
豆包 Doubao Image API 價格全面解析
此外,騰訊混元文生圖模型的1.2版本在圖片質感和構圖方面都進行了升級,提供了更高質量的圖像生成能力。借助與Kohya圖形化界面的支持,開發者可以更低門檻地訓練和調整個性化的LoRA模型,進一步提升模型的實用性和易用性。
騰訊還宣布了混元Captioner模型的開源,這是一個專門用于文生圖的打標模型。與業界常用的Captioner模型不同,混元Captioner能夠更好地理解和表達中文語義,生成的圖片描述更加結構化、完整和準確。其支持中文和英文雙語,能夠精準識別常見的知名人物和地標,并允許開發者自行補充和導入個性化的背景知識。

通過混元Captioner,全球的圖像研究者和數據標注人員可以更高效地提升圖像描述質量,生成更全面且準確的圖片描述,用于模型的訓練和優化。生成的數據集不僅適用于混元DiT模型,也可用于其他視覺模型的訓練,顯著提高了數據集的質量和模型的性能。
為了進一步提升模型的易用性,騰訊混元團隊推出了小顯存版本并接入Kohya訓練界面。Kohya是一個開源的、輕量化的模型微調訓練服務,提供了用戶友好的圖形化界面。開發者無需深入代碼層面,只需通過圖形化界面即可完成模型的精調和LoRA訓練。

這套系統讓訓練好的模型可以低成本地與WebUI等推理界面結合,形成完整的“訓練-生圖”工作流,大大降低了技術門檻,使得更多開發者能夠參與到高質量模型的訓練和應用中。
在AI模型的訓練中,數據集的質量至關重要。混元Captioner通過生成高質量的圖片描述文本,為開發者提供了一種有效的數據集優化工具。開發者可以將原始圖片集導入混元Captioner,生成詳細的標注數據,并利用其過濾無關信息,優化描述文本。
雖然通用的多模態Captioner模型在描述文本生成上已經取得了一定的成功,但普遍存在描述過于簡單或冗長的問題,混元Captioner通過引入豐富的背景知識和結構化描述體系,顯著提升了描述的準確性和完整性。
自全面開源以來,混元DiT模型不斷加快生態系統的建設。除小顯存版本外,騰訊還發布了專屬的加速庫和推理代碼,極大提高了模型的推理效率,并縮短了生圖時間。用戶可以通過Hugging Face Diffusers調用混元DiT模型及其插件,或基于Kohya和ComfyUI等圖形化界面進行訓練和使用。
在眾多開發者的支持下,混元DiT迅速獲得了超過2.6k的GitHub Star,成為最受歡迎的國產DiT開源模型之一。這一成就不僅展示了模型的技術實力,也反映了其廣泛的應用潛力。
為了更好地服務開發者,騰訊提供了詳細的API獲取和使用步驟。通過訪問騰訊云網站,用戶可以輕松找到對應的控制臺,搜索騰訊混元大模型,并通過OpenAI SDK方式接入,快速創建API Key。
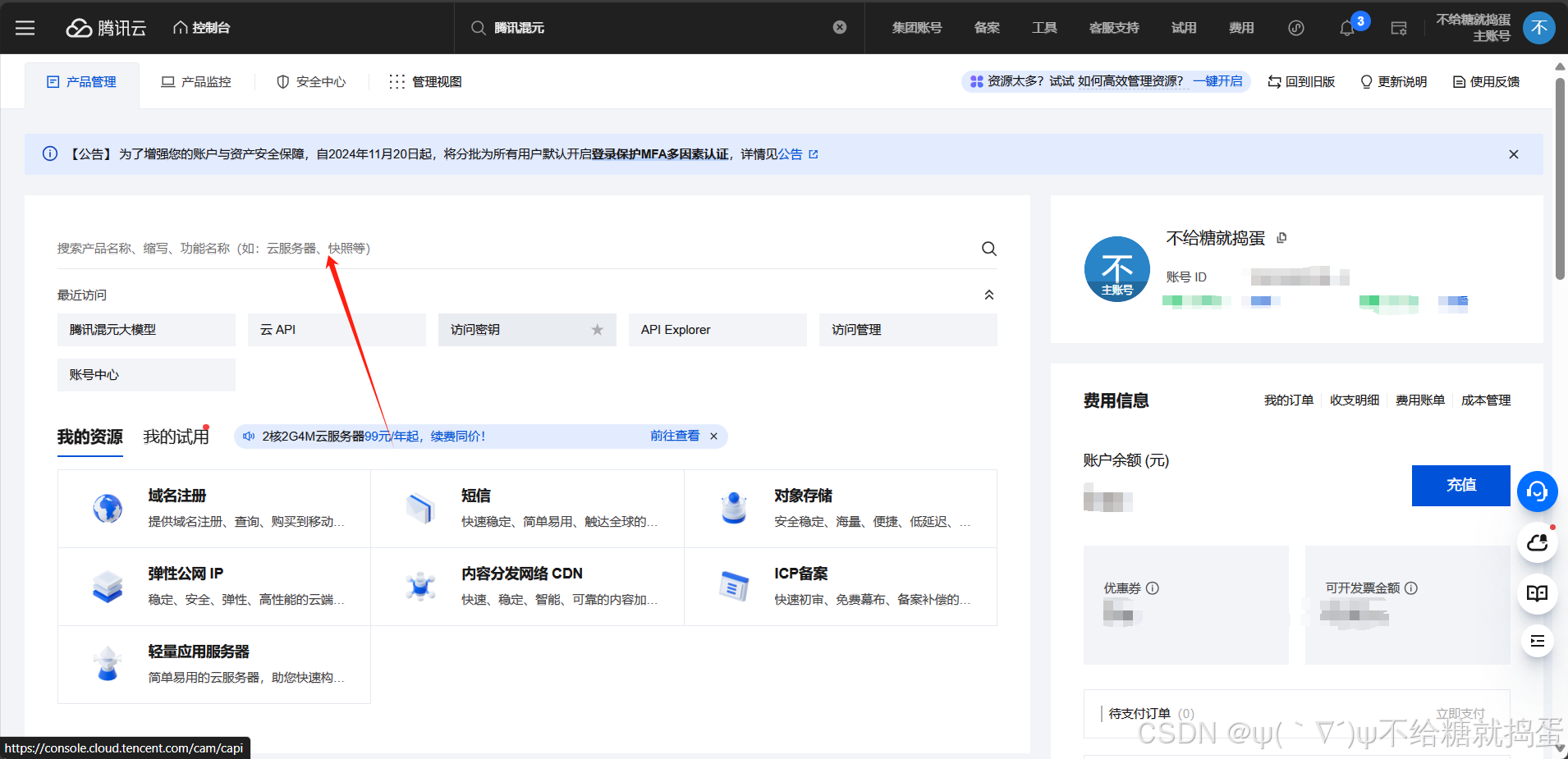
通過這些步驟,用戶不僅可以快速獲取API Key,還能通過LobeChat等平臺調用騰訊混元AI,實現多種應用場景下的智能化解決方案。
問:如何使用騰訊混元Captioner提升數據集質量?
問:混元DiT小顯存版本對個人電腦的要求是什么?
問:如何獲取混元API Key并在LobeChat中使用?
問:混元DiT模型的開源帶來了什么影響?
問:如何利用Kohya界面進行模型訓練?
通過本文的詳細分析和介紹,希望讀者能夠更好地理解騰訊混元文生圖的技術特點和應用價值,并能夠在實際項目中充分利用這一強大的工具。





