
文心一言寫代碼:代碼生成力的探索
在RAG系統中,小型語言模型(SLMs)往往面臨一些挑戰,例如復雜查詢的解釋、多步推理以及查詢與文檔之間的語義匹配等問題。這些問題導致SLMs在性能上不如大型語言模型(LLMs)那么出色,特別是在需要大量計算資源的場景中表現尤為明顯。
然而,小型語言模型也有其獨特的優勢,例如在模式匹配和局部文本處理方面的卓越表現,以及通過顯式結構信息來彌補語義能力的不足。為了優化SLMs在RAG系統中的應用,研究者們提出了MiniRAG框架,該框架通過將復雜操作分解為更簡單的步驟來維持系統的魯棒性。
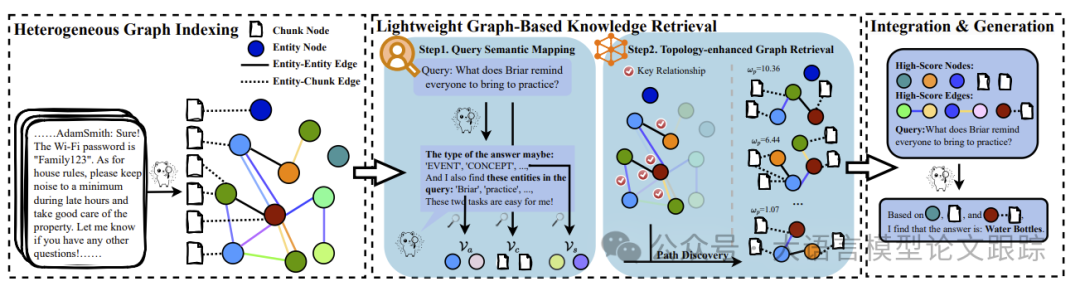
MiniRAG框架由兩個核心組件組成:異構圖索引和輕量級圖知識檢索。該框架旨在通過高效的索引和檢索機制,最大化利用小型語言模型的優勢。
異構圖索引是MiniRAG框架的基礎,旨在構建一個語義感知的知識表示結構。SLMs在這一過程中面臨兩大挑戰:
為了解決這些問題,MiniRAG框架引入了一種數據索引機制,生成語義感知的異構圖。該圖結合了文本塊和命名實體,創建語義網絡,便于精確的信息檢索。
在設備上運行的RAG系統受限于計算能力和數據隱私,因此需要依賴較小的替代方案。MiniRAG框架提出了一種基于圖的知識檢索機制,通過語義感知的異構圖實現了高效的知識檢索。
從容大模型1.5版本包括多種尺寸的基礎和聊天模型,這些模型不僅在性能上有顯著提升,還支持多語言。該版本的特別之處在于其強大的外部系統鏈接能力,結合RAG技術,可以實現更高效的智能問答系統。
與之前的版本相比,從容大模型1.5在多個基準評測中表現出色,尤其在自然語言理解、數學計算和邏輯推理等任務上。其強大的工具調用能力,以及Code Interpreter的能力,使得它能夠在更多應用場景中發揮作用。
基于從容大模型1.5和LlamaIndex,可以搭建一個高效的智能問答系統。LlamaIndex提供的上下文增強功能,使得系統能夠更準確地生成文本答案。
LlamaIndex是一個基于LLM的應用程序數據框架,專注于上下文增強。它提供了必要的抽象,可以更輕松地攝取、構建和訪問私有或特定領域的數據。
LlamaIndex的核心功能包括數據攝取、數據結構化、數據檢索和應用集成。它不僅支持向量存儲索引、樹索引等多種數據結構,還可以與LangChain、Flask等框架集成,極大地增強了應用的靈活性和功能性。
GTE文本向量是自然語言處理領域的重要工具,尤其在文本聚類、文本相似度計算等任務中發揮關鍵作用。基于GTE的文本表示模型,能夠在學術研究和工業應用中提供更高效的文本處理能力。
GTE模型采用Dual Encoder框架,通過大規模弱監督數據和高質量精標數據進行訓練。其應用范圍包括雙句文本相似度計算、query與多doc候選相似度排序等。
RAG技術是一種結合檢索與生成的創新方法,通過在生成答案之前檢索相關信息,極大地提升了內容生成的準確性和相關性。
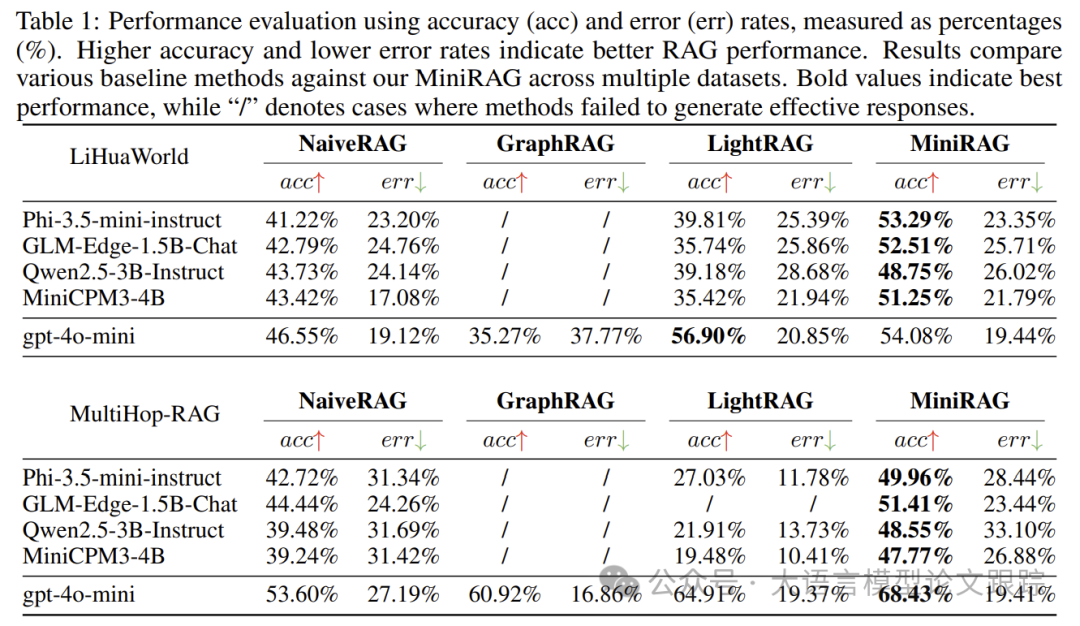
小型語言模型在RAG系統中面臨復雜查詢解釋、多步推理、語義匹配等挑戰。為優化其性能,MiniRAG框架提供了有效的解決方案。
從容大模型1.5在多語言處理、工具調用和Code Interpreter能力上表現出色,是RAG系統中的強勁選擇。
LlamaIndex通過提供上下文增強功能、數據結構化和檢索工具,支持RAG系統構建更高效的智能問答系統。
GTE文本向量可以用于計算句子間的相似度,其模型通過Dual Encoder框架訓練,使得相似度計算更為準確和高效。






