
中文命名實(shí)體識(shí)別(Named Entity Recognition, NER)初探
Diffusion Model的生成過程類似于沖洗照片,首先需要一個(gè)起始的噪聲圖像,然后通過多次去噪處理逐步顯現(xiàn)出圖像細(xì)節(jié)。每一步去噪都使用相同的Denoise Model,并通過輸入當(dāng)前的Step數(shù)讓模型判斷噪聲程度,以便進(jìn)行更精細(xì)的去噪操作。
Denoise Model內(nèi)部首先會(huì)通過一個(gè)Noise Predictor模塊預(yù)測(cè)當(dāng)前圖像的噪聲,然后對(duì)初步去噪的圖像進(jìn)行修正,通過進(jìn)一步減去噪聲達(dá)到去噪效果。
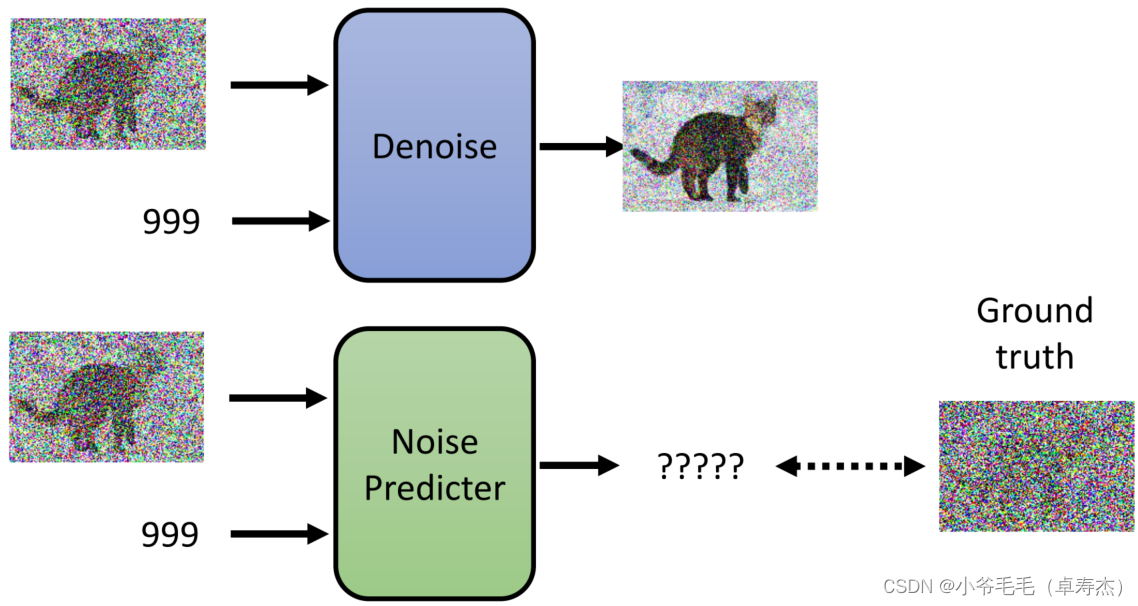
訓(xùn)練Noise Predictor需要利用監(jiān)督學(xué)習(xí)方法,需要有Ground truth噪音作為標(biāo)簽。通過模擬擴(kuò)散過程,隨機(jī)產(chǎn)生噪音并加到原始圖像中,得到一系列加噪后的圖像和對(duì)應(yīng)的Ground truth噪音用于訓(xùn)練。
Diffusion Model還可以用于文本生成圖像,即Text-to-Image。通過將文本信息輸入到Noise Predictor中,模型可以根據(jù)文本提示生成相應(yīng)的圖像。
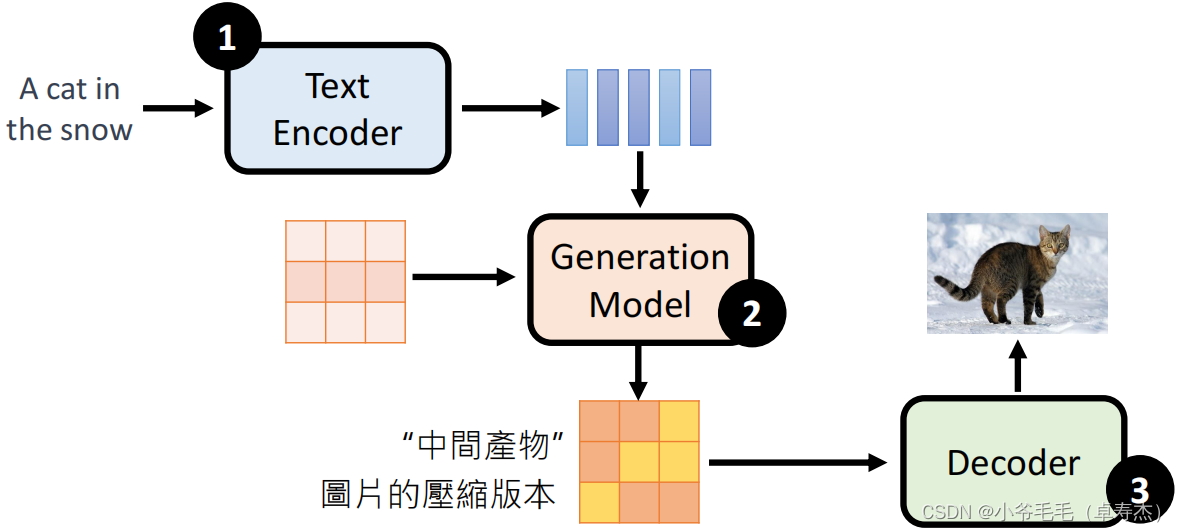
這些模型都使用了Text Encoder、Generation Model和Decoder三個(gè)模塊。首先通過Text Encoder將文本編碼為表征向量,然后通過Generation Model生成圖像表征向量,最后通過Decoder將其解碼為圖像。
Stable Diffusion是一個(gè)開源的Diffusion Model,支持多模態(tài)輸入,使用Denoising U-Net和交叉注意力機(jī)制來生成圖像。它還使用預(yù)訓(xùn)練的通用VAE來處理輸入圖像。
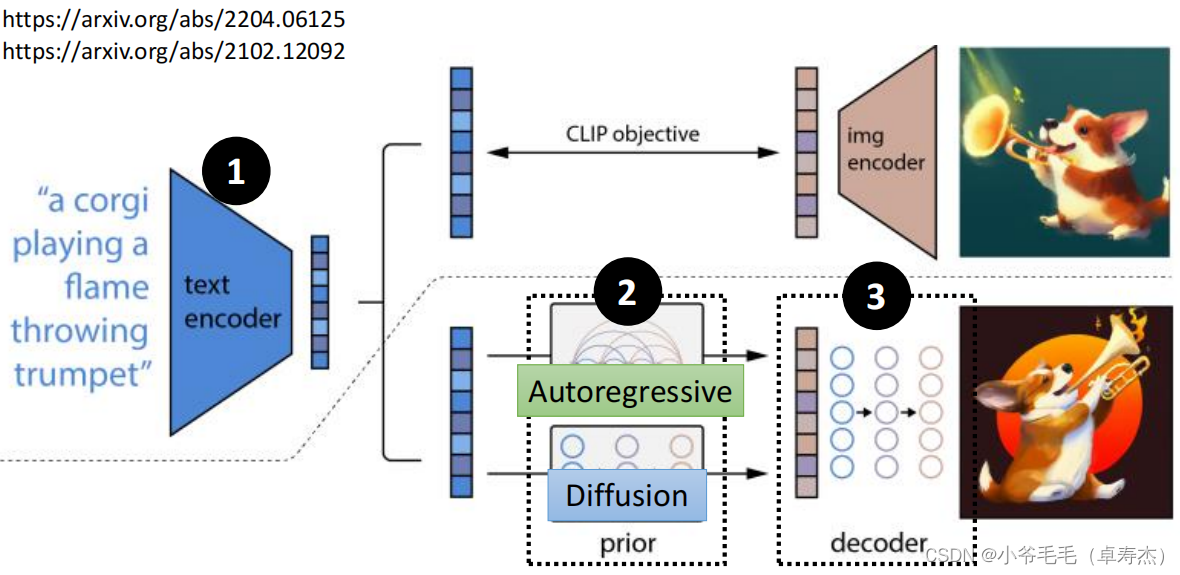
DALL-E利用CLIP方法實(shí)現(xiàn)文本與圖像的對(duì)齊,通過Autoregressive模型或Diffusion生成圖像表征向量,最后通過解碼器生成最終圖像。
Imagen采用T5模型作為文本編碼器,并使用U-Net結(jié)構(gòu)的Text-to-Image Diffusion Model,通過Efficient U-Net優(yōu)化來減少顯存占用和提高推理速度。
在生成特定領(lǐng)域圖像時(shí),Dreambooth和LoRA是兩種有效的方法。Dreambooth通過利用類別的先驗(yàn)保護(hù)損失,生成多樣的實(shí)例,而LoRA則通過優(yōu)化低秩分解矩陣來微調(diào)神經(jīng)網(wǎng)絡(luò)。
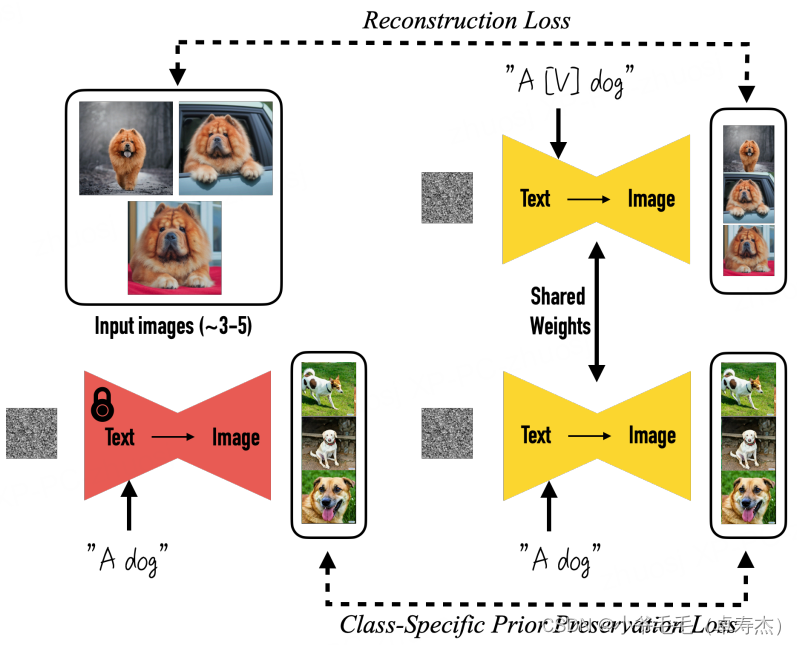
Dreambooth在微調(diào)模型時(shí)同時(shí)輸入特定對(duì)象的名稱和類別的文本提示,并應(yīng)用類別的先驗(yàn)保護(hù)損失,以保持生成圖像的多樣性。
LoRA通過僅優(yōu)化低秩矩陣,使得訓(xùn)練更加高效,并且可以在不影響推理延遲的情況下部署。這種方法與現(xiàn)有的模型訓(xùn)練方法兼容,適合小規(guī)模的概念學(xué)習(xí)。
通過Dreambooth和LoRA微調(diào)Stable Diffusion模型,可以生成出小鵬P7汽車的圖像。在經(jīng)過微調(diào)的模型中,我們可以看到該模型能夠一定程度上學(xué)習(xí)到小鵬P7汽車的外觀特征。

使用開源的Stable Diffusion模型,通過LoRA進(jìn)行微調(diào),能夠生成出與寶可夢(mèng)相關(guān)的卡通形象。這種方法展示了LoRA在生成特定概念圖像中的有效性。
以下是使用Python實(shí)現(xiàn)Diffusion Model的示例代碼:
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1", torch_dtype=torch.float16)
model_path = "souljoy/sd-pokemon-model-lora-zh"
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
pipe.safety_checker = lambda images, clip_input: (images, False)
prompt = "粉色的蝴蝶,小精靈,卡通"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image答:Diffusion Model通過逐步去噪生成圖像,而GANs通過生成器與判別器的對(duì)抗訓(xùn)練生成圖像。Diffusion Model更擅長(zhǎng)生成細(xì)節(jié)豐富的圖像。
答:可以通過優(yōu)化模型結(jié)構(gòu)、減少計(jì)算復(fù)雜度以及使用高效的硬件設(shè)備來提高生成效率。
答:LoRA可以與prefix-tuning等其他方法結(jié)合,通過優(yōu)化低秩矩陣實(shí)現(xiàn)不同任務(wù)的快速切換,適用于多任務(wù)學(xué)習(xí)場(chǎng)景。
通過對(duì)Diffusion Model的深入探討和實(shí)際應(yīng)用示例,我們可以看到其在圖像生成領(lǐng)域的巨大潛力。隨著技術(shù)的不斷發(fā)展,Diffusion Model將在更多的應(yīng)用場(chǎng)景中發(fā)揮重要作用。
對(duì)比大模型API的內(nèi)容創(chuàng)意新穎性、情感共鳴力、商業(yè)轉(zhuǎn)化潛力
一鍵對(duì)比試用API 限時(shí)免費(fèi)





