
AI聊天無敏感詞:技術原理與應用實踐
文本是非結構化的信息,要使機器理解文本,首先需要將其轉換為結構化的數據。這通常通過索引化、獨熱編碼和向量表示來實現。
索引化用一個數字來代表一個詞,而獨熱編碼則用二進制位來表示詞,盡管這些方法簡單直觀,但它們無法表達詞語之間的關系,尤其在大語料下會顯得稀疏且占用大量空間。
相比之下,Embedding提供了一種更加緊湊且語義表達能力更強的向量化方法,可以在不同任務中通用。
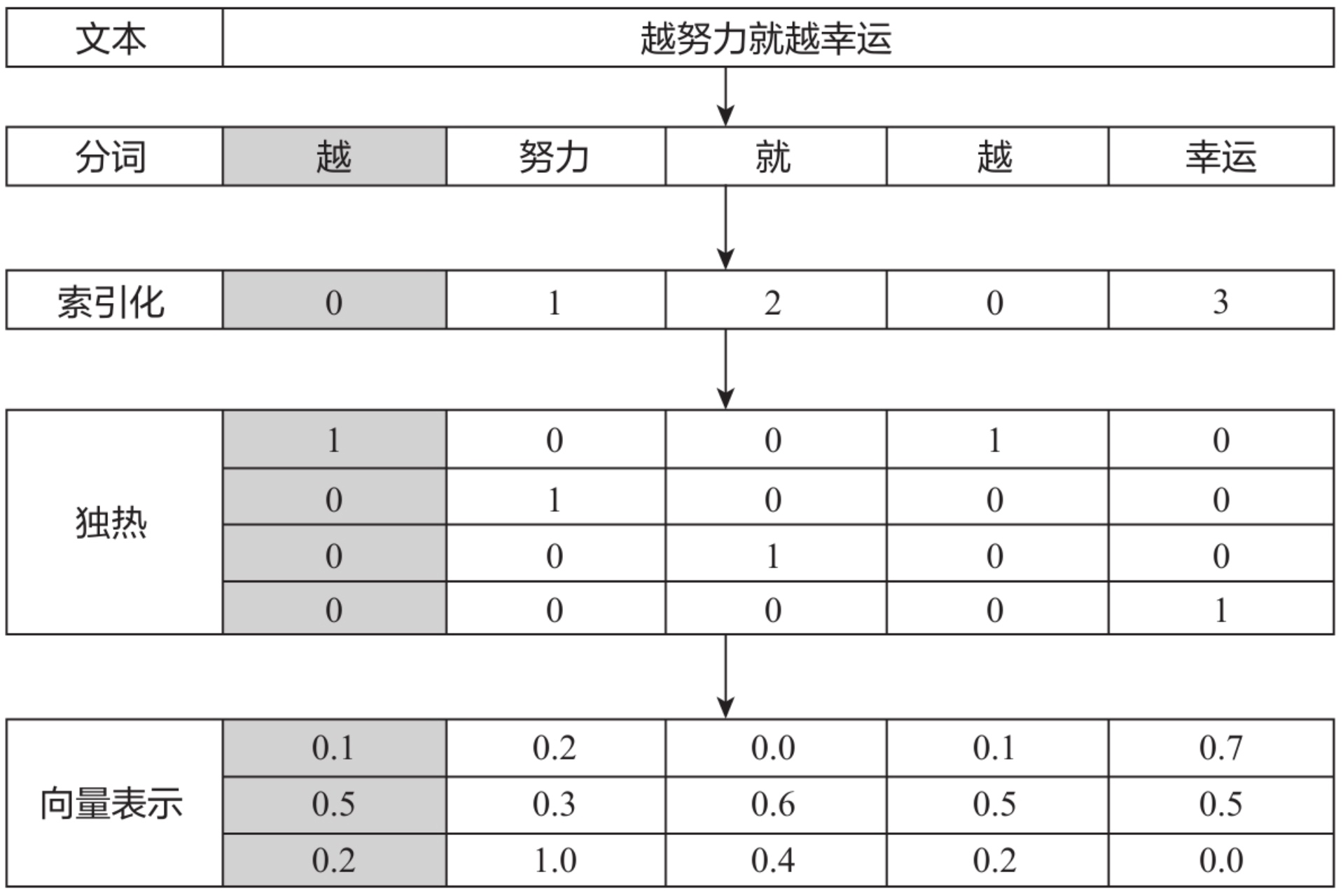
索引化的優點在于其直觀性,因為每個詞都有唯一的數字標識。但缺點在于無法捕獲詞語之間的關系,并且在大語料中會導致數據量巨大。
獨熱編碼可以快速計算和表達能力強,但這種方法在大語料下空間占用大,計算效率低,無法捕捉詞語關系。
相比傳統方法,Embedding通過低維向量表達詞語,不僅節約空間,還能更好地表達詞語之間的關系。
詞嵌入可以將文本通過低維向量來表達,避免了one-hot編碼的高維度問題。這種低維表示使得計算更加高效。
在詞嵌入的向量空間中,語義相似的詞會更接近。這種相似性幫助模型在不同的任務中更好地理解文本。
詞嵌入具有高度的通用性,可以在不同的自然語言處理任務中重復使用,節省了重新訓練的時間和資源。
Embedding的本質是數據壓縮,用較低維度的特征來描述有冗余信息的高維特征。這種壓縮不僅提高了計算效率,還減少了存儲空間。
盡管Embedding通常會丟失一些信息,但這些信息大多是冗余的。例如,在描述智力時,某些身體信息可以被忽略。
Embedding在處理過程中,會舍棄與任務無關的冗余信息,保留關鍵特征以提高模型的性能。
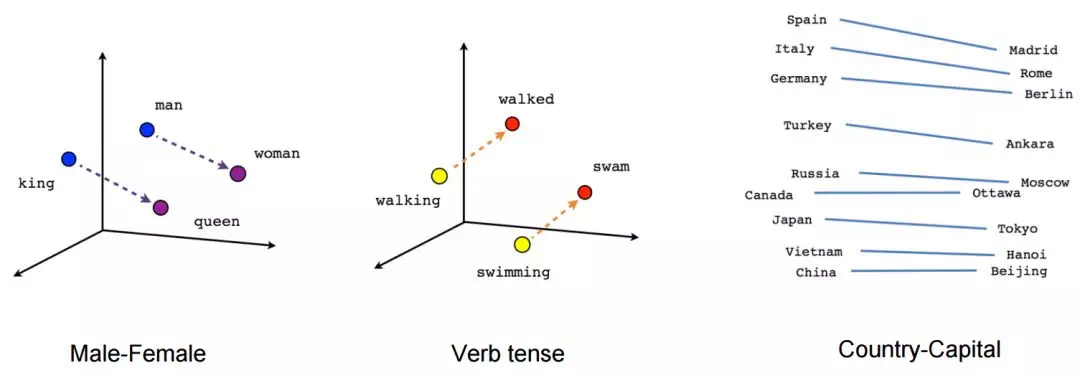
Embedding在向量空間中能夠保持樣本的語義關系。即使是不同的語言,也能通過Embedding找到相似的詞語和短語。
在詞嵌入中,可以通過簡單的向量運算來推導出新的語義關系。例如,巴黎減去法國再加上英格蘭,會接近倫敦的向量。
這種向量關系幫助我們發現詞匯之間的深層語義關系,從而提升機器學習模型的理解能力。
Embedding將自然語言轉化為一串數字,使得文本數據可以被計算和分析。在自然語言處理中,Embedding大幅提升了模型的性能。
Embedding替代了獨熱編碼和協同矩陣,極大地降低了特征的維度和計算復雜度,提升了計算效率。
在訓練中,Embedding可以不斷學習和更新,獲取不同任務的語義信息,從而提升模型的表現。

# 簡單的詞嵌入示例
from gensim.models import Word2Vec
# 訓練模型
sentences = [['吃飯', '喝水'], ['喝水', '健康']]
model = Word2Vec(sentences, min_count=1)
# 查看詞嵌入
print(model.wv['吃飯'])





