
中文命名實(shí)體識(shí)別(Named Entity Recognition, NER)初探
本項(xiàng)目利用了C#語(yǔ)言在Windows平臺(tái)上的高效性和易用性,通過(guò)本地化的語(yǔ)音識(shí)別庫(kù)實(shí)現(xiàn)離線語(yǔ)音識(shí)別,從而避免了網(wǎng)絡(luò)延遲和不穩(wěn)定性的問(wèn)題。我們優(yōu)化了識(shí)別算法,以提高識(shí)別速度和響應(yīng)時(shí)間,讓用戶(hù)能夠快速獲得準(zhǔn)確的文字輸出。
語(yǔ)音識(shí)別的核心在于將聲音信號(hào)轉(zhuǎn)換為文本信息,這需要處理信號(hào)的采集、分析和轉(zhuǎn)換。這一過(guò)程包括特征提取、聲學(xué)模型匹配和語(yǔ)言模型的結(jié)合。在我們的工具中,這些步驟都在本地完成,以確保數(shù)據(jù)的安全性和處理的高效性。
C#作為一種面向?qū)ο蟮木幊陶Z(yǔ)言,具有強(qiáng)大的庫(kù)支持和易于調(diào)試的特性,使得開(kāi)發(fā)高效的桌面應(yīng)用程序變得更加簡(jiǎn)單。利用C#,開(kāi)發(fā)者可以輕松調(diào)用Windows API,進(jìn)行底層的音頻處理和數(shù)據(jù)管理。
在會(huì)議場(chǎng)景中,傳統(tǒng)的記錄方式效率低且容易遺漏重要信息。我們的工具可以實(shí)時(shí)將會(huì)議發(fā)言轉(zhuǎn)換為文字記錄,便于后期整理和分析。這不僅提高了記錄的準(zhǔn)確性,還為記錄員節(jié)省了大量時(shí)間。
通過(guò)語(yǔ)音輸入生成文字筆記,可以極大地提高記錄效率。特別是在快節(jié)奏的工作環(huán)境中,語(yǔ)音轉(zhuǎn)文字的功能讓記錄工作變得輕松而高效。
在教育場(chǎng)景中,教師可以使用語(yǔ)音識(shí)別工具將課堂講解內(nèi)容轉(zhuǎn)換為文字,這不僅有助于學(xué)生的復(fù)習(xí),還可以作為教學(xué)資料歸檔,方便未來(lái)的教學(xué)調(diào)整和改進(jìn)。
對(duì)于某些需要語(yǔ)音命令控制的嵌入式系統(tǒng)或應(yīng)用,離線語(yǔ)音識(shí)別工具可以在沒(méi)有網(wǎng)絡(luò)連接的情況下完成命令的識(shí)別和執(zhí)行,增強(qiáng)了系統(tǒng)的獨(dú)立性和可靠性。
離線識(shí)別無(wú)需網(wǎng)絡(luò)連接即可完成,確保了用戶(hù)數(shù)據(jù)的安全性和隱私保護(hù)。用戶(hù)不必?fù)?dān)心網(wǎng)絡(luò)中斷帶來(lái)的識(shí)別失敗,從而提高了工具的可靠性。
我們的工具專(zhuān)門(mén)針對(duì)短語(yǔ)音進(jìn)行了優(yōu)化,能夠在極短的時(shí)間內(nèi)完成識(shí)別任務(wù)。這種優(yōu)化使得它非常適合需要快速響應(yīng)的應(yīng)用場(chǎng)景,如實(shí)時(shí)翻譯和語(yǔ)音控制。
工具支持用戶(hù)根據(jù)自己的需求配置識(shí)別庫(kù)。這種靈活性使得用戶(hù)可以根據(jù)不同的應(yīng)用場(chǎng)景調(diào)整識(shí)別參數(shù),確保最佳的識(shí)別效果。
我們的項(xiàng)目經(jīng)過(guò)多次優(yōu)化,識(shí)別速度快,響應(yīng)迅速,即使在高負(fù)荷的情況下,也能提供準(zhǔn)確的文字輸出。這種特性使得工具在實(shí)際應(yīng)用中獲得了用戶(hù)的一致好評(píng)。
我們非常歡迎開(kāi)發(fā)者們貢獻(xiàn)代碼、提出改進(jìn)建議或報(bào)告問(wèn)題。您可以通過(guò)GitHub的Issue或Pull Request功能與我們進(jìn)行交流。我們期待與您共同完善這款工具,讓其在更多場(chǎng)景中發(fā)揮作用。
本項(xiàng)目采用開(kāi)源許可證,具體信息請(qǐng)查看項(xiàng)目中的LICENSE文件。
對(duì)于需要在線語(yǔ)音識(shí)別的場(chǎng)景,我們可以使用Microsoft Azure的語(yǔ)音識(shí)別服務(wù)。Azure提供了一套強(qiáng)大的API,可以進(jìn)行實(shí)時(shí)語(yǔ)音轉(zhuǎn)文字。
首先,用戶(hù)需要有一個(gè)Microsoft Azure賬號(hào),并創(chuàng)建語(yǔ)音服務(wù)資源。在Azure門(mén)戶(hù)中創(chuàng)建資源后,可以獲取服務(wù)密鑰和區(qū)域信息。這些信息將用于配置語(yǔ)音識(shí)別服務(wù)。
在項(xiàng)目中引用Azure Cognitive Services的語(yǔ)音識(shí)別庫(kù)是實(shí)現(xiàn)在線語(yǔ)音識(shí)別的第一步。用戶(hù)可以通過(guò)NuGet包管理器,搜索并安裝Microsoft.CognitiveServices.Speech包。
以下是一個(gè)簡(jiǎn)單的代碼示例,演示如何使用Azure語(yǔ)音服務(wù)進(jìn)行語(yǔ)音轉(zhuǎn)文字:
using Microsoft.CognitiveServices.Speech;
// 初始化語(yǔ)音配置
var config = SpeechConfig.FromSubscription("YourSubscriptionKey", "YourRegion");
// 創(chuàng)建語(yǔ)音識(shí)別器
using var recognizer = new SpeechRecognizer(config);
// 開(kāi)始識(shí)別
var result = await recognizer.RecognizeOnceAsync();
// 輸出結(jié)果
Console.WriteLine(result.Text);Azure的優(yōu)勢(shì)在于其強(qiáng)大的云計(jì)算能力和高準(zhǔn)確率的識(shí)別結(jié)果,適合需要大量語(yǔ)音處理的場(chǎng)景。
Whisper是一款支持多語(yǔ)言的語(yǔ)音轉(zhuǎn)文字工具,不僅可以處理視頻和音頻文件,還支持實(shí)時(shí)語(yǔ)音的自動(dòng)采集和錄制。它支持多種輸出格式,包括純文本、帶時(shí)間戳的文本、字幕格式等。
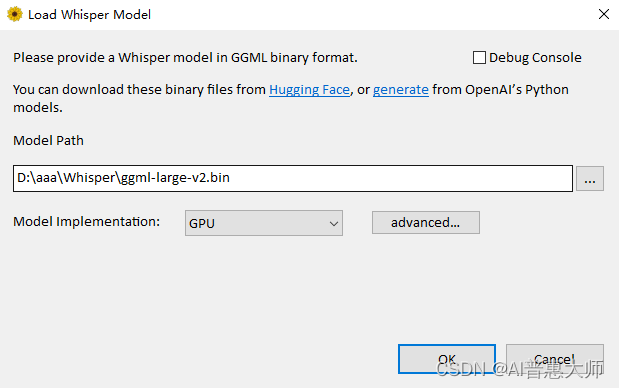
在使用Whisper之前,需要先下載并配置語(yǔ)言模型。用戶(hù)可以通過(guò)提供的鏈接下載模型文件,配置簡(jiǎn)單,使用方便。
用戶(hù)可以選擇要轉(zhuǎn)換的視頻或音頻文件,設(shè)置輸出格式,然后開(kāi)始轉(zhuǎn)換。支持的格式包括純文本、帶時(shí)間戳的文本、字幕等,滿足不同的應(yīng)用需求。

用戶(hù)可以通過(guò)選擇麥克風(fēng)設(shè)備進(jìn)行實(shí)時(shí)語(yǔ)音采集,工具會(huì)自動(dòng)記錄并轉(zhuǎn)換為文字。
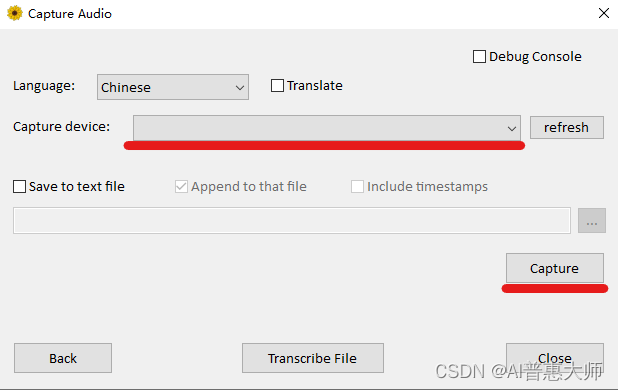
為了提高語(yǔ)音轉(zhuǎn)文字的準(zhǔn)確性,用戶(hù)可以?xún)?yōu)化音頻的質(zhì)量,使用高質(zhì)量的麥克風(fēng)設(shè)備,或者通過(guò)配置更適合的語(yǔ)言模型來(lái)提高識(shí)別效果。
離線語(yǔ)音識(shí)別工具可以在本地完成所有的識(shí)別過(guò)程,無(wú)需將數(shù)據(jù)上傳到云端,這大大提高了數(shù)據(jù)的安全性和隱私保護(hù)。
選擇合適的語(yǔ)音識(shí)別工具需要考慮應(yīng)用場(chǎng)景、語(yǔ)音文件的類(lèi)型、需要的功能(如支持的格式、語(yǔ)言、實(shí)時(shí)處理等)以及工具的易用性和擴(kuò)展性。
語(yǔ)言模型是語(yǔ)音識(shí)別系統(tǒng)中用于理解和處理自然語(yǔ)言的核心組件。它通過(guò)分析和預(yù)測(cè)文字序列,幫助提高語(yǔ)音識(shí)別的準(zhǔn)確度。
C#語(yǔ)音識(shí)別工具主要針對(duì)Windows平臺(tái)進(jìn)行優(yōu)化,但通過(guò)使用.NET Core等跨平臺(tái)技術(shù),部分功能也可以在其他平臺(tái)上實(shí)現(xiàn)。用戶(hù)可以根據(jù)具體需求進(jìn)行調(diào)整和開(kāi)發(fā)。
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)





