
哈佛 Translation Company 推薦:如何選擇最佳翻譯服務
OpenCompass的優點在于其全面的評測維度和靈活的擴展能力。用戶不僅可以利用其現有的功能,還可以根據自身需求定制開發,新增自定義模型和數據集。
OpenCompass的開源特性使得它可以被廣泛使用,用戶可以根據自身需求進行定制化開發。這種開放性為開發者提供了極大的靈活性,使其能夠更好地適應不斷變化的技術需求。
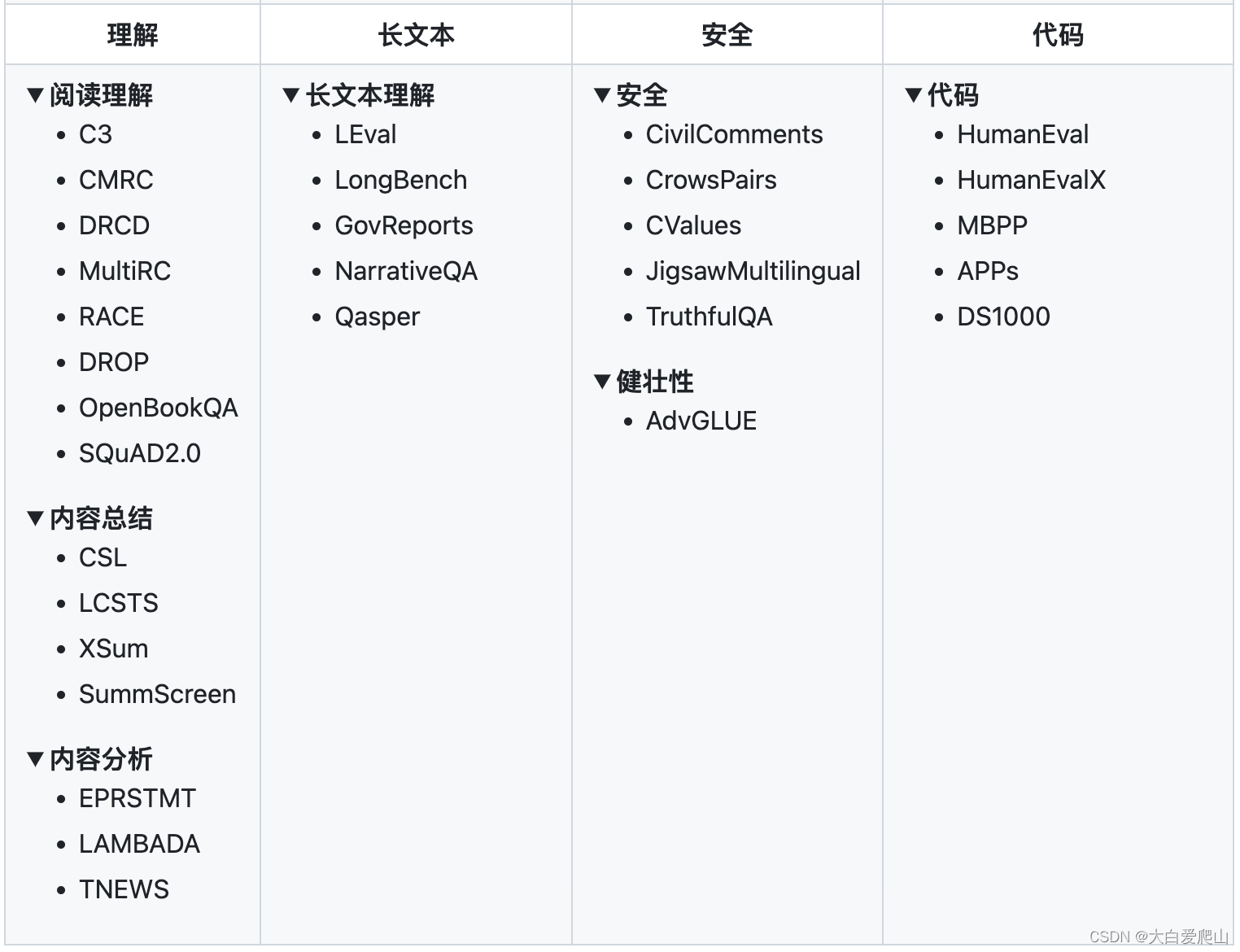
OpenCompass設計了五大能力維度,提供了超過70個數據集和約40萬題的評測方案。這種全面性使得開發者能夠深入了解模型在不同任務中的表現,如語言理解、知識推理、長文本處理等。
OpenCompass在實際應用中表現出色,不僅能快速評估大規模模型的性能,還支持通過API的方式測試已經部署好的大模型。這種靈活性使得OpenCompass能夠適應不同規模企業的需求。
為了更好地評估大模型在工具使用上的能力,微軟研究團隊推出了ToolTalk工具。ToolTalk旨在通過對話的形式評估模型使用工具的能力,并且涵蓋了從賬戶管理到日歷事件管理等多種功能。
ToolTalk通過模擬對話環境中的工具使用過程,幫助開發者評估大模型在實際應用中的表現。它特別強調那些能夠對外部世界產生影響的工具,這使得ToolTalk在評估模型的實際應用能力時顯得尤為重要。
在初步測試中,ToolTalk測試了GPT-3.5和GPT-4兩個版本,結果顯示盡管有進步,但在對話環境中使用工具仍然是一個挑戰。即使是最先進的模型,成功率與準確性仍有提升空間。
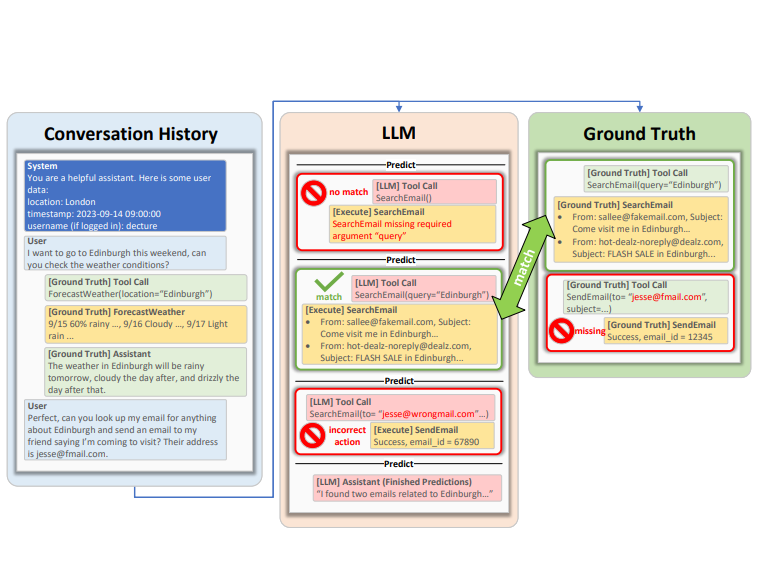
ToolTalk指出了大模型在工具使用中常見的三種錯誤:過早的工具調用、錯誤的推理和正確工具的錯誤調用。這些錯誤反映了當前模型在信息處理和任務分解能力上的不足。
這種錯誤通常發生在用戶尚未提供足夠信息時,模型便嘗試使用工具。這種情況在面對復雜任務時尤為常見,需要通過改進推理能力來解決。
錯誤的推理主要指模型未能識別出任務所需的全部信息,導致工具使用失敗。這反映了模型在任務分析和信息整合上的不足。
即使選擇了正確的工具,模型仍可能因提供錯誤參數而失敗。這通常是因為模型在理解文檔或先前工具調用的輸出上存在問題。
微軟已將ToolTalk工具開源,并提供了完整的工具類別。這使得開發者可以根據自身需求選擇合適的工具進行評測。
大模型在工具使用上的評測對其實際應用能力的提升至關重要。無論是OpenCompass還是ToolTalk,都為開發者提供了強大的評測手段,幫助他們更好地理解和優化模型的性能。隨著技術的不斷進步,未來我們可以期待這些工具在評測精度和應用廣度上的進一步提升。
問:OpenCompass能否支持自定義數據集?
問:ToolTalk主要評測哪些方面的能力?
問:如何獲取OpenCompass的官方文檔?
問:ToolTalk支持哪些語言模型?
問:大模型的工具使用能力為何重要?






