
如何快速實現REST API集成以優化業務流程
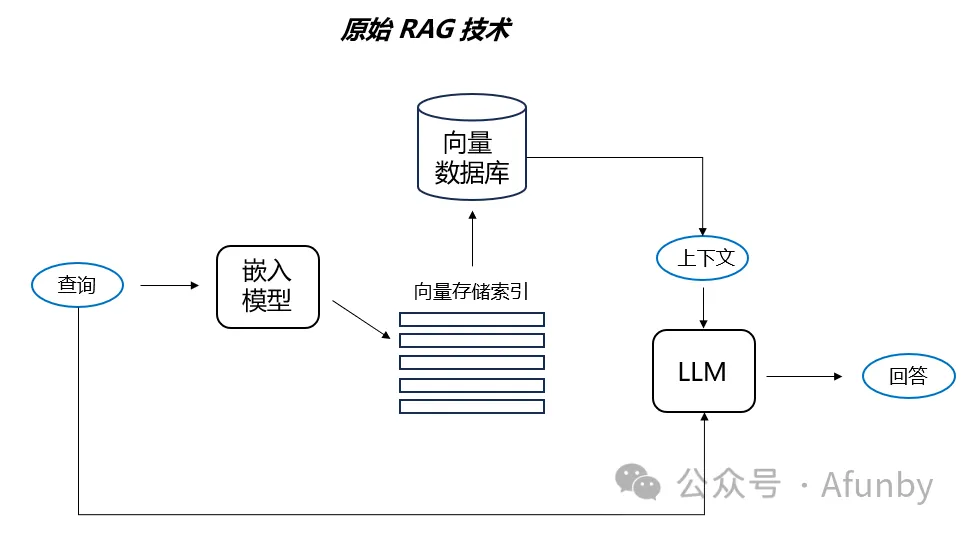
本文討論的 RAG 流水線起始于一個文本文檔語料庫 。我們不涉及此前搜集文本資料的步驟,把它們交給那些強大的開源數據加載器,它們能連接到各種來源,從 Youtube 到 Notion 都不在話下。
簡單地說,標準的 RAG 案例包括以下步驟:
提示工程是改進 RAG 流水線的一種非常經濟實惠的方法。你應該查看 OpenAI 非常全面的提示工程指南。
顯然,雖然 OpenAI 是大語言模型(大語言模型)供應商的市場領頭羊,但也有很多其他選擇,比如 Anthropic 的 Claude,最近流行的小型但功能強大的模型如 Mistral 的 Mixtral、微軟的 Phi-2,還有諸如 Llama2、OpenLLaMA、Falcon 等多種開源選擇。因此,你可以為你的 RAG 流水線挑選最合適的“大腦”。
接下來,我們將深入探討高級 RAG 技術的綜述。這里展示了一個方案,描述了核心步驟和涉及的算法。為了保持方案的清晰可讀,我們省略了一些邏輯循環和復雜的多步驟智能體行為。

方案中的綠色部分代表我們將重點討論的核心 RAG 技術,而藍色部分則是文本。并非所有高級 RAG 的想法都能輕松地在一張圖表中展示出來,例如,一些擴展上下文的方法就被省略了——我們會在后面詳細討論。
我們需要創建一個向量索引,這個索引代表了我們文檔的內容。然后在運行時,我們要在所有這些向量與查詢向量之間尋找最小的余弦距離,以找到最接近的語義含義。
Transformer 模型的輸入序列長度是固定的。即便輸入上下文窗口較大,單個句子或幾個句子的向量通常比覆蓋幾頁文本的平均向量更能準確反映它們的語義意義(這也取決于具體模型,但總體而言是這樣)。因此,我們需要將數據進行分塊處理——把原始文檔分割成一定大小的部分,同時保持其原有意義(如將文本分割成句子或段落,而不是將一個句子切成兩半)。市面上有各種能夠完成此任務的文本分割器。
塊的大小是一個需要考慮的因素——它取決于你所使用的嵌入模型以及其在 Token 上的容量。標準的 Transformer Encoder 模型(例如基于 BERT 的句子轉換器)最多處理 512 個 Token,而像 OpenAI 的 ada-002 則能處理更長的序列,例如 8191 個 Token。這里需要權衡的是,為大語言模型提供足夠的上下文以便于推理,與保持文本嵌入具體到足以高效執行搜索之間的平衡。在 LlamaIndex 中,通過?NodeParser?類及其一些高級選項(例如定義你自己的文本分割器、元數據、節點/塊關系等)來解決這一問題。
下一步是選擇一個模型來對我們的塊進行嵌入——有很多可選模型,我選擇了像 bge-large 或 E5 嵌入系列這樣優化搜索的模型。你可以查看 MTEB 排行榜,了解最新的更新情況。
想要實現分塊和向量化步驟的端到端實現,可以參考 LlamaIndex 中完整數據攝取流程的一個示例。
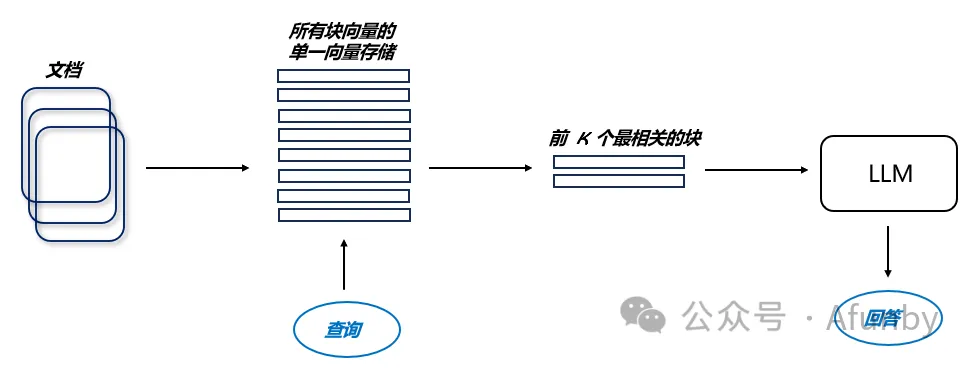
RAG 流水線的核心部分是搜索索引,用于存儲我們在前一步驟中得到的向量化內容。最基本的實現方法是使用平面索引 —— 直接計算查詢向量與所有數據塊向量之間的距離。
更高效的搜索索引,專為處理超過 10000 個元素的大規模檢索而優化,通常采用向量索引,如 faiss、nmslib 或 annoy,它們采用近似最近鄰算法,比如聚類、樹形結構或 HNSW 算法。
還有一些托管解決方案,如 OpenSearch 或 ElasticSearch,以及像 Pinecone、Weaviate 或 Chroma 這樣的向量數據庫,它們在后臺處理第 1 步中描述的數據攝取流程。
根據你選擇的索引類型、數據和搜索需求,你還可以存儲元數據,并利用元數據過濾功能來搜索特定日期或來源的信息。
LlamaIndex 支持多種向量存儲索引,但也支持其他更簡單的索引實現,如列表索引、樹索引和關鍵詞表索引——我們將在融合檢索部分進一步討論這些實現方式。
如果你需要從大量文檔中檢索信息,你需要能夠高效地搜索這些文檔,找到相關信息,并將其整合成一個包含參考來源的統一答案。對于大型數據庫,一個有效的方法是創建兩個索引:一個包含摘要,另一個包含所有的文檔塊,并通過兩步搜索,先利用摘要篩選相關文檔,再在這些相關文檔中進行具體搜索。
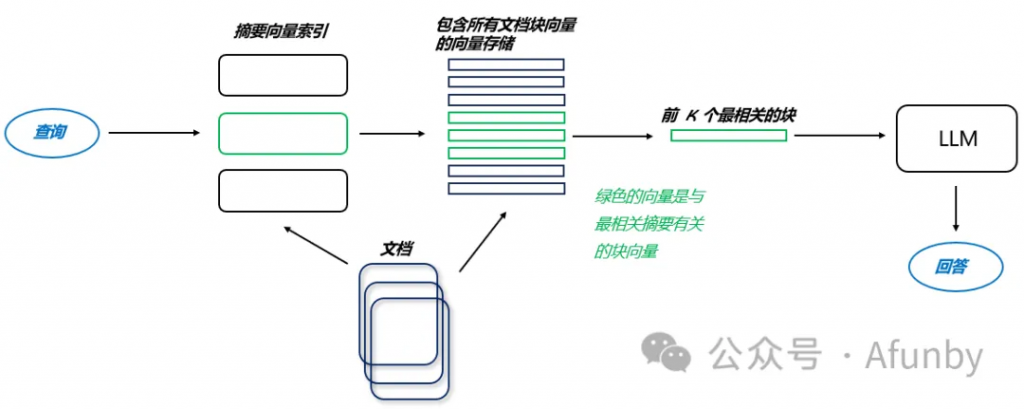
另一個策略是讓大語言模型為每個數據塊生成一個問題,并將這些問題轉換為向量。在運行時,對這些問題向量的索引進行查詢搜索(將索引中的數據塊向量替換為問題向量),然后在檢索后將原始文本塊作為上下文發送給大語言模型,以獲取答案。這種方法由于查詢和假設性問題之間的語義相似性更高,相較于實際數據塊,可以提升搜索質量。
還有一種反向邏輯的方法叫做 HyDE —— 讓大語言模型根據查詢生成一個假設性回應,然后使用其向量與查詢向量共同提高搜索質量。
這里的想法是通過檢索更小的數據塊來提高搜索質量,同時添加額外上下文,以供大語言模型進行推理。有兩種方法:一是在檢索到的小塊周圍擴展上下文,二是將文檔遞歸分割為包含小塊的更大父塊。

一個相對較舊的想法,即你可以從兩個世界中汲取精華 —— 基于關鍵詞的老式搜索?——?稀疏檢索算法,如 tf-idf 或搜索行業標準 BM25 —— 以及現代的語義或向量搜索,并將其結合在一個檢索結果中。這里唯一的技巧是如何恰當地結合不同相似度評分的檢索結果 —— 這個問題通常通過使用互惠排名融合算法來解決,對檢索結果進行重新排名以得出最終輸出。
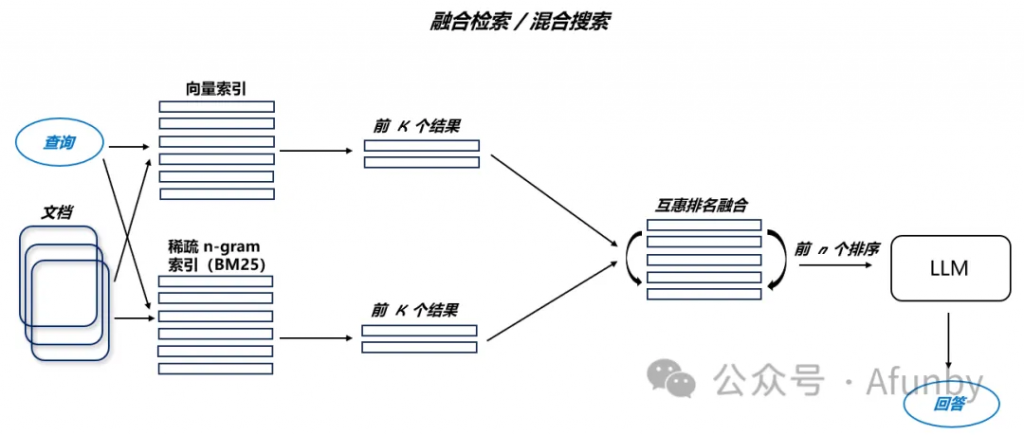
在 LangChain 中,這一過程通過 Ensemble Retriever 類實現,它結合了你定義的多個檢索器,如基于 faiss 的向量索引和基于 BM25 的檢索器,并使用 RRF 算法進行結果的重新排名。
LlamaIndex 中的實現方式與此相似。
混合或融合搜索一般能提供更優的檢索結果,因為它結合了兩種互補的搜索算法,既考慮了查詢與存儲文檔之間的語義相似性,又考慮了關鍵詞匹配。
在使用上述任一算法獲取檢索結果后,現在是時候通過過濾、重新排名或一些轉換來優化這些結果。LlamaIndex 提供了多種后處理器,可以基于相似度評分、關鍵詞、元數據進行過濾,或使用大語言模型、句子轉換器跨編碼器、Cohere 重新排名端點等其他模型進行重新排名,甚至可以基于日期新近性等元數據進行排序——幾乎包括了所有你能想到的方法。
這是在將檢索到的上下文提供給大語言模型以獲取最終答案之前的最后一步。
現在,我們將探討更高級的 RAG 技術,如查詢轉換和路由,這兩種技術都涉及到大語言模型,從而展現了智能體行為——在我們的 RAG 流水線中,涉及到大語言模型的復雜邏輯推理。
在使用上述任一算法獲取檢索結果后,現在是時候通過過濾、重新排名或一些轉換來優化這些結果。LlamaIndex 提供了多種后處理器,可以基于相似度評分、關鍵詞、元數據進行過濾,或使用大語言模型、句子轉換器跨編碼器、Cohere 重新排名端點等其他模型進行重新排名,甚至可以基于日期新近性等元數據進行排序——幾乎包括了所有你能想到的方法。
這是在將檢索到的上下文提供給大語言模型以獲取最終答案之前的最后一步。
現在,我們將探討更高級的 RAG 技術,如查詢轉換和路由,這兩種技術都涉及到大語言模型,從而展現了智能體行為——在我們的 RAG 流水線中,涉及到大語言模型的復雜邏輯推理。
查詢轉換是利用大語言模型(大語言模型)作為推理引擎,對用戶輸入進行調整,以提升檢索效果的技術。實現這一目標有多種方法。
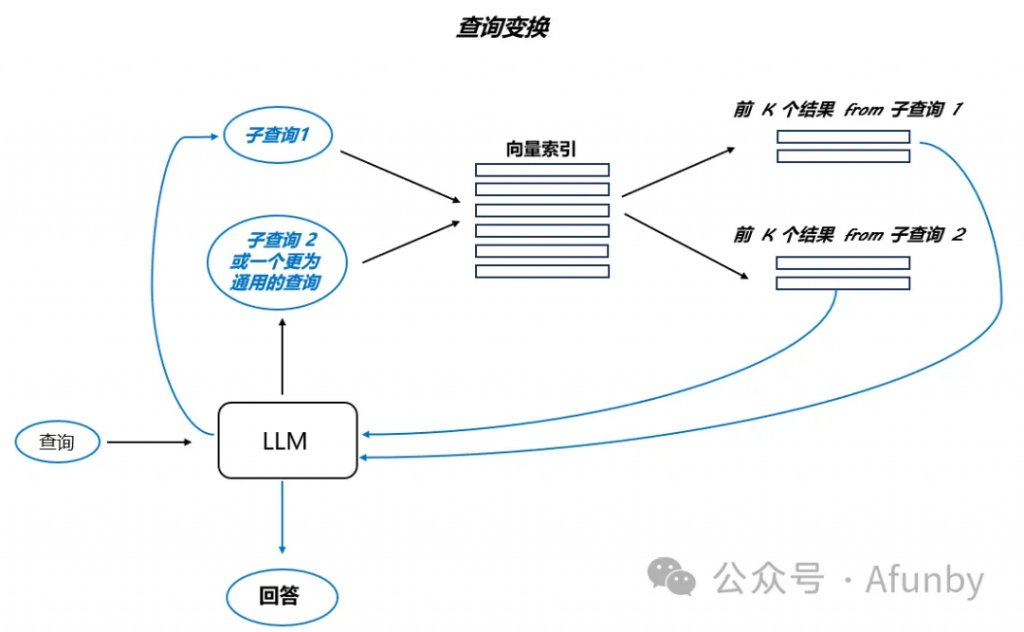
如果查詢內容復雜,大語言模型可以將其分解為幾個子查詢。例如,當你問:“在 Github 上,Langchain 和 LlamaIndex 哪個框架星星更多?” 我們不太可能在語料庫的某些文本中直接找到答案,因此把這個問題分解成兩個更具體、更簡單的子查詢是合理的:
這些子查詢將并行執行,然后將檢索到的上下文合并成一個整體,供大語言模型綜合出最初查詢的終極答案。Langchain 作為多查詢檢索器和 LlamaIndex 作為子問題查詢引擎都實現了這一功能。
這部分沒有編號,因為它更像是一種輔助工具而非檢索改進技術,但仍然非常重要。如果我們由于初始查詢的復雜性(需要執行多個子查詢并將檢索到的上下文合并成一個答案),或因為在不同文檔中找到了單個查詢的相關上下文而使用了多個來源來生成答案,就會出現如何準確引用這些來源的問題。
有幾種方法可以做到這一點:
構建高效的 RAG 系統的下一個關鍵是引入聊天邏輯,這與大語言模型(大語言模型)出現之前的傳統聊天機器人同樣重要,都需要考慮對話上下文。這對于處理后續問題、指代或與先前對話上下文相關的用戶命令至關重要。這一問題通過結合用戶查詢和聊天上下文的查詢壓縮技術得以解決。
常見的上下文壓縮方法有幾種,例如:
值得一提的是,LlamaIndex 還支持基于 OpenAI 智能體的聊天引擎,提供了更靈活的聊天模式,而 Langchain 也支持 OpenAI 的功能性 API。
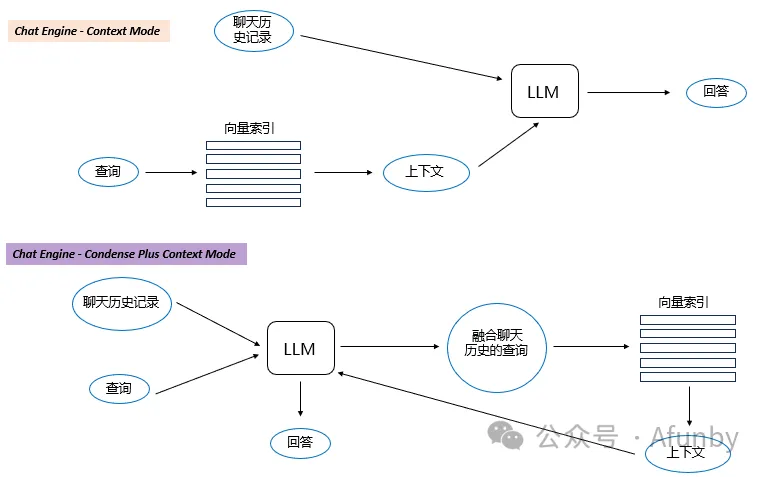
還有像 ReAct 智能體 這樣的其他聊天引擎類型,但我們接下來將直接跳轉到第 7 節,討論智能體本身
查詢路由是大語言模型驅動的決策步驟,用于在接收到用戶查詢后決定下一步的行動 —— 通常的選擇包括進行摘要、對某些數據索引執行搜索,或嘗試多種不同的路由后將其輸出綜合成單一答案。
查詢路由器還用于選擇發送用戶查詢的索引或數據存儲位置。這可能是因為有多個數據來源,如經典的向量存儲、圖數據庫或關系數據庫,或者是因為有多層索引結構 —— 在多文檔存儲的常見情況下,會有一個摘要索引和另一個文檔塊向量索引。
定義查詢路由器包括設定其可能的選擇。路由選項的選擇通過大語言模型調用來執行,返回的結果采用預定義格式,用于將查詢路由至指定索引。在涉及智能體行為時,可能還會將查詢路由至子鏈甚至其他智能體,如下面多文檔智能體方案所示。
LlamaIndex 和 LangChain 都提供了查詢路由器的支持。
智能體(由 Langchain 和 LlamaIndex 支持)自大語言模型 API 首次發布以來就已經存在。其核心思想是為具備推理能力的大語言模型提供一套工具和待完成的任務。這些工具可能包括確定性函數(如代碼函數或外部 API)或其他智能體——正是這種大語言模型鏈接的理念促成了 LangChain 的命名。
智能體本身是一個龐大的領域,在 RAG 概覽中無法深入探討,所以我將直接介紹基于智能體的多文檔檢索案例,并簡要介紹 OpenAI 助理,這是 OpenAI 開發者大會上作為 GPTs 提出的相對新穎的概念,在下面描述的 RAG 系統中發揮作用。
OpenAI 助理實現了許多圍繞大語言模型所需的工具,這些工具之前是開源的,包括聊天歷史、知識存儲、文檔上傳界面,以及可能最重要的,功能調用 API。這些 API 能將自然語言轉換為對外部工具或數據庫查詢的調用。
LlamaIndex 中有一個 OpenAIAgent 類,將這些高級邏輯與 ChatEngine 和 QueryEngine 類結合,提供基于知識和上下文感知的聊天以及在一次對話輪次中調用多個 OpenAI 功能的能力,這真正帶來了智能的代理行為。
讓我們來看看多文檔智能體方案——這是一個復雜的設置,涉及在每個文檔上初始化一個智能體(OpenAIAgent),負責文檔摘要和經典問答機制,以及一個負責將查詢路由至文檔智能體并合成最終答案的頂級智能體。
每個文檔智能體擁有兩種工具——向量存儲索引和摘要索引,并根據路由的查詢決定使用哪一個。對于頂級智能體而言,所有文檔智能體都是其工具。
這個方案展示了一個高級 RAG 架構,涉及每個參與智能體做出的眾多路由決策。這種方法的優勢在于能夠比較不同文檔及其摘要中描述的不同解決方案或實體,并結合經典的單文檔摘要和問答機制——這基本涵蓋了與文檔集合互動的最常見聊天用例。
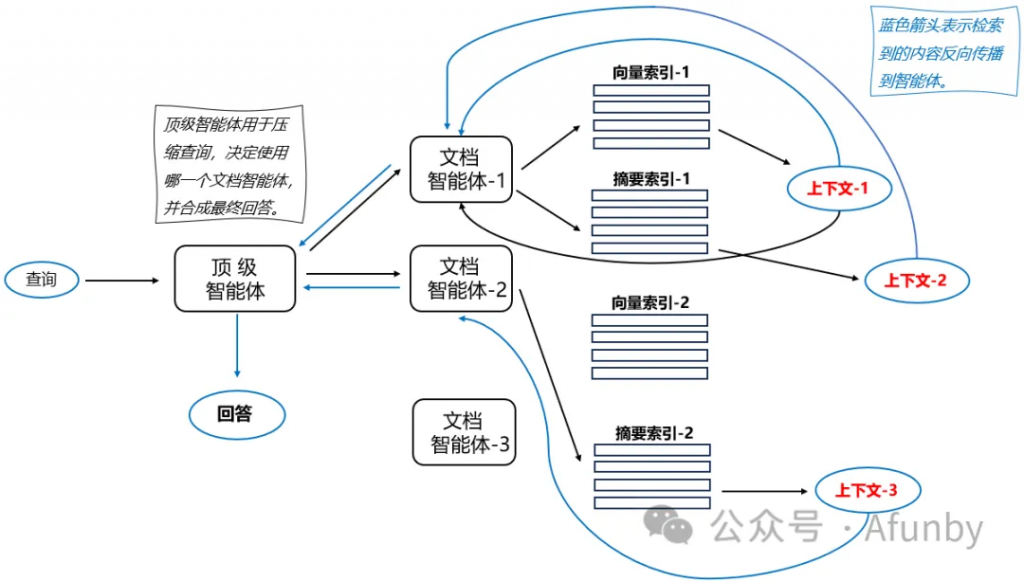
這種復雜的方案可能存在的缺點是,由于需要與智能體內的大語言模型(大語言模型)進行多次迭代,其速度可能較慢。值得注意的是,大語言模型的調用通常是 RAG 流水線中最耗時的操作,而搜索設計上是優化了速度的。因此,對于大型多文檔存儲,建議考慮對這個方案進行簡化,使其更具可擴展性。
響應合成器是任何 RAG 流水線的最后一步——基于我們仔細檢索到的所有上下文和初始用戶查詢生成答案。最簡單的方法是將所有檢索到的上下文(超過一定相關性閾值)與查詢一起一次性輸入大語言模型。然而,還有其他更復雜的選項,涉及多次調用大語言模型來精煉檢索到的上下文并生成更優答案。
響應合成的主要方法包括:
這種方法涉及對 RAG 流水線中的兩個深度學習模型之一進行微調——要么是負責嵌入質量和上下文檢索質量的 Transformer 編碼器,要么是負責充分利用提供的上下文以回答用戶查詢的大語言模型(大語言模型)。幸運的是,后者擅長少樣本(甚至是零樣本)學習。
現在的一個重要優勢是,可以利用像 GPT-4 這樣的高端大語言模型生成高質量的合成數據集。
但需要意識到的是,使用專業研究團隊在精心收集、清洗和驗證的大型數據集上訓練的開源模型,并用小型合成數據集進行快速調整,可能會在總體上限制模型的能力。
我曾對編碼器微調方法持有一定懷疑,因為最新的為搜索優化的 Transformer 編碼器已經相當高效。然而,在 LlamaIndex 的筆記本環境中,我測試了對 bge-large-en-v1.5(寫作時位于 MTEB 排行榜前四)的微調效果,發現它帶來了 2% 的檢索質量提升。盡管提升不是很顯著,但了解這個選項仍然有價值,特別是在你為特定領域數據集構建 RAG 時。
另一個常見選擇是使用交叉編碼器重新排列檢索結果,特別是當你對基礎編碼器的信任度不足時。這個過程包括將查詢和每個前 k 個檢索到的文本塊傳遞給交叉編碼器,并用 SEP 令牌分隔,然后微調它以對相關塊輸出 1,對不相關塊輸出 0。可以在這里找到一個很好的微調過程示例,結果顯示通過交叉編碼器微調,成對得分提高了 4%。
最近 OpenAI 開始提供大語言模型微調 API,LlamaIndex 也有關于在 RAG 設置中微調 GPT-3.5-turbo 的教程,旨在“提煉”GPT-4 的部分知識。這里的想法是獲取一個文檔,用 GPT-3.5-turbo 生成一些問題,然后使用 GPT-4 根據文檔內容生成這些問題的答案(構建一個由 GPT-4 驅動的 RAG 流水線),接著在這個問題-答案對數據集上微調 GPT-3.5-turbo。用于 RAG 流水線評估的 ragas 框架顯示了 5% 的忠實度指標提升,意味著微調后的 GPT-3.5-turbo 模型比原始模型更好地利用提供的上下文生成答案。
一種更復雜的方法在最近的論文《RA-DIT: Retrieval Augmented Dual Instruction Tuning》中展示,提出了一種同時調整大語言模型和檢索器(原論文中的雙編碼器)的技術,基于查詢、上下文和答案的三元組。關于實現細節,請參考這個指南。這種技術用于通過微調 API 微調 OpenAI 大語言模型,也用于微調開源 Llama2 模型(在原論文中),在知識密集型任務指標上提升了約 5%(與搭載 RAG 的 Llama2 65B 相比),在常識推理任務上也有幾個百分點的提升。
RAG 系統的性能評估通常涉及幾個框架,它們的共同理念是設定幾個獨立指標,如整體答案相關性、答案基礎性、忠實度和檢索到的上下文相關性。
如前文所提到的 Ragas 使用真實性和答案相關性作為生成答案的質量指標,以及用于 RAG 方案檢索部分的傳統上下文精確度和召回率。
在 Andrew NG 最近發布的短課程《構建和評估高級 RAG》中,LlamaIndex 和評估框架 Truelens 提出了 RAG 三元組:
最關鍵且最可控的指標是檢索到的上下文相關性——基本上上文所述的高級 RAG 流水線的第 1-7 部分及編碼器和排名器微調部分都旨在提升這一指標,而第 8 部分和大語言模型微調則專注于答案相關性和基礎性。
關于相對簡單的檢索器評估流程的一個好例子可以在這里找到,它在編碼器微調部分中得到應用。一種更高級的方法不僅考慮命中率,還考慮平均倒數排名(一種常見的搜索引擎指標)以及生成答案的忠實度和相關性,這在 OpenAI 的烹飪書中得到展示。
LangChain 有一個較為高級的評估框架 LangSmith,可以實施自定義評估器,并監控 RAG 流水線內部的跟蹤,以增強系統的透明度。
如果你正在使用 LlamaIndex 構建系統,可以使用 rag_evaluator llama pack 這個工具,它提供了一個快速評估你的流水線的方法,適用于公共數據集。
我嘗試勾勒出 RAG 的核心算法方法,并通過示例來闡述其中一些,希望這能激發你在 RAG 流水線中嘗試新的想法,或為今年發明的各種技術帶來一定的系統性。對我來說,2023 年是迄今為止最令人激動的一年。
還有許多其他方面需要考慮,例如基于網絡搜索的 RAG(如 LlamaIndex、webLangChain 的 RAGs)、更深入地探索智能體架構(包括 OpenAI 最近在這方面的投入)以及關于大語言模型長期記憶的一些想法。
RAG 系統面臨的主要生產挑戰之一,除了答案相關性和忠實度之外,還有速度問題,尤其是在采用更靈活的基于智能體的方案時。但這是另一篇文章的主題。ChatGPT 和大多數其他助手使用的流媒體功能并非無緣無故采用賽博朋克風格,而是為了縮短感知的答案生成時間。這也是我認為小型大語言模型,以及最近發布的 Mixtral 和 Phi-2 有著光明的未來,它們正在引領我們朝這個方向前進。







