GraphRAG:基于PolarDB+通義千問api+LangChain的知識圖譜定制實踐
我們輸入文字,點擊“執行測試”,等待片刻,便可試聽語音合成的效果:
hifi_spk1(3),阿里云開發者,13秒
第二種方式是使用編程,通過簡單的幾行代碼,就可以實現自己的語音合成功能,并集成嵌入到具體的應用中去。這種方式適合選定喜歡的發音人后、進行深度的應用開發。
魔搭社區提供了免費的CPU算力(不限額)和GPU算力(NVIDIA-V100-16G 限額100小時),供開發者進行使用,下面我們使用Notebook開發環境來簡單演示如何實現使用代碼進行語音合成。
讓我們選擇CPU服務,稍等幾分鐘服務啟動,我們點擊“查看NoteBook”,進入開發環境,選擇啟動一個python腳本。
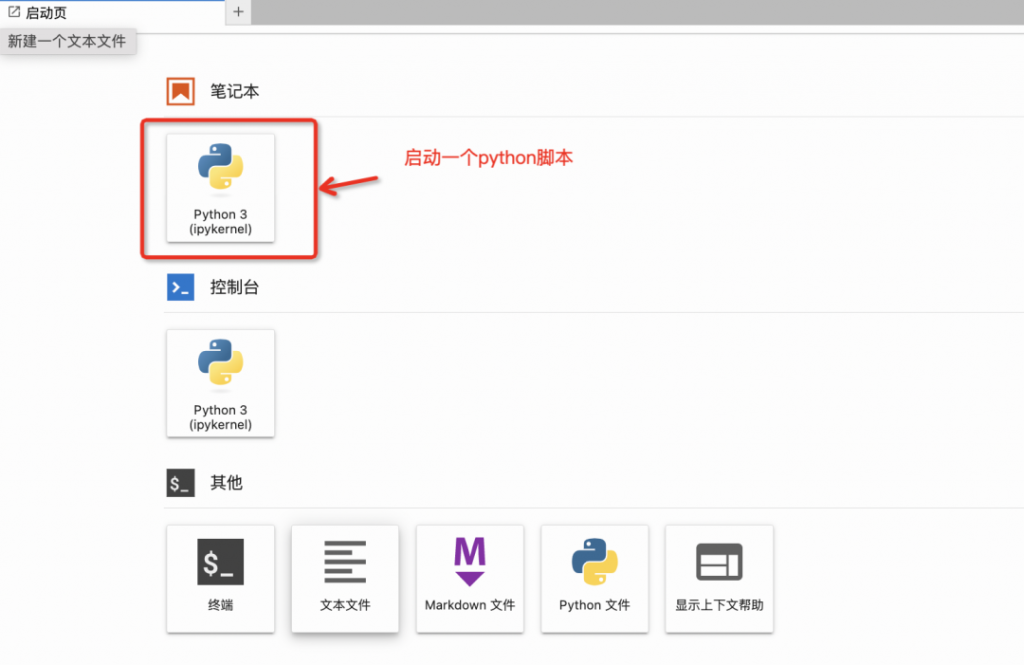
這些語音AI模型都配備了代碼示例,我們可以在模型詳情頁的代碼示例中找到:
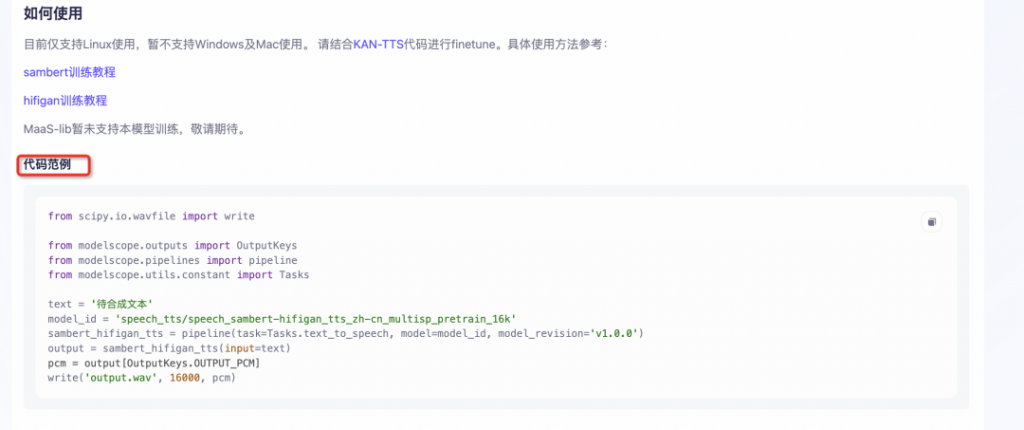
將該代碼進行復制并粘貼至notebook的python腳本當中,我們可以將代碼中‘待合成文本’字符串替換成想要的合成本文,并執行程序,便可以下載生成的音頻文件進行試聽。

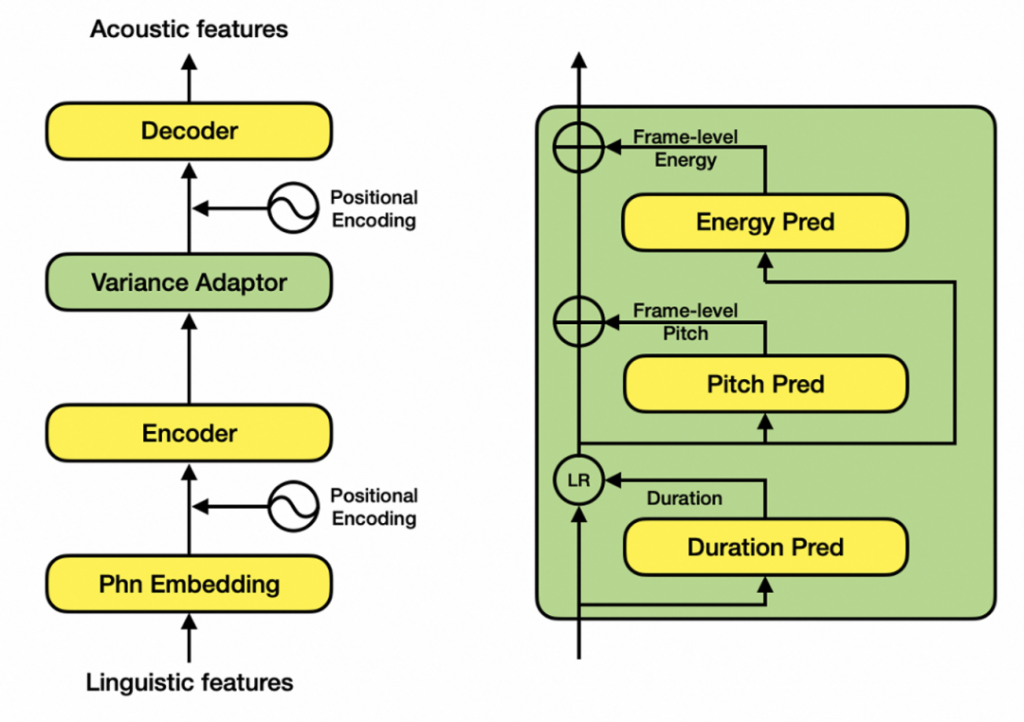
這項語音合成技術背后是達摩院的顯式韻律聲學模型SAMBERT以及Hifi-GAN聲碼器的結合。
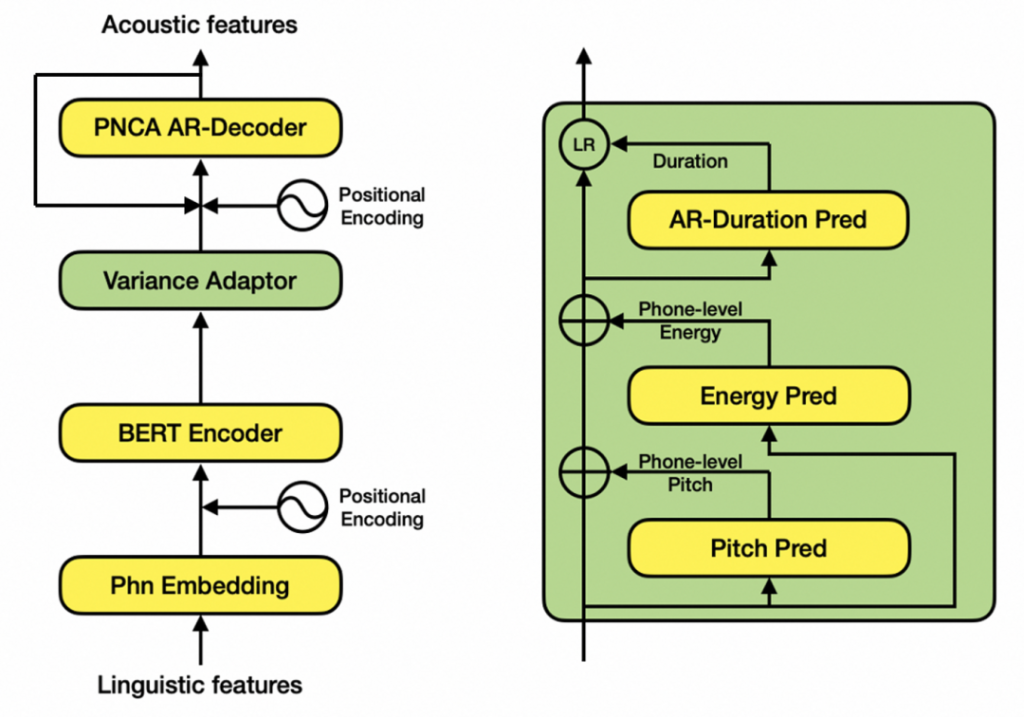
在語音合成領域,目前以FastSpeech2類似的Non-Parallel模型為主流,它針對基頻(pitch)、能量(energy)和時長(duration)三種韻律表征分別建模。但是,該類模型普遍存在一些效果和性能上的問題:獨立建模時長、基頻、能量,忽視了其內在聯系;完全非自回歸的網絡結構,無法滿足工業級實時合成需求;幀級別基頻和能量預測不穩定…
因此達摩院設計了SAMBERT,一種基于Non-Parallel結構的改良版TTS模型,它具有以下優點:
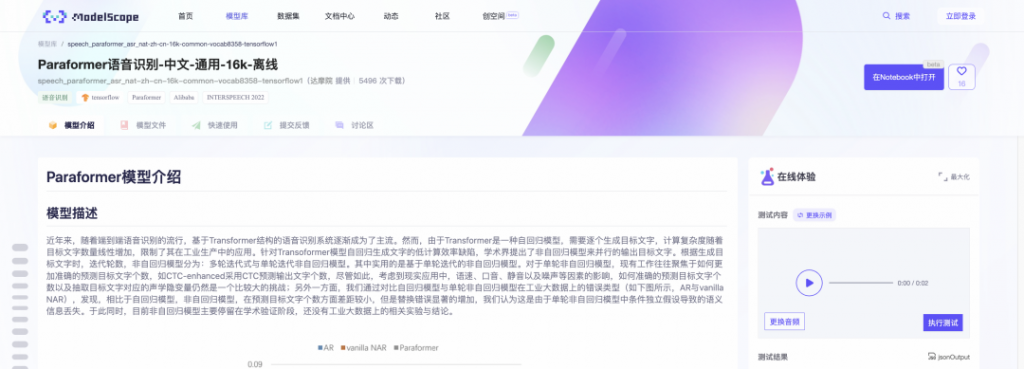
在魔搭社區上,達摩院語音實驗室開放了核心的語音識別模型“Paraformer語音識別-中文-通用-16k-離線”,這是即將大規模商業部署的下一代模型,其訓練數據規模達到5萬小時以上,通過對非自回歸語音識別模型技術的改進,不僅達到當前類Transformer自回歸模型的語音識別準確率,而且在推理效率上有10倍的加速比提升。
模型鏈接參考文末[2]。
在魔搭社區中,語音識別模型與語音合成一樣,提供Demo和Notebook兩種方式進行效果體驗,操作方法請參見上文,不再贅述。
除了開放最先進的Paraformer模型之外,語音實驗室還免費開放了當紅的語音識別模型UniASR,它在公有云上提供商業化的服務,廣受歡迎。UniASR模型含蓋了中、英、日、俄等語種,支持8k/16k采樣率,可以滿足開發者不同場景的開發需求。
模型鏈接參考文末[3]。
信號處理也是語音處理的一個重要的技術組成分支,達摩院開源了基于深度學習的回聲殘余抑制算法。
模型名:DFSMN回聲消除-單麥單參考-16k
模型鏈接參考文末[4]。
讓我們先來看一看這個模型的回聲消除算法的效果,下面兩段音頻分別是近講及遠講采集的語音信號:
下面的音頻是使用回聲消除模型的結果:
從用戶體驗角度,一個理想的回聲消除算法要達到以下效果:遠端單講(far end single talk)時零回聲泄露;近端單講(near end single talk)時語音無損;雙端同時講話時可以互相聽清,也即雙講(double talk)通透。目前在開源的信號處理算法當中,雙講時的效果都比較差強人意。這是因為目前的開源信號處理算法無法有效區分錄音信號中的回聲信號和近端語音信號,而且真實通話中雙講出現的時間一般較短、時間占比也很低,所以從策略上為了確保零回聲泄露,只好犧牲雙講時的效果。
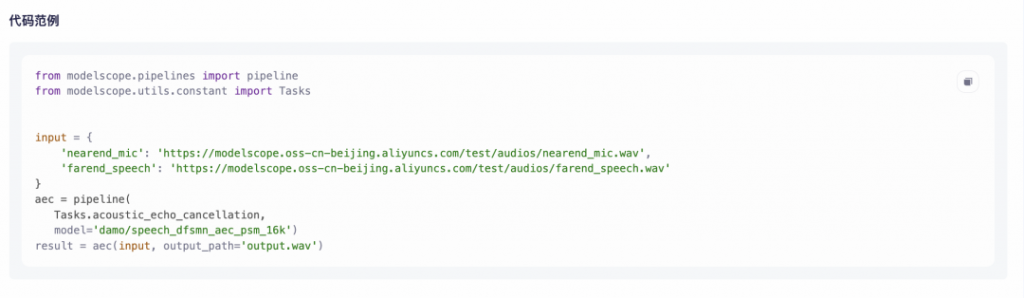
達摩院這個模型能夠進一步提升雙講通話效果,滿足用戶對語音通信時的音質要求,已在阿里內部音視頻項目上完成了工業化部署。大家如果現在使用釘釘視頻會議,會發現了多一個較為方便的對講功能。這次模型開源,希望能對從事webRTC的研究者與開發者有所幫助,歡迎大家基于這個模型進行應用開發,在NoteBook中只需要5行代碼就可以得到回聲消除結果。
該模型的技術創新點在于借鑒了智能降噪的解決思路:數據模擬->模型優化->模型推理。
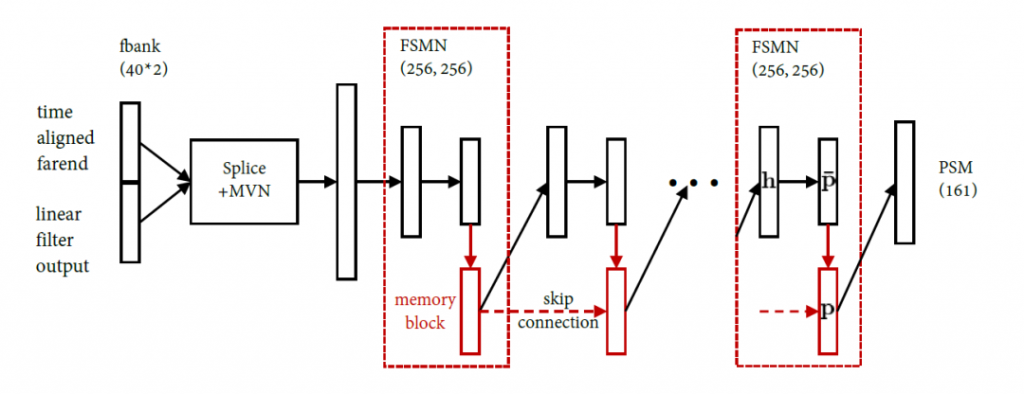
具體而言,我們結合回聲殘余抑制的任務特點,在輸入特征上,拼接了線性濾波器的輸出信號和時延對齊的回采信號,并提取FBank進行均值方差歸一化。在輸出目標上,選擇了相位感知的掩蔽值(Phase-Sensitive Mask, PSM)。在模型推理階段,對PSM與線性輸出的信號頻譜逐點相乘后再進行IFFT (inverse Fast Fourier Transform)獲得近端語音。
在過去的語音 AI 探索當中,達摩院完整實現了從研到發,從模型創新到提供API的全鏈條。但是隨著近年來語音AI的飛速發展,開發者角色變得多元化、各方面需求也變得越來越豐富,傳統的“包打天下”的模式已不再合適。面向未來,我們希望通過魔搭這樣的開放、開源的社區來推進語音AI的研究和應用,促進語音AI生態的活躍和繁榮。

魔搭社區官網請點擊閱讀原文查看。參考鏈接:
[1]https://modelscope.cn/models/speech_tts/speech_sambert-hifigan_tts_zh-cn_multisp_pretrain_16k/summary
[2]https://modelscope.cn/models/damo/speech_paraformer_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1/summary
[3]https://modelscope.cn/models/damo/speech_UniASR-large_asr_2pass-zh-cn-16k-common-vocab8358-tensorflow1-offline/summary
[4]https://modelscope.cn/models/damo/speech_dfsmn_aec_psm_16k/summary
文章轉自微信公眾號@阿里云開發者