
如何快速實現REST API集成以優化業務流程
注:本文主要探討分類任務的類別不均衡,回歸任務的樣本不均衡詳見《Delving into Deep Imbalanced Regression》
很多時候我們遇到樣本不均衡問題時,很直接的反應就是去“打破”這種不平衡。但是樣本不均衡有什么影響?有必要去解決嗎?
具體舉個例子,在一個欺詐識別的案例中,好壞樣本的占比是1000:1,而如果我們直接拿這個比例去學習模型的話,因為扔進去模型學習的樣本大部分都是好的,就很容易學出一個把所有樣本都預測為好的模型,而且這樣預測的概率準確率還是非常高的。而模型最終學習的并不是如何分辨好壞,而是學習到了”好 遠比 壞的多“這樣的先驗信息,憑著這個信息把所有樣本都判定為“好”就可以了。這樣就背離了模型學習去分辨好壞的初衷了。
所以,樣本不均衡帶來的根本影響是:模型會學習到訓練集中樣本比例的這種先驗性信息,以致于實際預測時就會對多數類別有側重(可能導致多數類精度更好,而少數類比較差)。如下圖(示例代碼請見:github.com/aialgorithm),類別不均衡情況下的分類邊界會偏向“侵占”少數類的區域。更重要的一點,這會影響模型學習更本質的特征,影響模型的魯棒性。
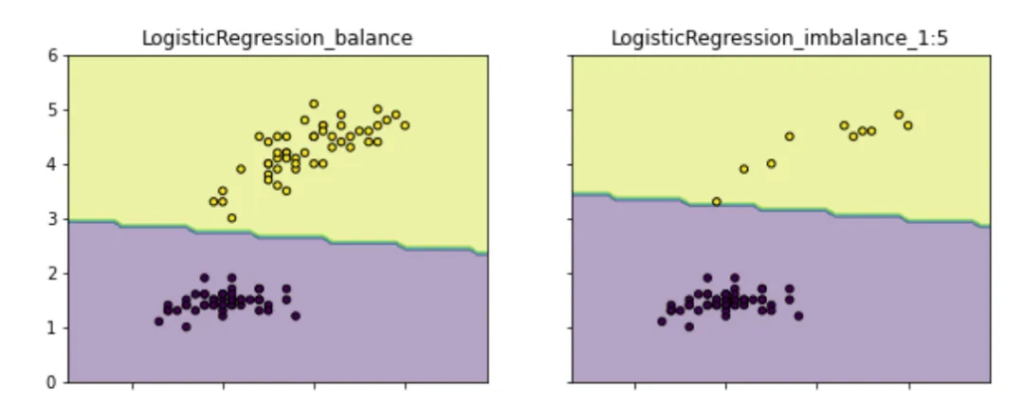
總結一下也就是,我們通過解決樣本不均衡,可以減少模型學習樣本比例的先驗信息,以獲得能學習到辨別好壞本質特征的模型。
從分類效果出發,通過上面的例子可知,不均衡對于分類結果的影響不一定是不好的,那什么時候需要解決樣本不均衡?
基本上,在學習任務有些難度的前提下,不均衡解決方法可以歸結為:通過某種方法使得不同類別的樣本對于模型學習中的Loss(或梯度)貢獻是比較均衡的。以消除模型對不同類別的偏向性,學習到更為本質的特征。本文從數據樣本、模型算法、目標(損失)函數、評估指標等方面,對個中的解決方法進行探討。
最直接的處理方式就是樣本數量的調整了,常用的可以:
數據增強(Data Augmentation)是在不實質性的增加數據的情況下,從原始數據加工出更多數據的表示,提高原數據的數量及質量,以接近于更多數據量產生的價值,從而提高模型的學習效果(其實也是過采樣的方法的一種。具體介紹及代碼可見【數據增強】)。如下列舉常用的方法:
樣本變換數據增強即采用預設的數據變換規則進行已有數據的擴增,包含單樣本數據增強和多樣本數據增強。
單樣本增強(主要用于圖像):主要有幾何操作、顏色變換、隨機擦除、添加噪聲等方法產生新的樣本,可參見imgaug開源庫。

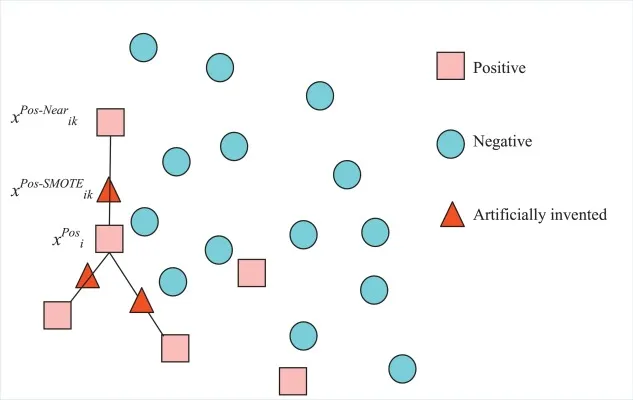
多樣本增強:是通過組合及轉換多個樣本,主要有Smote類(可見imbalanced-learn.org/stable/references/over_sampling.html)、SamplePairing、Mixup等方法在特征空間內構造已知樣本的鄰域值樣本。
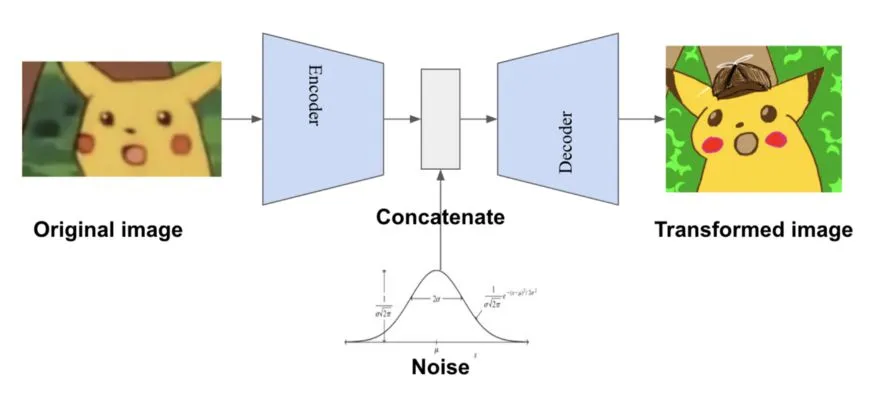
生成模型如變分自編碼網絡(Variational Auto-Encoding network, VAE)和生成對抗網絡(Generative Adversarial Network, GAN),其生成樣本的方法也可以用于數據增強。這種基于網絡合成的方法相比于傳統的數據增強技術雖然過程更加復雜, 但是生成的樣本更加多樣。
數據樣本層面解決不均衡的方法,需要關注的是:
損失函數層面主流的方法也就是常用的代價敏感學習(cost-sensitive),為不同的分類錯誤給予不同懲罰力度(權重),在調節類別平衡的同時,也不會增加計算復雜度。如下常用方法:
這最常用也就是scikit模型的’class weight‘方法,If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform.,class weight可以為不同類別的樣本提供不同的權重(少數類有更高的權重),從而模型可以平衡各類別的學習。如下圖通過為少數類做更高的權重,以避免決策偏重多數類的現象(類別權重除了設定為balanced,還可以作為一個超參搜索。示例代碼請見github.com/aialgorithm):
clf2?=?LogisticRegression(class_weight={0:1,1:10})??#?代價敏感學習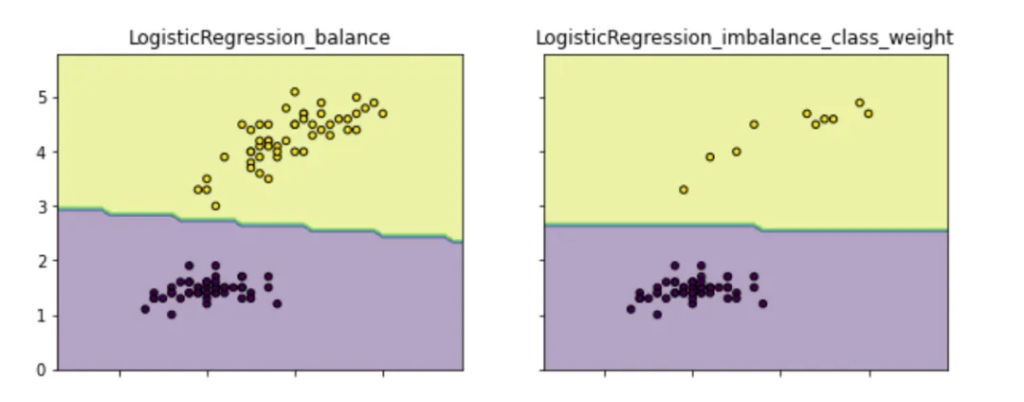
In this work, we first point out that the class imbalance can be summarized to the imbalance in difficulty and the imbalance in difficulty can be summarized to the imbalance in gradient norm distribution.
–原文可見《Gradient Harmonized Single-stage Detector》
上文的大意是,類別的不平衡可以歸結為難易樣本的不平衡,而難易樣本的不平衡可以歸結為梯度的不平衡。按照這個思路,OHEM和Focal loss都做了兩件事:難樣本挖掘以及類別的平衡。(另外的有 GHM、 PISA等方法,可以自行了解)
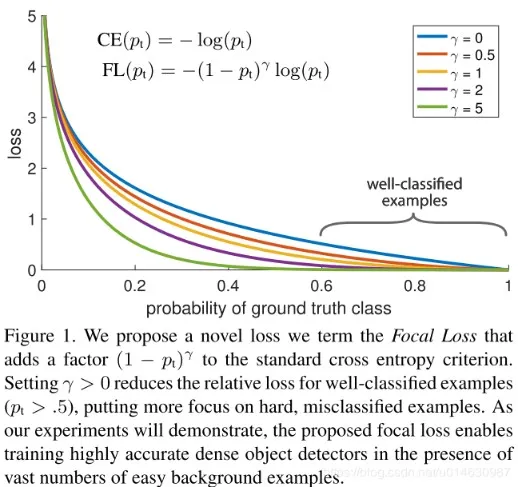
模型方面主要是選擇一些對不均衡比較不敏感的模型,比如,對比邏輯回歸模型(lr學習的是全量訓練樣本的最小損失,自然會比較偏向去減少多數類樣本造成的損失),決策樹在不平衡數據上面表現相對好一些,樹模型是按照增益遞歸地劃分數據(如下圖),劃分過程考慮的是局部的增益,全局樣本是不均衡,局部空間就不一定,所以比較不敏感一些(但還是會有偏向性)。相關實驗可見arxiv.org/abs/2104.02240。
解決不均衡問題,更為優秀的是基于采樣+集成樹模型等方法,可以在類別不均衡數據上表現良好。
這類方法簡單來說,通過重復組合少數類樣本與抽樣的同樣數量的多數類樣本,訓練若干的分類器進行集成學習。
通常,在數據集噪聲較小的情況下,可以用BalanceCascade,可以用較少的基分類器數量得到較好的表現(基于串行的集成學習方法,對噪聲敏感容易過擬合)。噪聲大的情況下,可以用EasyEnsemble,基于串行+并行的集成學習方法,bagging多個Adaboost過程可以抵消一些噪聲影響。此外還有RUSB、SmoteBoost、balanced RF等其他集成方法可以自行了解。
類別不平衡很極端的情況下(比如少數類只有幾十個樣本),將分類問題考慮成異常檢測(anomaly detection)問題可能會更好。
異常檢測是通過數據挖掘方法發現與數據集分布不一致的異常數據,也被稱為離群點、異常值檢測等等。無監督異常檢測按其算法思想大致可分為幾類:基于聚類的方法、基于統計的方法、基于深度的方法(孤立森林)、基于分類模型(one-class SVM)以及基于神經網絡的方法(自編碼器AE)等等。具體方法介紹及代碼可見【異常檢測方法速覽】
本節關注的重點是,當我們采用不平衡數據訓練模型,如何更好決策以及客觀地評估不平衡數據下的模型表現。對于分類常用的precision、recall、F1、混淆矩陣,樣本不均衡的不同程度,都會明顯改變這些指標的表現。
對于類別不均衡下模型的預測,我們可以做分類閾值移動,以調整模型對于不同類別偏好的情況(如模型偏好預測負樣本,偏向0,對應的我們的分類閾值也往下調整),達到決策時類別平衡的目的。這里,通常可以通過P-R曲線,選擇到較優表現的閾值。
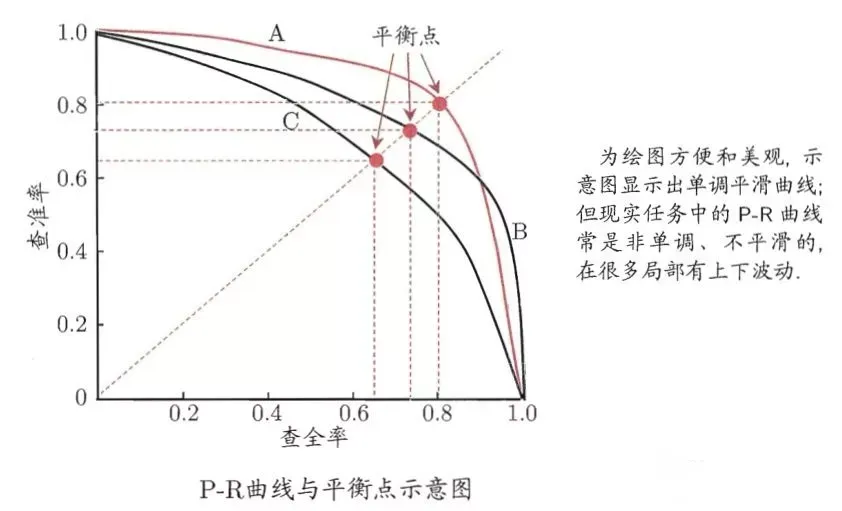
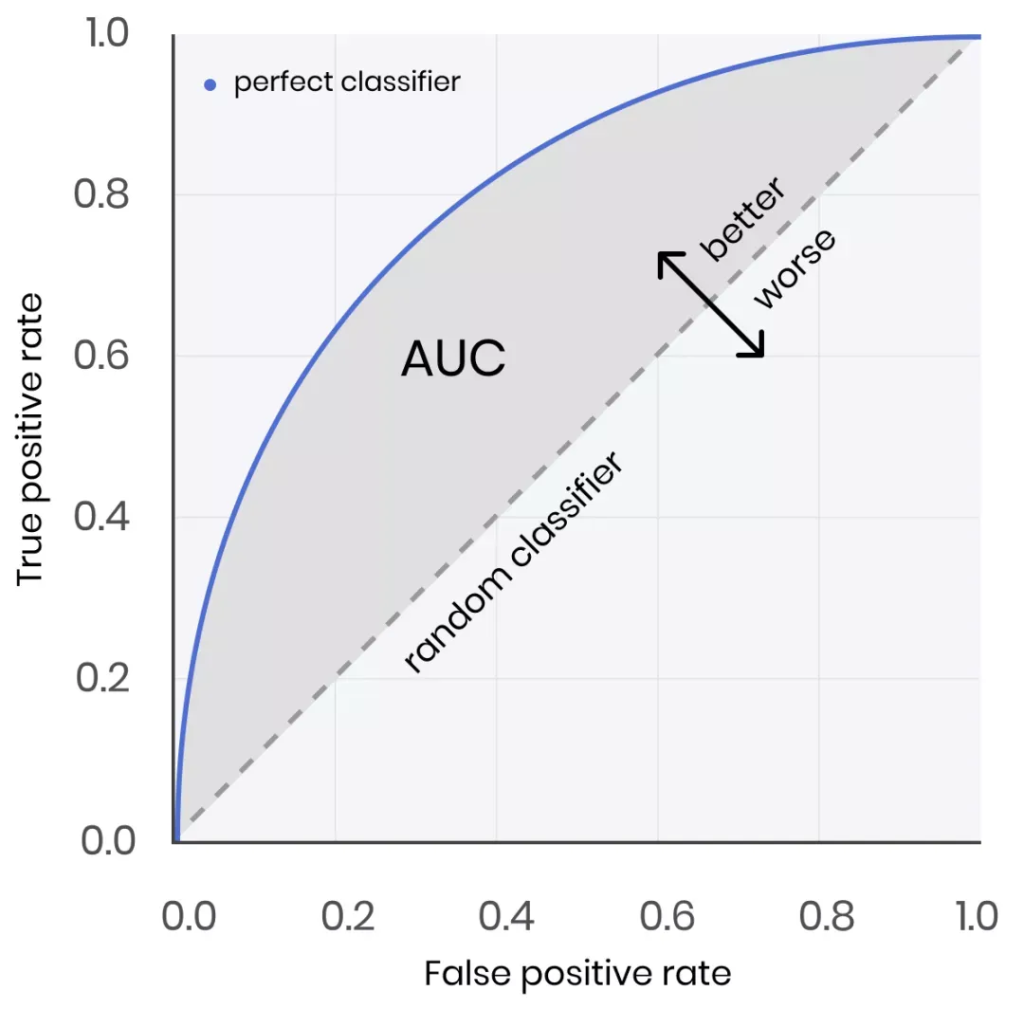
對于類別不均衡下的模型評估,可以采用AUC、AUPRC(更優)評估模型表現。AUC的含義是ROC曲線的面積,其數值的物理意義是:隨機給定一正一負兩個樣本,將正樣本預測分值大于負樣本的概率大小。AUC對樣本的正負樣本比例情況是不敏感,即使正例與負例的比例發生了很大變化,ROC曲線面積也不會產生大的變化。具體可見?【 評估指標】
文章轉自微信公眾號@算法進階







