
實(shí)時(shí)航班追蹤背后的技術(shù):在線飛機(jī)追蹤器的工作原理
當(dāng)LLMs達(dá)到一定規(guī)模后,展示出小型模型不具備的能力。這些涌現(xiàn)能力包括上下文學(xué)習(xí)、指令跟隨和多步推理。
上下文學(xué)習(xí)指的是模型在未經(jīng)過特定任務(wù)微調(diào)的情況下能夠理解并響應(yīng)復(fù)雜指令。例如,GPT-3在提供自然語言指令和多個(gè)任務(wù)示例后,能夠生成預(yù)期的輸出。
通過多任務(wù)數(shù)據(jù)集和自然語言描述進(jìn)行微調(diào),LLMs能夠在新任務(wù)中遵循給出的指令執(zhí)行任務(wù)。LaMDA-PT經(jīng)過指令調(diào)優(yōu)后,其在未見過的任務(wù)上的性能顯著優(yōu)于未經(jīng)調(diào)優(yōu)的版本。
小型語言模型通常難以處理復(fù)雜任務(wù),而LLMs通過鏈?zhǔn)剿季S提示策略,利用中間推理步驟有效解決此類任務(wù)。這一策略在超過60B參數(shù)的大模型中尤其有效。
語言模型的發(fā)展經(jīng)歷了從統(tǒng)計(jì)模型到神經(jīng)網(wǎng)絡(luò)模型的演進(jìn),特別是Transformer架構(gòu)的引入,使得大規(guī)模模型的預(yù)訓(xùn)練成為可能。
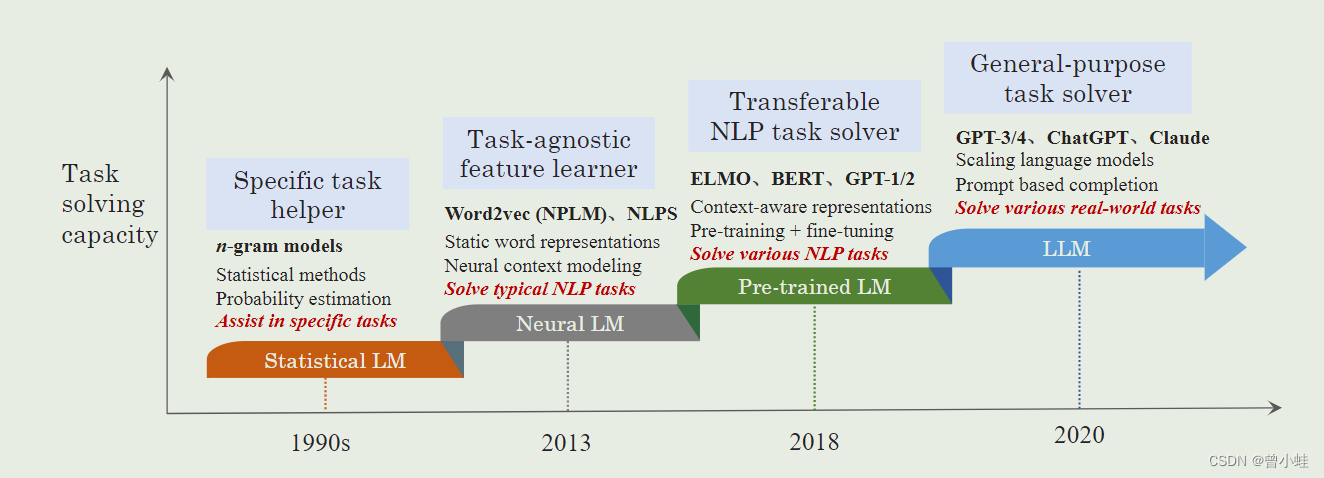
1999年,Bengio等人開發(fā)了早期的神經(jīng)語言模型。隨后,循環(huán)神經(jīng)網(wǎng)絡(luò)(RNNs)及其變種,如長短期記憶(LSTM)和門控循環(huán)單元(GRU)被廣泛應(yīng)用于自然語言處理。
Transformer架構(gòu)的發(fā)明標(biāo)志著自然語言模型發(fā)展中的重要里程碑。與RNNs相比,Transformers具備更好的并行能力,使得在GPU上高效預(yù)訓(xùn)練超大規(guī)模語言模型成為可能。
LLMs包括多個(gè)知名的模型系列,如GPT、LLaMA和PaLM。每個(gè)系列在架構(gòu)和應(yīng)用上都有獨(dú)特的特點(diǎn)和優(yōu)勢(shì)。
構(gòu)建LLMs涉及多個(gè)步驟,包括架構(gòu)選擇、數(shù)據(jù)清洗、模型預(yù)訓(xùn)練、微調(diào)和解碼策略。
目前最廣泛使用的LLM架構(gòu)包括encoder-only、decoder-only和encoder-decoder架構(gòu)。選擇合適的架構(gòu)是構(gòu)建LLMs的首要步驟。
數(shù)據(jù)質(zhì)量對(duì)模型性能至關(guān)重要。數(shù)據(jù)清洗技術(shù)如過濾、去重和預(yù)處理等,對(duì)模型的訓(xùn)練效果有顯著影響。
數(shù)據(jù)過濾旨在提高訓(xùn)練數(shù)據(jù)質(zhì)量。常用方法包括數(shù)據(jù)去噪、處理異常值、平衡類別以及文本預(yù)處理等。
去重是指刪除重復(fù)的數(shù)據(jù)實(shí)例,這有助于提高模型的泛化能力。
預(yù)訓(xùn)練是LLM訓(xùn)練流程的第一步。通常采用自監(jiān)督的方式在大規(guī)模未標(biāo)記文本上進(jìn)行訓(xùn)練。常見的預(yù)訓(xùn)練任務(wù)包括next token prediction和masked language modeling。
LLMs在多個(gè)領(lǐng)域展現(xiàn)出強(qiáng)大能力,但同時(shí)也面臨諸多挑戰(zhàn)。
LLMs廣泛應(yīng)用于自然語言處理、信息檢索、推薦系統(tǒng)和多模態(tài)處理等領(lǐng)域。
在自然語言處理任務(wù)中,LLMs能夠處理復(fù)雜的文本生成、理解和推理任務(wù),甚至超越傳統(tǒng)的小模型。
LLMs可以作為信息檢索模型,通過重新排序候選文檔提高檢索質(zhì)量。
LLMs能夠通過指令微調(diào)實(shí)現(xiàn)個(gè)性化推薦,提升用戶體驗(yàn)。
盡管LLMs在許多方面取得了進(jìn)展,但仍面臨準(zhǔn)確性、偏見、安全性和隱私等挑戰(zhàn)。未來需要開發(fā)更有效的技術(shù),以提高LLMs的能力并確保其安全可靠地應(yīng)用于現(xiàn)實(shí)世界。
研究趨勢(shì)是提出小型語言模型(SLMs)作為對(duì)LLMs的經(jīng)濟(jì)替代,尤其在不需要如此大模型的任務(wù)中。
狀態(tài)空間模型(SSMs)和專家混合(MoE)等新架構(gòu)正在嶄露頭角,為LLMs的發(fā)展提供了新的方向。
多模態(tài)LLMs能夠融合文本、圖像等多種數(shù)據(jù),拓展了模型的應(yīng)用范圍。
大型語言模型在自然語言處理領(lǐng)域的應(yīng)用前景廣闊,但也面臨諸多技術(shù)和倫理挑戰(zhàn)。未來的發(fā)展需要在模型架構(gòu)、訓(xùn)練方法、應(yīng)用安全性等方面持續(xù)探索與改進(jìn)。
問:LLMs的涌現(xiàn)能力是什么?
問:如何提高LLMs的訓(xùn)練效率?
問:LLMs存在哪些安全性問題?
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)鍵.png)