
如何調(diào)用 Minimax 的 API
開源視頻生成模型為公眾提供了創(chuàng)新的機會,尤其是對于那些想要深入了解視頻生成技術或進行二次開發(fā)的研究人員和開發(fā)者。Hunyuan Video 的開源不僅縮小了閉源和開源模型之間的差距,還加速了社區(qū)探索的步伐。
與其他視頻生成模型相比,Hunyuan Video 在運動動力學方面表現(xiàn)尤為出色。通過與全球領先的視頻生成模型,如 Gen-3 和 Luma 1.6 的比較,該模型在整體滿意度方面達到最高,尤其是在運動表現(xiàn)和細節(jié)捕捉上。
通過 Hunyuan Video,可以生成各種風格的視頻場景,從真實電影鏡頭到動畫風格的畫面,滿足多樣化的創(chuàng)作需求。


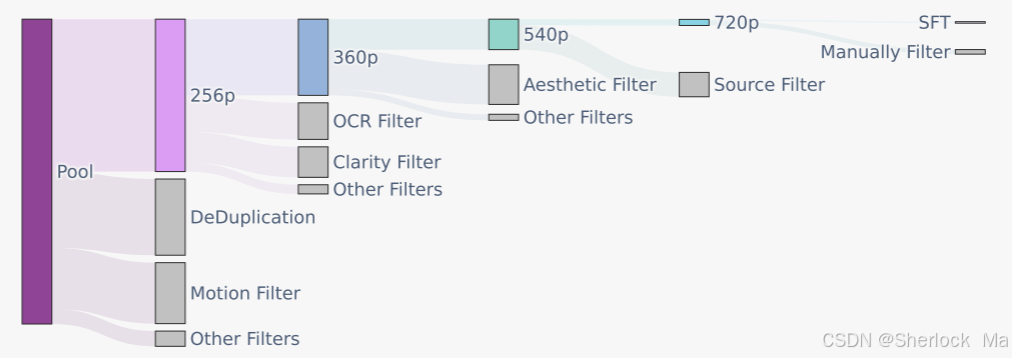
Hunyuan Video 使用圖像-視頻聯(lián)合訓練策略,數(shù)據(jù)采集包括人物、動物、景觀等多種素材,經(jīng)過嚴格的空間質(zhì)量和美學標準篩選,確保訓練數(shù)據(jù)的高質(zhì)量。
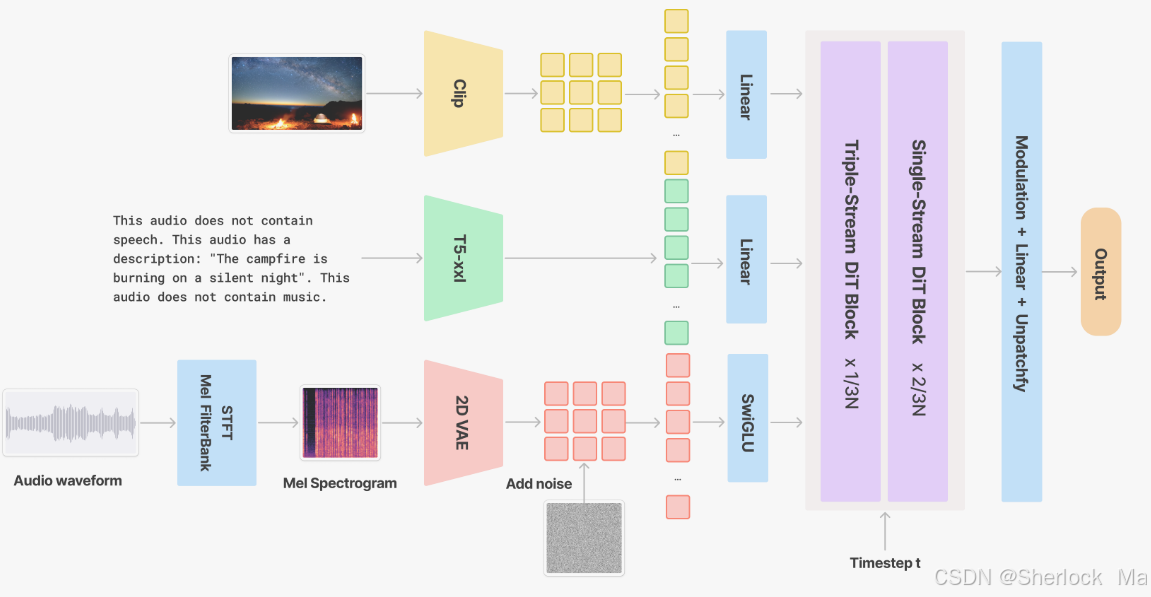
Hunyuan Video 使用 3D-VAE 來壓縮視頻和圖像,支持視頻和圖像的同時處理。采用從低分辨率到高分辨率的訓練策略,結(jié)合 L1 重建損失、感知損失和 GAN 對抗損失,提升視頻重建質(zhì)量。
V2A 模塊通過整合同步聲音效果和背景音樂,增強視頻內(nèi)容的表現(xiàn)力。采用變分自動編碼器(VAE)進行音頻波形的潛在空間編碼,結(jié)合視覺與文本特征提取,確保多模態(tài)信息的融合與對齊。
I2V 任務是指將圖像作為視頻的第一幀,根據(jù)字幕生成匹配的視頻。通過人臉和身體檢測器過濾訓練數(shù)據(jù),采用漸進式微調(diào)策略,增強模型在肖像領域的表現(xiàn)力。

通過插入?yún)⒖紙D像的潛像,Hunyuan Video 實現(xiàn)可控的化身動畫。此功能允許使用顯式驅(qū)動信號(如語音、表情、姿勢模板)以及文本提示進行控制。

下載源碼后,按照以下步驟配置 conda 環(huán)境,確保 flash attention 與 torch 版本匹配。
conda env create -f environment.yml
conda activate HunyuanVideo
python -m pip install -r requirements.txt
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.5.9.post1官方提供的 Docker 鏡像可以簡化環(huán)境配置,適合需要快速部署的用戶。
wget https://aivideo.hunyuan.tencent.com/download/HunyuanVideo/hunyuan_video_cu12.tar
docker load -i hunyuan_video.tar
docker image ls
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged docker_image_tag使用 sample_video.py 腳本生成視頻樣本,支持多種參數(shù)配置。
cd HunyuanVideo
python3 sample_video.py
--video-size 720 1280
--video-length 129
--infer-steps 50
--prompt "A cat walks on the grass, realistic style."
--flow-reverse
--use-cpu-offload
--save-path ./results是的,Hunyuan Video 可以通過其先進的模型架構(gòu)和數(shù)據(jù)過濾技術生成高動態(tài)范圍的視頻,確保在不同光照條件下的視覺質(zhì)量。
可以使用官方提供的 Docker 鏡像,并使用 –use-cpu-offload 參數(shù)減少對 GPU 的依賴,從而在低性能計算機上運行。
是的,Hunyuan Video 的提示重寫模塊支持多語言輸入,并將其轉(zhuǎn)換為模型偏好的標準化提示。
由于 Hunyuan Video 是開源項目,用戶可以根據(jù)相關開源協(xié)議進行商業(yè)用途,但需遵循協(xié)議中的限制和條款。
可以通過調(diào)整生成參數(shù)(如視頻長度、分辨率、采樣步數(shù)等)以及使用高質(zhì)量的訓練數(shù)據(jù)來優(yōu)化生成的視頻質(zhì)量。





