使用Python調用免費歸屬地查詢API
數據:包含回答問題的相關信息的數據集合(如文件、網頁)。
檢索: 能從數據中檢索相關源知識的檢索策略。
生成: 利用相關源知識,在 LLM 的幫助下生成回復。
在與模型直接交互時,LLM (大語言模型)會收到一個問題,并根據其參數知識生成一個響應。 RAG 在此過程中增加了一個額外步驟,利用檢索功能查找相關數據,為 LLM (大語言模型)建立額外的上下文。
在下面的例子中,我們使用密集向量檢索策略從數據中檢索相關的源知識。 然后將這些源知識作為上下文傳遞給 LLM(大語言模型),以生成響應。
RAG 不一定要使用密集矢量檢索,它可以使用任何能從數據中檢索出相關源知識的檢索策略。 它可以是簡單的關鍵詞搜索,甚至是谷歌網頁搜索。
我們將在今后的文章中介紹其他檢索策略。
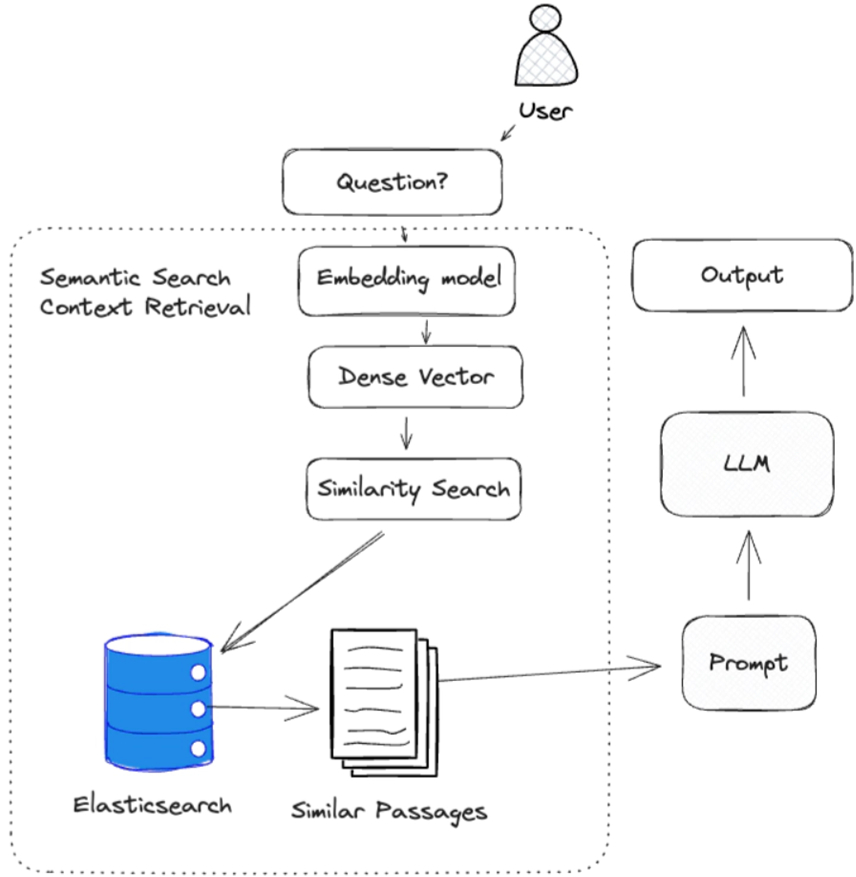
檢索相關源知識是有效回答問題的關鍵。
生成式人工智能最常用的檢索方法是使用密集向量進行語義搜索。 語義搜索是一種需要嵌入模型將自然語言輸入轉化為表示源知識的密集向量的技術。 我們依靠這些密集向量來表示源知識,因為它們能夠捕捉文本的語義。 這一點非常重要,因為它允許我們將源知識的語義與問題進行比較,以確定源知識是否與問題相關。
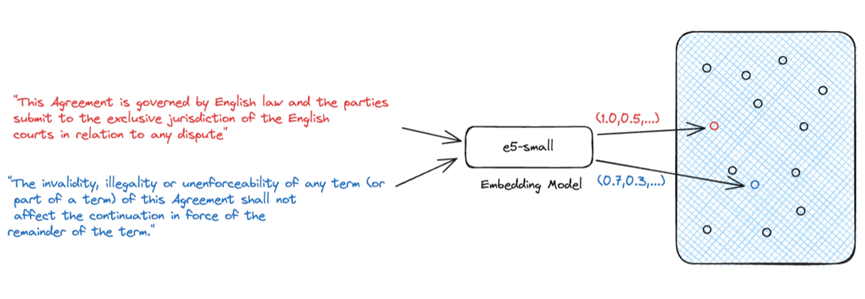
給定一個問題及其嵌入,我們就能找到最相關的源知識。
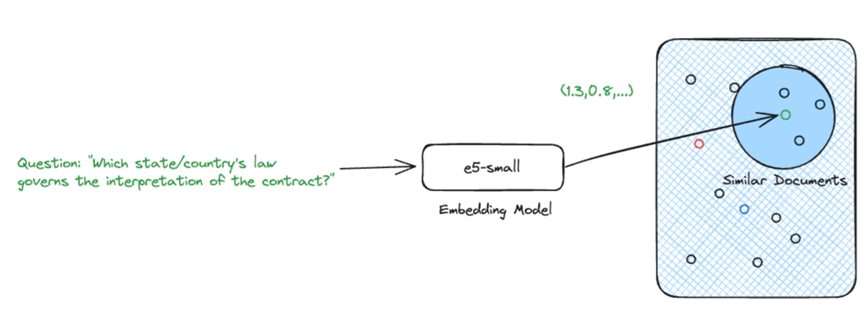
使用密集向量進行語義搜索并不是唯一的檢索選擇,但卻是當今最流行的方法之一。 我們將在今后的文章中介紹其他方法。
訓練后,LLM (大語言模型)被凍結。 模型的參數知識是固定的,無法更新。 但是,當我們在 RAG 管道中添加數據和檢索時,我們可以根據底層數據源的變化更新源知識,而無需重新訓練模型。
模型的響應也可以受限于只使用上下文中提供的源知識,這有助于限制幻覺。 這種方法還允許使用較小的、針對特定任務的 LLM(大語言模型),而不是大型的、通用的模型。 這樣就能優先使用源知識來回答問題,而不是在訓練過程中獲得的一般知識。
此外,RAG 還能提供用于回答問題的源知識的清晰可追溯性。 這對于合規性和監管原因非常重要,也有助于發現 LLM(大語言模型) 的幻覺。 這就是所謂的源跟蹤。
檢索到相關源知識后,我們就可以利用它來生成對問題的回答。 為此,我們需要
建立背景:包含回答問題相關信息的源知識集合(如文檔、網頁)。 這為模型生成回復提供了背景。
提示模板:針對特定任務(回答問題、總結文本)用自然語言編寫的模板。 用作 LLM (大語言模型)的輸入。
問題:與任務相關的問題。 一旦有了這三個組件,我們就可以使用 LLM(大語言模型)生成對問題的回復。
有效檢索是有效回答問題的關鍵。 良好的檢索可為上下文提供一系列不同的相關源知識。 然而,這與其說是一門科學,不如說是一門藝術,需要大量的實驗才能獲得成功,而且在很大程度上取決于使用情況。
由于大型文檔包含多種語義,因此難以用單個密集向量來表示。 為了實現有效的檢索,我們需要將文檔分解成較小的文本塊,這些文本塊可以準確地表示為單個密集向量。
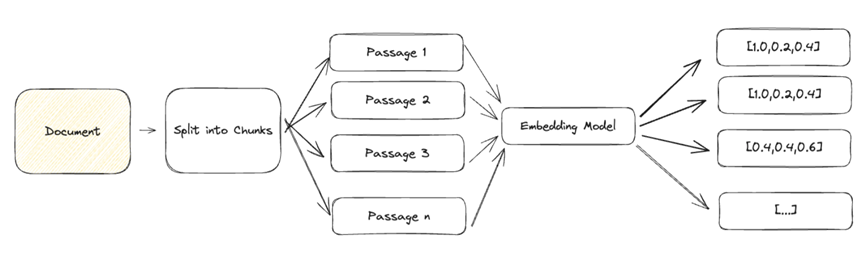
一般文本的常見方法是按段落分塊,并將每個段落表示為一個密集的向量。 根據您的使用情況,您可能希望使用標題、小標題甚至句子將文檔細分為若干小塊。
在使用 LLM(大語言模型) 時,我們需要注意傳遞給模型的上下文的大小。
LLM (大語言模型)一次可處理的令牌數量有限制。 例如,GPT-3.5-turbo 有 4096個令牌的限制。
其次,隨著情境的增加,產生的反應質量可能會下降,從而增加產生幻覺的風險。
較大的背景也需要更多的時間來處理,更重要的是,它們會增加 LLM 的成本。
這又回到了檢索的藝術上。 我們需要在分塊大小和嵌入準確性之間找到恰當的平衡點。
Retrieval Augmented Generation(檢索增強生成)是一種強大的技術,可以通過提供相關的源知識作為上下文,幫助提高 LLM (大語言模型)生成的回復質量。 但 RAG 并不是靈丹妙藥。它需要大量的實驗和調整才能達到最佳效果,而且在很大程度上取決于您的使用情況。
本文翻譯源自:https://www.elastic.co/search-labs/blog/retrieval-augmented-generation-rag