
豆包 Doubao Image API 價格全面解析
Open-Sora 是由北京大學和兔展科研團隊推出的開源項目,旨在通過開源原則推動視頻生成技術的發展。它基于 Diffusion Transformer(DiT)架構,使用華為開源的 PixArt-α 高質量文本到圖像生成模型,并通過添加時間注意力層擴展為視頻生成。Open-Sora 提供了一個簡化且用戶友好的平臺,致力于高效制作高質量視頻。Open-Sora GitHub 官網

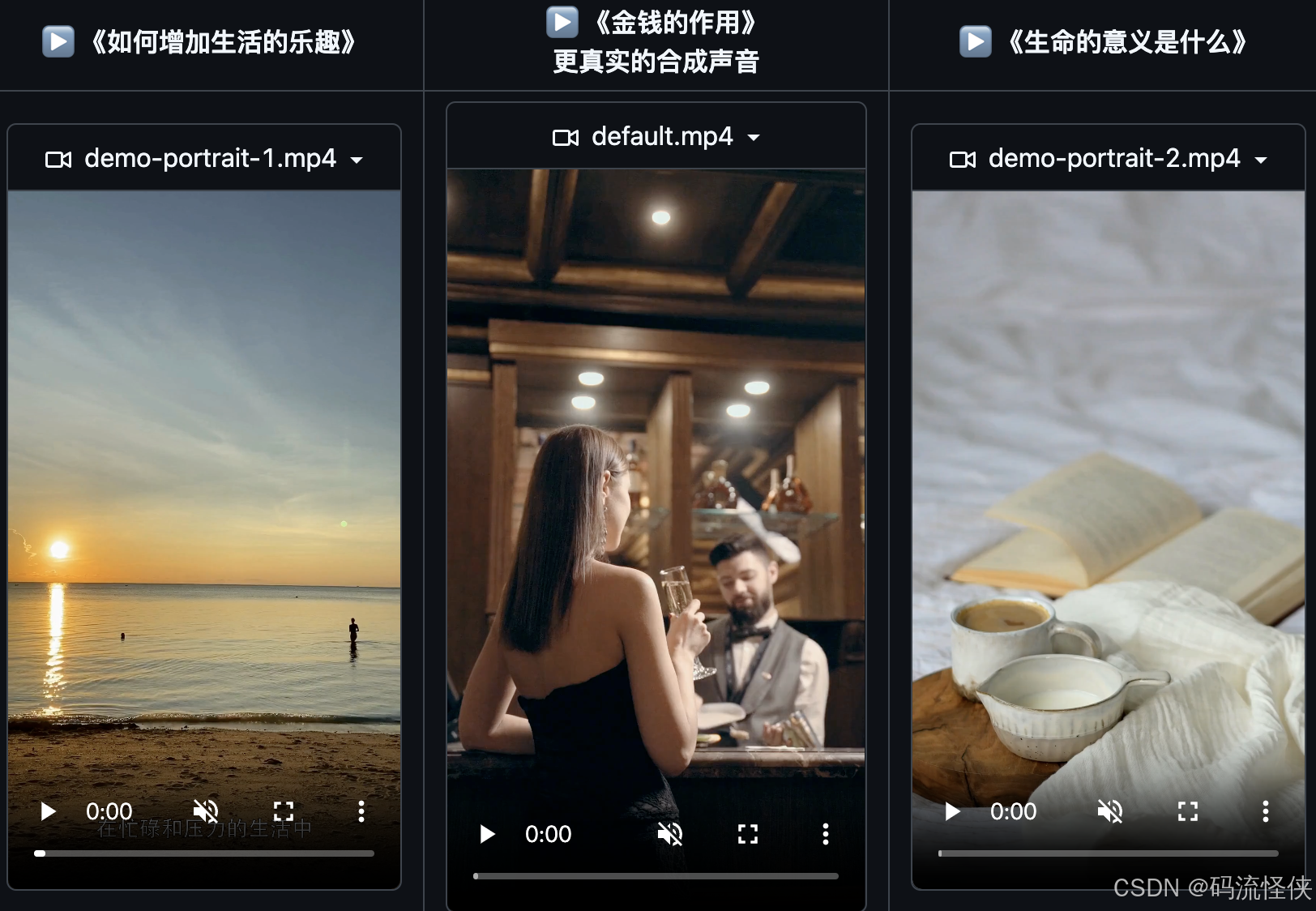
MoneyPrinterTurbo 是一個 Python 開發的開源工具,旨在通過自動化生成短視頻加速內容生產。結合了圖像處理、文本轉語音 (TTS)、視頻編輯等功能,支持 OpenAI、moonshot、Azure、gpt4free、one-api 等多種 AI 模型接入,滿足不同用戶的需求。用戶可以快速制作符合社交媒體平臺要求的短視頻。MoneyPrinterTurbo GitHub
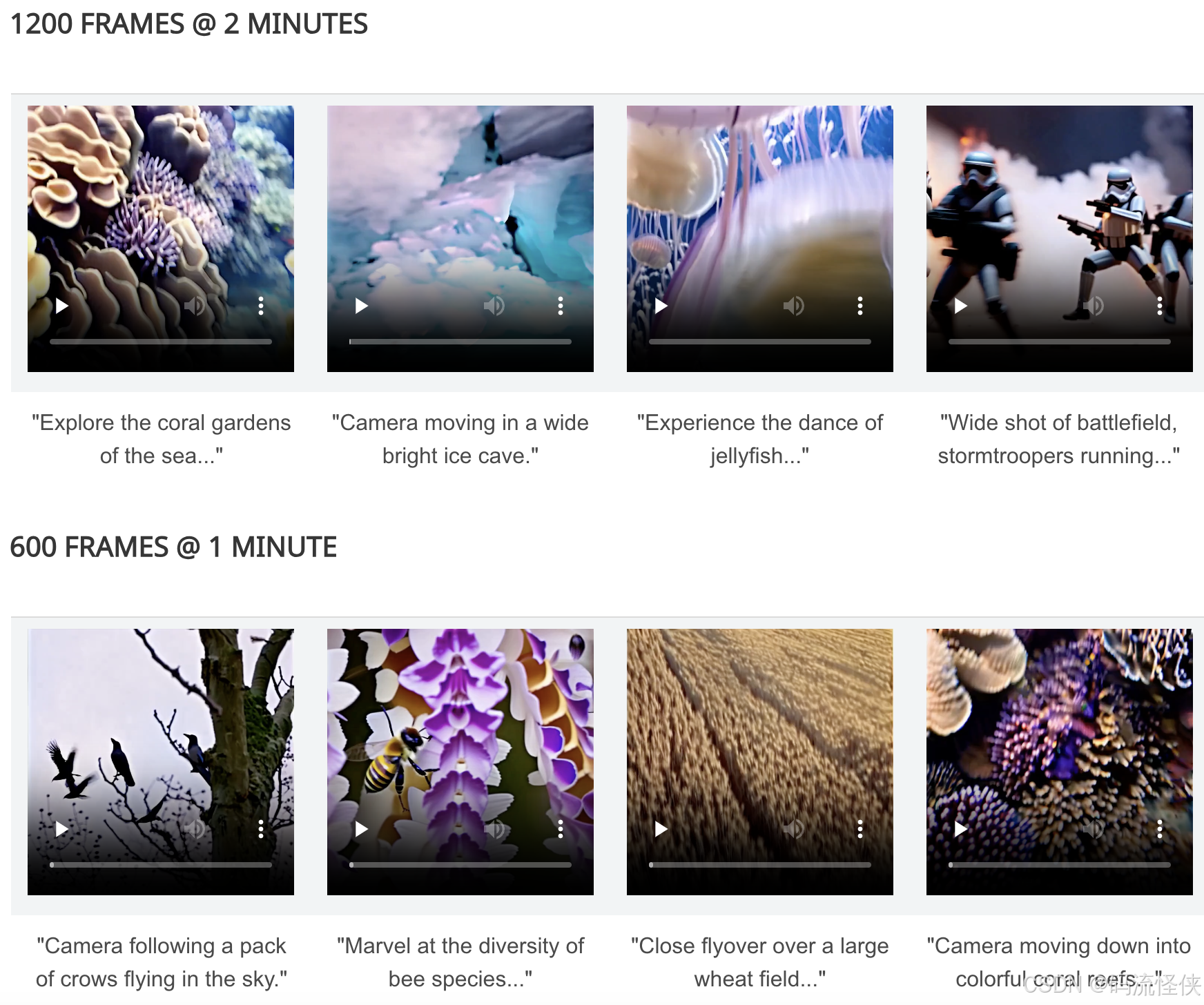
StreamingT2V 是由 PicsArt AI 研究團隊推出的 AI 視頻生成模型,能夠從文本生成長達 1200 幀、時長為 2 分鐘的長視頻。通過引入條件注意模塊(CAM)、外觀保持模塊(APM)以及隨機混合方法,StreamingT2V 實現了長視頻的流暢生成,確保時間上的連貫性和與文本描述的緊密對齊。StreamingT2V GitHub 官網
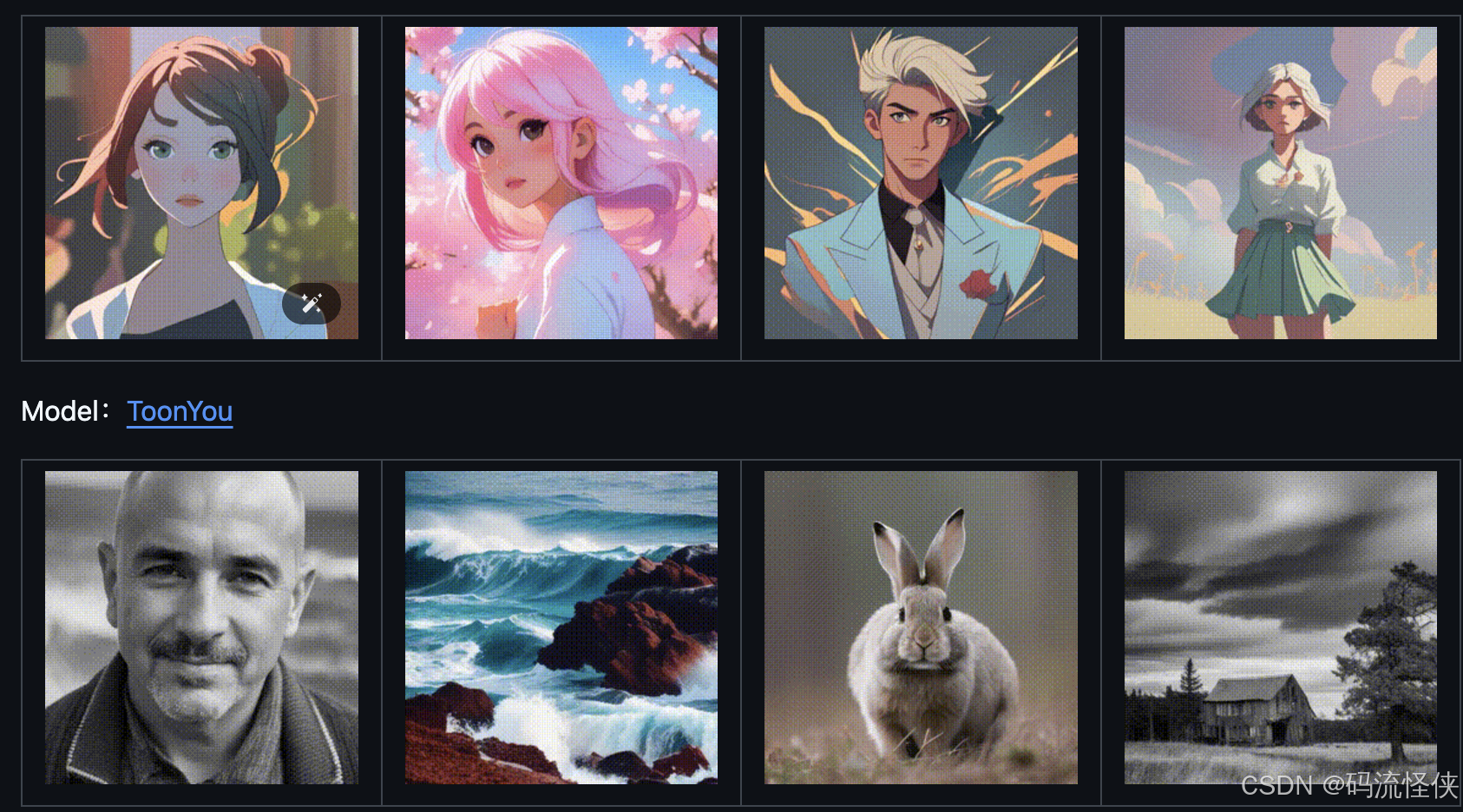
AnimateDiff 是一個強大的 AI 視頻生成框架,能夠將個性化的文本到圖像(T2I)模型擴展為動畫生成器。通過從大規模視頻數據集中學習到的運動先驗知識,作為 Stable Diffusion 文生圖模型的插件,允許用戶將靜態圖像轉換為動態動畫。AnimateDiff GitHub 官網
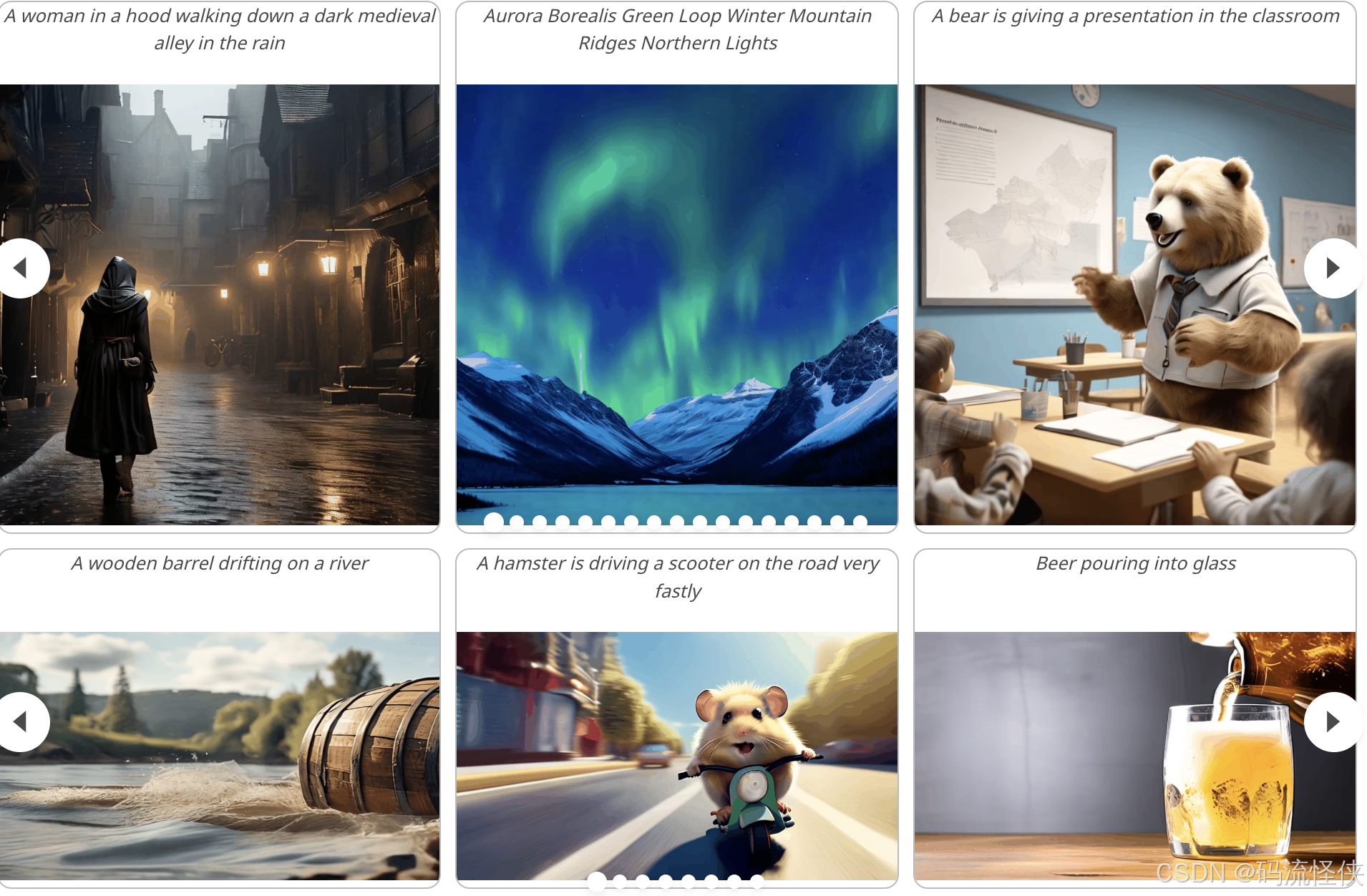
StoryDiffusion 是由南開大學和字節跳動合作推出的開源 AI 故事創作項目,專注于從文本描述生成具有一致性的圖像和視頻序列。通過結合一致性自注意力和語義運動預測器,為視覺故事生成領域提供了新的探索方向。StoryDiffusion GitHub 官網

Video-LaVIT 是一種創新的多模態預訓練方法,旨在賦予大型語言模型(LLMs)理解和生成視頻內容的能力。通過有效地將視頻分解為關鍵幀和時間運動,解決了大規模預訓練中視頻的時空動態建模的挑戰。Video-LaVIT GitHub 官網
Hunyuan Image 作為私人 AI 助手在圖像生成領域的應用潛力巨大。隨著技術的不斷發展,它將為用戶提供更為個性化和高效的圖像生成解決方案。未來,Hunyuan Image 可以在更多領域發揮作用,如娛樂產業、教育領域,以及各種需要圖像生成的應用場景。通過不斷優化模型架構和融合多模態技術,Hunyuan Image 將繼續引領圖像生成技術的發展潮流。
問:Hunyuan Image 如何提升圖像生成效率?
問:是否可以將 Hunyuan Image 應用于視頻生成?
問:Hunyuan Image 對于教育領域有何應用?
問:如何保障 Hunyuan Image 的生成內容質量?
問:Hunyuan Image 的未來發展方向是什么?





