
數(shù)據(jù)庫表關(guān)聯(lián):構(gòu)建高效數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵
梯度下降法在凸優(yōu)化問題中能夠保證找到全局最優(yōu)解,而在非凸問題中,至少可以找到局部最優(yōu)解。然而,該方法在處理大規(guī)模數(shù)據(jù)集時,每次迭代所需的計算量可能非常大,從而導(dǎo)致優(yōu)化速度緩慢。
隨機(jī)梯度下降法(SGD)是一種對經(jīng)典梯度下降法的改進(jìn)。與梯度下降法需要遍歷所有樣本不同,SGD每次僅使用一個樣本來更新參數(shù)。這種方法極大地提高了計算效率,使得算法在處理大規(guī)模數(shù)據(jù)集時依舊保持較快的收斂速度。
SGD速度較快,適用于需要頻繁更新的場景,但其缺點(diǎn)是目標(biāo)函數(shù)波動較大,可能導(dǎo)致收斂不穩(wěn)定。因此,通常需要調(diào)整學(xué)習(xí)率以減小波動。
小批量梯度下降法(Mini-batch Gradient Descent)結(jié)合了梯度下降法和隨機(jī)梯度下降法的優(yōu)點(diǎn)。它通過在每次迭代中使用一個小批量的數(shù)據(jù)進(jìn)行更新,兼顧了計算效率和更新穩(wěn)定性。

批量大小的選擇對模型的優(yōu)化效果有顯著影響。較大的批量大小可以減少梯度的方差,使得訓(xùn)練過程更穩(wěn)定,而較小的批量大小則可以更快地更新參數(shù)。
學(xué)習(xí)率是梯度下降算法中的一個關(guān)鍵參數(shù),決定了每次參數(shù)更新的步長。過大的學(xué)習(xí)率可能導(dǎo)致算法發(fā)散,而過小的學(xué)習(xí)率則可能導(dǎo)致收斂速度過慢。
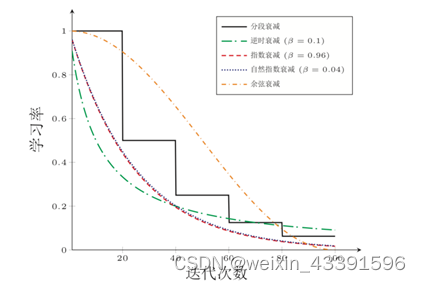
為了更好地控制收斂速度和精度,通常會使用學(xué)習(xí)率衰減策略,如逆時衰減、分段常數(shù)衰減、指數(shù)衰減等。這些策略可以根據(jù)迭代次數(shù)動態(tài)調(diào)整學(xué)習(xí)率,以平衡收斂速度和穩(wěn)定性。
逆時衰減(Inverse Time Decay)
分段常數(shù)衰減(Piecewise Constant Decay)
指數(shù)衰減(Exponential Decay)
周期性學(xué)習(xí)率調(diào)整是一種在訓(xùn)練過程中動態(tài)調(diào)整學(xué)習(xí)率的方法,以幫助模型跳出局部最優(yōu)解。常見的方法包括循環(huán)學(xué)習(xí)率和帶熱重啟的隨機(jī)梯度下降法(SGDR)。
通過在一定范圍內(nèi)周期性地增大和減小學(xué)習(xí)率,幫助模型擺脫局部極小值的困境。
在一定周期后重新初始化學(xué)習(xí)率,并從先前的參數(shù)繼續(xù)優(yōu)化。

傳統(tǒng)的梯度下降法面臨許多挑戰(zhàn),如收斂速度慢、容易陷入局部最優(yōu)解、所有參數(shù)使用相同的學(xué)習(xí)率等。為此,研究者提出了多種優(yōu)化算法,如動量法、Nesterov加速梯度法(NAG)、Adagrad、Adadelta、RMSprop和Adam。
動量法通過結(jié)合上一次的梯度更新,減少目標(biāo)函數(shù)的震蕩,提高收斂速度。而NAG則在動量法的基礎(chǔ)上,進(jìn)一步優(yōu)化了梯度預(yù)測。
Adam是一種結(jié)合了動量法和RMSprop的自適應(yīng)學(xué)習(xí)率優(yōu)化算法。它存儲了過去梯度的指數(shù)衰減平均值,并通過偏差校正來提高收斂效率。
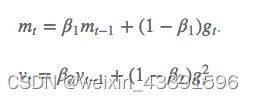
Adam結(jié)合了動量法和RMSprop的優(yōu)點(diǎn),適用于稀疏數(shù)據(jù),能夠快速收斂,并在訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)時表現(xiàn)尤為出色。
在神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中,優(yōu)化算法的選擇至關(guān)重要。此外,還可以通過以下技巧提升訓(xùn)練效果:
隨機(jī)洗牌數(shù)據(jù):在每個epoch之前隨機(jī)打亂訓(xùn)練數(shù)據(jù),提高模型的泛化能力。
批量歸一化(Batch Normalization):在網(wǎng)絡(luò)的每一層之間進(jìn)行歸一化,減少對初始參數(shù)的依賴,并提高訓(xùn)練速度。
添加隨機(jī)噪聲到梯度:有助于模型跳出局部最優(yōu)解。
問:什么是梯度下降法?
問:學(xué)習(xí)率在梯度下降法中有什么作用?
問:如何選擇合適的優(yōu)化算法?
問:什么是動量法?
問:如何實現(xiàn)學(xué)習(xí)率衰減?
數(shù)據(jù)庫表關(guān)聯(lián):構(gòu)建高效數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵

企業(yè)知識庫開源:探索開源知識庫系統(tǒng)的最佳選擇

探索拉格朗日乘數(shù)法:從基礎(chǔ)到應(yīng)用
伊利諾伊州天氣:極寒天氣的影響與應(yīng)對措施

冪:從古代數(shù)學(xué)到現(xiàn)代科學(xué)的演變

經(jīng)緯度怎么看:詳細(xì)操作教程
當(dāng)前天氣:技術(shù)實現(xiàn)與應(yīng)用指南
魯棒性與過擬合的關(guān)系:從理論到實踐

實時航班追蹤背后的技術(shù):在線飛機(jī)追蹤器的工作原理