts = gTTS(output, lang='en', tld='com')
tts.write_to_fp(sound)輸出的是要轉換的文本字符串,你可以根據自己的喜好,通過tld從不同的google域中選擇不同的語言by lang。例如,您可以設置 tld=’co.uk’ 以生成英式英語口音。
然后,通過 Streamlit 小部件創建一個像樣的音頻播放器:
st.audio(sound)要整合上述所有模塊,我們應該完成完整的功能:
請找到完整的演示代碼供您參考:
import streamlit as st
from bokeh.models.widgets import Button
from bokeh.models import CustomJS
from streamlit_bokeh_events import streamlit_bokeh_events
from gtts import gTTS
from io import BytesIO
import openai
openai.api_key = '{Your API Key}'
if 'prompts' not in st.session_state:
st.session_state['prompts'] = [{"role": "system", "content": "You are a helpful assistant. Answer as concisely as possible with a little humor expression."}]
def generate_response(prompt):
st.session_state['prompts'].append({"role": "user", "content":prompt})
completion=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = st.session_state['prompts']
)
message=completion.choices[0].message.content
return message
sound = BytesIO()
placeholder = st.container()
placeholder.title("Yeyu's Voice ChatBot")
stt_button = Button(label='SPEAK', button_type='success', margin = (5, 5, 5, 5), width=200)
stt_button.js_on_event("button_click", CustomJS(code="""
var value = "";
var rand = 0;
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'start'}));
recognition.onspeechstart = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'running'}));
}
recognition.onsoundend = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.onresult = function (e) {
var value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
}
recognition.onerror = function(e) {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.start();
"""))
result = streamlit_bokeh_events(
bokeh_plot = stt_button,
events="GET_TEXT,GET_ONREC,GET_INTRM",
key="listen",
refresh_on_update=False,
override_height=75,
debounce_time=0)
tr = st.empty()
if 'input' not in st.session_state:
st.session_state['input'] = dict(text='', session=0)
tr.text_area("**Your input**", value=st.session_state['input']['text'])
if result:
if "GET_TEXT" in result:
if result.get("GET_TEXT")["t"] != '' and result.get("GET_TEXT")["s"] != st.session_state['input']['session'] :
st.session_state['input']['text'] = result.get("GET_TEXT")["t"]
tr.text_area("**Your input**", value=st.session_state['input']['text'])
st.session_state['input']['session'] = result.get("GET_TEXT")["s"]
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", value=st.session_state['input']['text']+' '+result.get("GET_INTRM"))
if "GET_ONREC" in result:
if result.get("GET_ONREC") == 'start':
placeholder.image("recon.gif")
st.session_state['input']['text'] = ''
elif result.get("GET_ONREC") == 'running':
placeholder.image("recon.gif")
elif result.get("GET_ONREC") == 'stop':
placeholder.image("recon.jpg")
if st.session_state['input']['text'] != '':
input = st.session_state['input']['text']
output = generate_response(input)
st.write("**ChatBot:**")
st.write(output)
st.session_state['input']['text'] = ''
tts = gTTS(output, lang='en', tld='com')
tts.write_to_fp(sound)
st.audio(sound)
st.session_state['prompts'].append({"role": "user", "content":input})
st.session_state['prompts'].append({"role": "assistant", "content":output})輸入后:
!python -m streamlit run demo_voice.py您最終會在網絡瀏覽器上看到一個簡單但智能的語音聊天機器人。
請注意:不要忘記在彈出請求時允許網頁訪問您的麥克風和揚聲器。
就是這樣,一個簡單聊天機器人就完成了。
最后,希望您能在本文中找到有用的東西,感謝您的閱讀!
文章轉自微信公眾號@web前端開發







