
數據庫表關聯:構建高效數據結構的關鍵
極大似然原理是概率論在統計學中的應用,核心思想是通過對已發生事件概率的最大化來進行參數估計。在一個隨機試驗中,許多事件都有可能發生,概率大的事件發生的概率也大。因此,當某一事件發生,我們有理由認為該事件的發生概率比其他事件要大。
例如,假設一個箱子里有紅色和黑色兩種顏色的球,數量分別為10個和1個。我們并不知道哪種顏色的球為10個,這時我們隨機從箱子里拿出一個球,如果這個球是紅色的,我們就認為盒子里紅球有10個,黑球有1個。
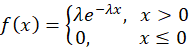
極大似然估計(Maximum Likelihood Estimation, MLE)是一種統計推斷方法,旨在通過給定的數據找到使觀測數據出現概率最大的參數值。極大似然估計法由高斯和費希爾先后提出,是被使用最廣泛的一種參數估計方法,基于直觀的極大似然原理。
極大似然估計的基本思想是利用已知的樣本結果信息,反推最有可能導致這些樣本結果出現的模型參數值。換句話說,極大似然估計提供了一種給定觀察數據來評估模型參數的方法,即:“模型已定,參數未知”。通過若干次試驗,觀察結果,利用試驗結果得到某個參數值能夠使樣本出現的概率為最大。
似然函數是一種關于統計模型中參數的函數,表示模型參數中的似然性,用 L 表示。給定輸出 x 時,關于參數 θ 的似然函數 L(θ|x) 在數值上等于給定參數 θ 后變量 x 的概率。
似然性(likelihood)與概率(possibility)同樣可以表示事件發生的可能性大小,但是二者有著很大的區別:

假設有一個罐子,里面有黑白兩種顏色的球,數目多少不知。我們想知道罐中白球和黑球的比例,但不能把罐中的球全部拿出來數。我們可以通過抽樣來估計罐中黑白球的比例。假如在一百次抽樣中,有七十次是白球,請問罐中白球所占的比例最有可能是多少?
通過極大似然估計,我們可以假設罐中白球的比例是 p,那么黑球的比例就是 1-p。因此,我們可以通過概率計算得出白球的比例。
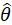
假設我們要統計全國人民的年均收入,收入服從正態分布,但該分布的均值與方差未知。我們可以選取一個城市或鄉鎮的人口收入,作為我們的觀察樣本結果。通過最大似然估計來獲取正態分布的參數。
最小二乘法主要用于線性回歸模型,而最大似然估計適用于更廣泛的統計模型。兩者在處理誤差分布假設上有所不同,最小二乘法假設誤差為正態分布,而最大似然估計不受此限制。
貝葉斯估計利用先驗分布和觀測數據進行參數估計,而最大似然估計僅依賴于觀測數據。貝葉斯估計能處理參數的不確定性,但計算復雜度較高。
最大似然估計在機器學習、經濟學、生物統計學等領域有廣泛應用。例如,在機器學習中用于模型參數的優化;在經濟學中用于市場分析和定價模型的參數估計;在生物統計學中用于基因組數據的分析。
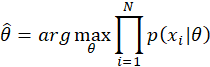
問:最大似然估計與貝葉斯估計有什么區別?
問:在什么情況下使用最大似然估計?
問:最大似然估計是否總是無偏的?
問:最大似然估計如何處理多參數模型?
問:最大似然估計的計算復雜度如何?




