
ChatGPT生態系統的安全漏洞導致第三方網站賬戶和敏感數據泄露
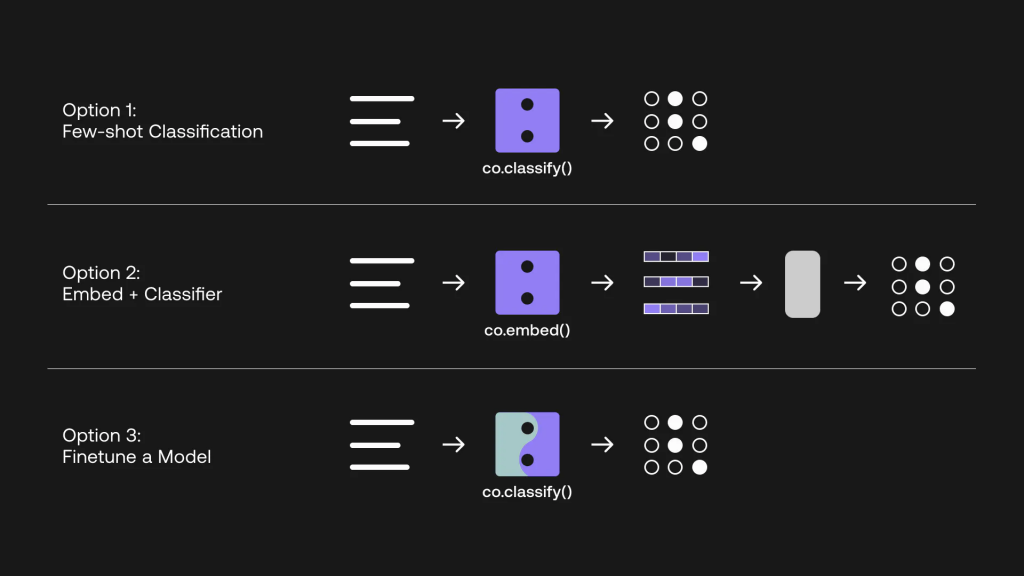
Figure 1您可以根據需要選擇最合適的選項
以下是三個選項的概述:

Figure 2使用 Cohere API 構建文本分類器的三種方法
本文展示了一個 Python 筆記本的片段,你可以在下面找到完整版本。
在演示中,我們將以航空公司旅行信息系統 (ATIS) 意圖分類數據集的一個子集為例[資料來源]。 該數據集由進入航空公司旅行查詢系統的查詢組成。 下面是幾個示例數據點:
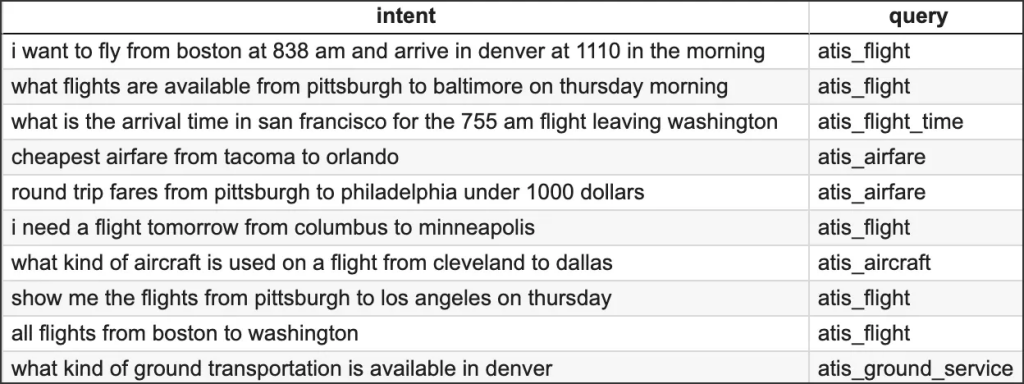
Figure 3幾個示例數據
我們的目標是訓練分類器,使其能夠從以下八個類別中預測新客戶咨詢的類別:
atis_flight
atis_airfare
atis_airline
atis_ground_service
atis_abbreviation
atis_quantity
atis_aircraft
atis_flight_time為了便于演示,我們將只選取數據集中的一小部分: 總共 1000 個數據點。 首先,我們需要創建一個用于構建分類器的訓練數據集和一個用于測試分類器性能的測試數據集。 我們將分別使用 800 和 200 個數據點來創建這兩個數據集。
# Load the dataset to a dataframe
df = pd.read_csv("atis_subset.csv")
# Split the dataset into training and test portions
X, y = df["query"], df["intent"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=200, random_state=21)為了準備接下來的章節,讓我們來設置 Cohere 的 Python SDK 客戶端。
import cohere
co = cohere.Client(“api_key”)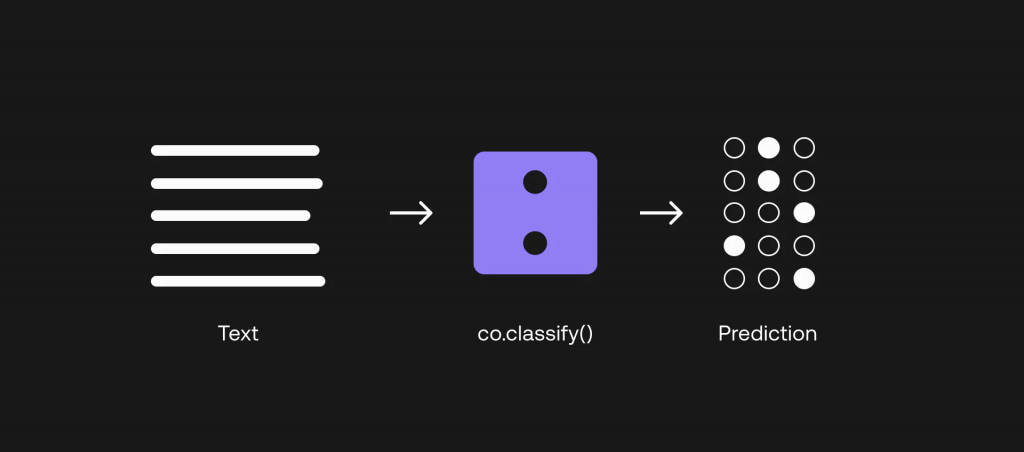
對于 LLM,我們的一個選擇是通過少量分類來建立分類器。 這里的 “少量 “指的是,我們只需為每個類別提供少量示例,分類器就能正常工作。 之所以能做到這一點,是因為 LLM 是一個非常龐大的模型,已經用大量文本數據進行了預訓練,捕捉到了語言的深層語境。 現在需要做的是,向模型提示我們需要它執行的特定任務,這就是我們現在要做的。
讓我們來看看如何做到這一點。 在 Cohere 的分類終端中,”訓練 “數據集被稱為示例。 每個類的示例數最少為 2 個,每個示例包括一個文本(在我們的例子中為查詢)和一個標簽(在我們的例子中為標簽)。query label
讓我們為每個類別創建 6個示例,這樣總共就有 48個示例。 我們不需要之前創建的所有訓練數據點,因為其他兩個選項都需要這些數據點。
# Set the number of examples per category
EX_PER_CAT = 6
# Create list of examples containing texts and labels - sample from the dataset
ex_texts, ex_labels = [], []
for intent in intents:
y_temp = y_train[y_train == intent]
sample_indexes = y_temp.sample(n=EX_PER_CAT, random_state=42).index
ex_texts += X_train[sample_indexes].tolist()
ex_labels += y_train[sample_indexes].tolist()現在我們已經準備好了示例,可以通過 Python SDK 構建分類器。 首先,我們使用 Example 模塊按照 SDK 要求的格式整理示例。 接下來,我們通過 co.classify() 方法調用 Classify 端點。 代碼如下 Example co.classify()
# Collate the examples via the Example module
from cohere.responses.classify import Example
examples = list()
for txt, lbl in zip(ex_texts,ex_labels):
examples.append(Example(txt,lbl))
# Classification function
def classify_text(texts, examples):
classifications = co.classify(
inputs=texts,
examples=examples
)
return [c.predictions[0] for c in classifications]現在分類器已經準備就緒,我們可以對 100 個數據點進行測試,并得到類別預測結果。
# Create batches of texts and classify them
BATCH_SIZE = 90 # The API accepts a maximum of 96 inputs
y_pred = []
for i in range(0, len(X_test), BATCH_SIZE):
batch_texts = X_test[i:i+BATCH_SIZE].tolist()
y_pred.extend(classify_text(batch_texts, examples))我們將使用準確率和 F1 分數來評估分類器的測試數據集(有關如何評估分類器的更多信息,請點擊此處)。Accuracy F1-score
# Compute metrics on the test dataset
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred, average='weighted')我們獲得了 83.00% 的準確率和 84.66% 的 F1 分數。 考慮到我們只為每個類別提供了六個示例,這一結果令人印象深刻。 但肯定還有改進的余地。Accuracy F1-score
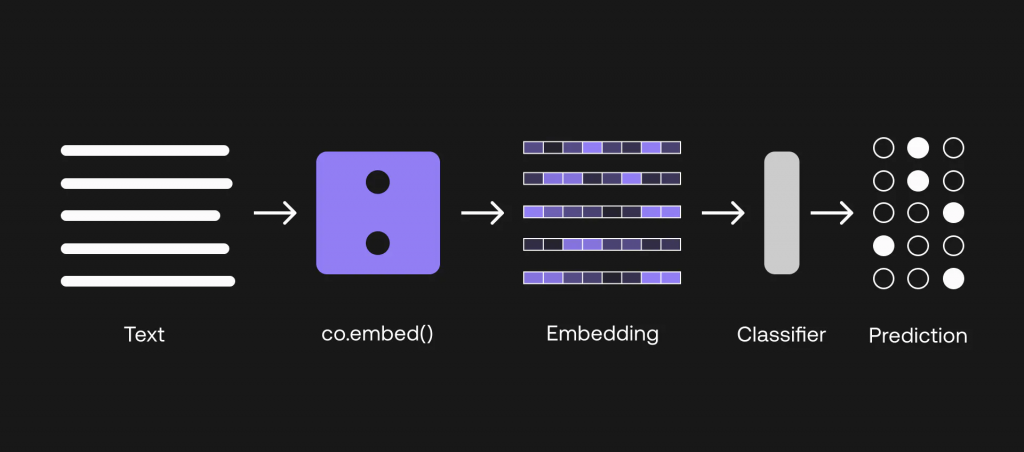
Figure 4使用嵌入式端點構建自己的分類器
雖然我們在上一節中取得了不錯的結果,但有時我們需要更多。 要知道,我們在演示中只使用了一小部分數據,而在現實世界中,這將更具挑戰性。 因此,我們仍然需要找到改進的方法。
比方說,你實際上掌握了相當數量的訓練數據集。 在剩下的兩個選項中,我們將研究如何利用這些數據點來構建一個性能可能更好的分類器。
在本節中,我們將討論選項 2,即如何利用嵌入式端點建立分類器。 請注意,本節確實需要對機器學習有一點了解才能建立模型。
這一次,我們將使用之前準備的全部 800 個訓練數據點。 第一步是將訓練輸入和測試輸入(即航空公司查詢)轉化為嵌入。
嵌入式到底是什么? 您可以在本文中了解更多相關信息,但總的來說,它是一組數字,代表了一段文本的含義,捕捉了其上下文和語義。 在我們的案例中,我們使用的是中型模型,該模型生成的嵌入式大小為 2096。 因此,對于我們輸入的每個文本,都會得到一個由 2096 個數字組成的嵌入,如下所示:medium
[0.20641953, 0.35582256, 0.6058123, -0.058944624, 0.8949609, 1.2956009, 1.2408538, -0.89241934, -0.56218493, -0.5521631, -0.11521566, 0.9081634, 1.662983, -0.9293592, -2.3170912, 1.177852, 0.35577637, ... ]為此,我們通過 co.embed() 方法調用嵌入端點,選擇分類作為輸入_類型參數。 然后,我們將嵌入轉化為一個數組,下一步就需要用到這個數組了。 它看起來如下:co.embed() classification input_type
# Get embeddings
def embed_text(text):
output = co.embed(
model='embed-english-v3.0',
input_type="classification",
texts=text)
return output.embeddings
# Embed and prepare the inputs
X_train_emb = np.array(embed_text(X_train.tolist()))
X_test_emb = np.array(embed_text(X_test.tolist()))下一步,我們將使用這些嵌入作為輸入建立一個分類模型。 我們將使用支持向量機(SVM)算法,利用 scikit-learn 庫中的實現。 該方法稱為 SVC,您可以在此閱讀相關信息。SVC
下面展示的是我們的實現片段(完整版在筆記本中)。 總之,我們將訓練數據集擬合到模型中,然后使用這個訓練有素的模型來預測測試數據集的類別。
# Initialize the model
svm_classifier = SVC(class_weight='balanced')
# Fit the training dataset to the model
svm_classifier.fit(X_train_emb, y_train_le)
# Generate classification predictions on the test dataset
y_pred_le = svm_classifier.predict(X_test_emb)我們現在要做的是將嵌入作為特征來訓練機器學習模型。 然后,該模型將學習包含輸入文本語義信息的特征與提供每個輸入文本所屬類別信息的標簽之間的映射。features features labels
我們將再次使用準確率和 F1 分數來評估分類器在該測試數據集上的表現。 這次,我們獲得了 91.50% 的準確率和 91.01% 的 F1 分數。AccuracyF1 score AccuracyF1 score
這比以前的方法有所改進。 但我們還能做得更好嗎?
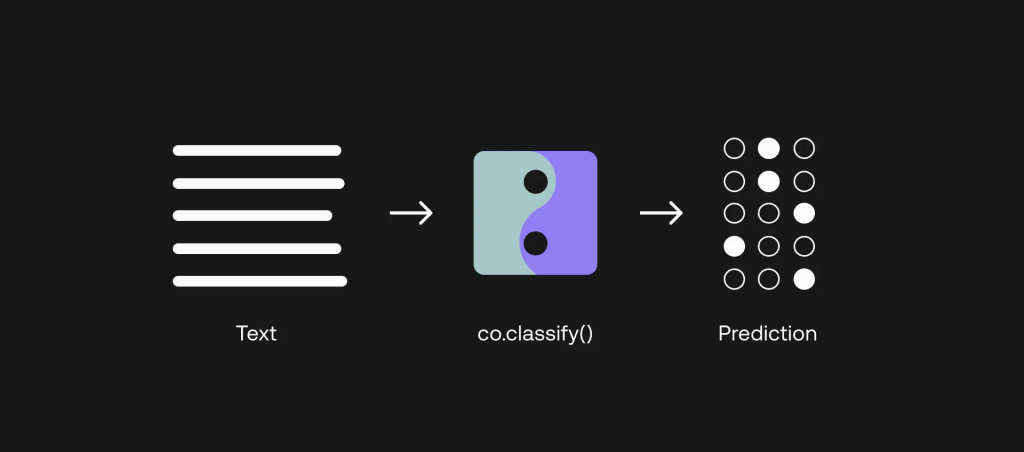
Figure 5通過分類端點微調模型
使用 Cohere API 進行微調是一個強大的概念,原因就在這里。 在上一節中,我們使用 Embed 端點的輸出建立了一個分類器,但請注意,我們使用的仍然是一個基準模型。 但通過微調,你實際上可以改變模型本身,并根據你的任務進行定制。
這就意味著,你所得到的是一個經過微調的自定義模型,它在特定任務中表現出色,并有可能優于我們所見過的前兩種方法。 這就是我們本節要做的。
數據點越多越好,但作為一個例子,我們將使用之前準備的 800 個訓練數據點對模型進行微調。
本文檔包含如何微調表示模型的分步指南,表示模型與嵌入端點背后的模型是同一種模型。 因此,本文將不涉及微調步驟,并假設您已經準備好了微調模型。
當你對表示模型進行微調時,在幕后發生的事情是,模型會將同一類別的示例拉近,反之,將不同類別的示例拉遠。 它是通過學習輸入(即嵌入)和輸出(標簽)之間的關系,捕捉數據中的模式來做到這一點的。
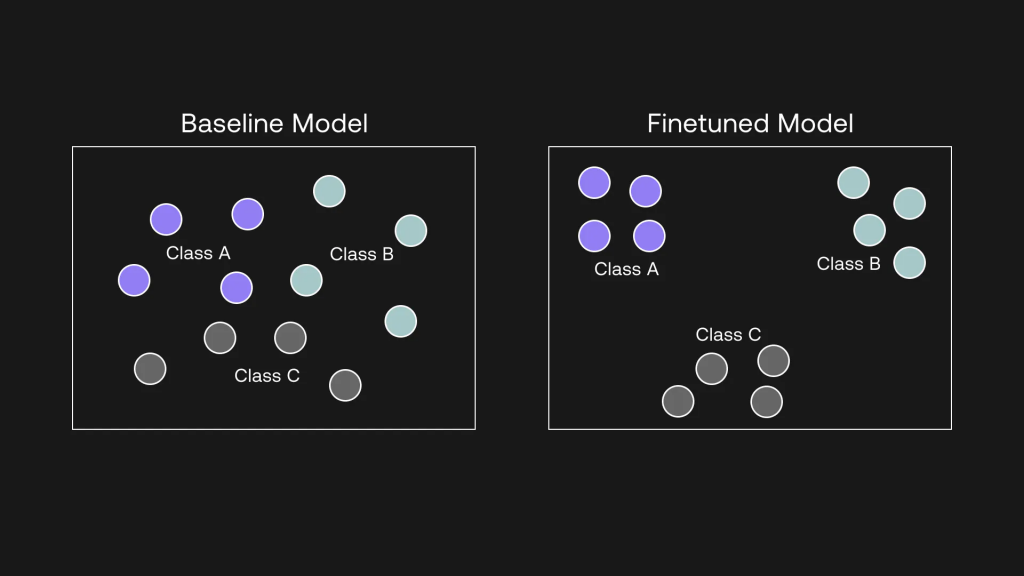
Figure 6微調將相似的例子拉近,將不相似的例子推遠
對模型進行微調后,可從 Playground 或直接從 Cohere 控制面板獲取模型 UUID。
要使用這個經過微調的模型,可以通過我們之前使用的 co.classify() 方法調用相同的分類端點。 調用端點的方法是一樣的,只是在參數中輸入的是微調模型 UUID,而不是基準版本。 下面是代碼片段,如你所見,只需幾行代碼。co.classify()
# Classification function
def classify_text_finetune(texts, examples):
classifications = co.classify(
model='eeba7d8c-61bd-42cd-a6b5-e31db27403cc-ft',
inputs=texts,
examples=examples
)
return [c.predictions[0] for c in classifications]
# Create batches of texts and classify them
BATCH_SIZE = 90 # The API accepts a maximum of 96 inputs
y_pred = []
for i in range(0, len(X_test), BATCH_SIZE):
batch_texts = X_test[i:i+BATCH_SIZE].tolist()
y_pred.extend(classify_text_finetune(batch_texts, examples))請注意,由于模型已通過訓練數據集進行了微調,因此現在調用 “分類 “端點無需再像第一個選項那樣輸入示例。 現在整個實現過程更加簡潔。
重要的是,這也意味著,對于不太熟悉機器學習的開發人員來說,處理嵌入式的所有復雜性都已消除。 現在一切都發生在后臺,你需要知道的只有兩個步驟,僅此而已。
這一次,我們獲得了 94.50% 的準確率和 94.53% 的 F1 分數。 這是一個明顯的提升!
我希望這些示例能讓您了解不同選項之間的比較。 我們看到了少鏡頭分類如何消除了建立訓練數據集的需要,也看到了微調如何帶來最佳性能。 當然,在不同的數據集和任務下,情況并不總是如此,但大體上,這是你所期望的模式。
最重要的是,在使用分類端點時,您的控制水平非常重要。
如果您的訓練數據有限,但又需要以最小的代價快速建立文本分類器,那么 “少量嘗試 “選項可以幫助您實現這一目標,并獲得可觀的性能。
如果最大限度地提高性能是最重要的,那么您可以建立一個數據集,并在此基礎上對模型進行微調,而無需處理復雜的機器學習問題。
最后,如果你確實想親自動手學習機器學習,并想自己決定最適合你的任務的分類算法,你可以選擇嵌入選項。
本文翻譯源自:https://cohere.com/blog/classify-three-options







