鍵.png)
node.js + express + docker + mysql + jwt 實(shí)現(xiàn)用戶管理restful api
RAG通過引入非參數(shù)記憶訪問來增強(qiáng)LLM的參數(shù)記憶能力
為了充分發(fā)揮RAG的潛力,使LLM的響應(yīng)能夠切實(shí)地建立在可靠數(shù)據(jù)基礎(chǔ)之上,我們需要超越簡單的索引、檢索、增強(qiáng)和生成的實(shí)現(xiàn)方式。要實(shí)現(xiàn)這一目標(biāo),首先需要建立有效的性能度量標(biāo)準(zhǔn)。RAG評估為建立系統(tǒng)性能基準(zhǔn)提供了重要依據(jù),進(jìn)而為后續(xù)的優(yōu)化提供了方向。
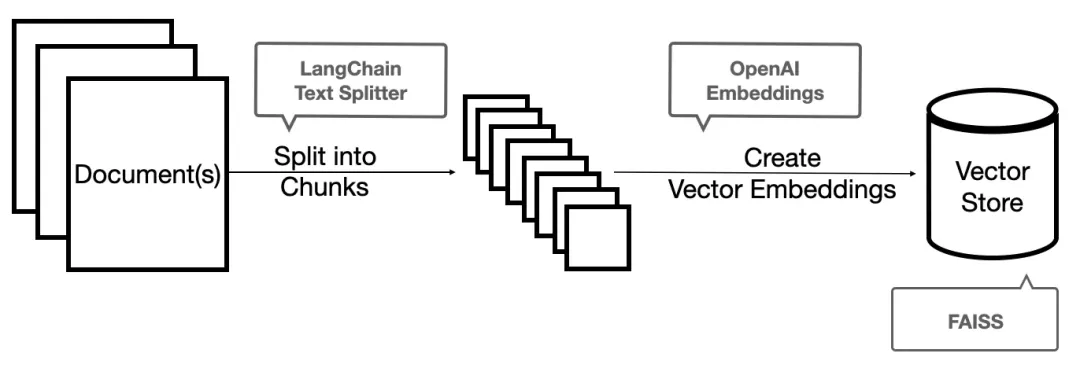
構(gòu)建RAG概念驗(yàn)證(PoC)管道的復(fù)雜度相對較低。借助LangChain和LlamaIndex等工具,這一過程已經(jīng)變得相對簡單。通過簡短的訓(xùn)練和有限樣本的驗(yàn)證即可實(shí)現(xiàn)初步功能。但是為了提高系統(tǒng)的魯棒性,在真實(shí)反映生產(chǎn)環(huán)境用例的數(shù)據(jù)集上進(jìn)行全面測試至關(guān)重要。值得注意的是RAG管道本身也可能產(chǎn)生幻覺。從宏觀角度來看,RAG系統(tǒng)存在三個(gè)主要的失效點(diǎn):
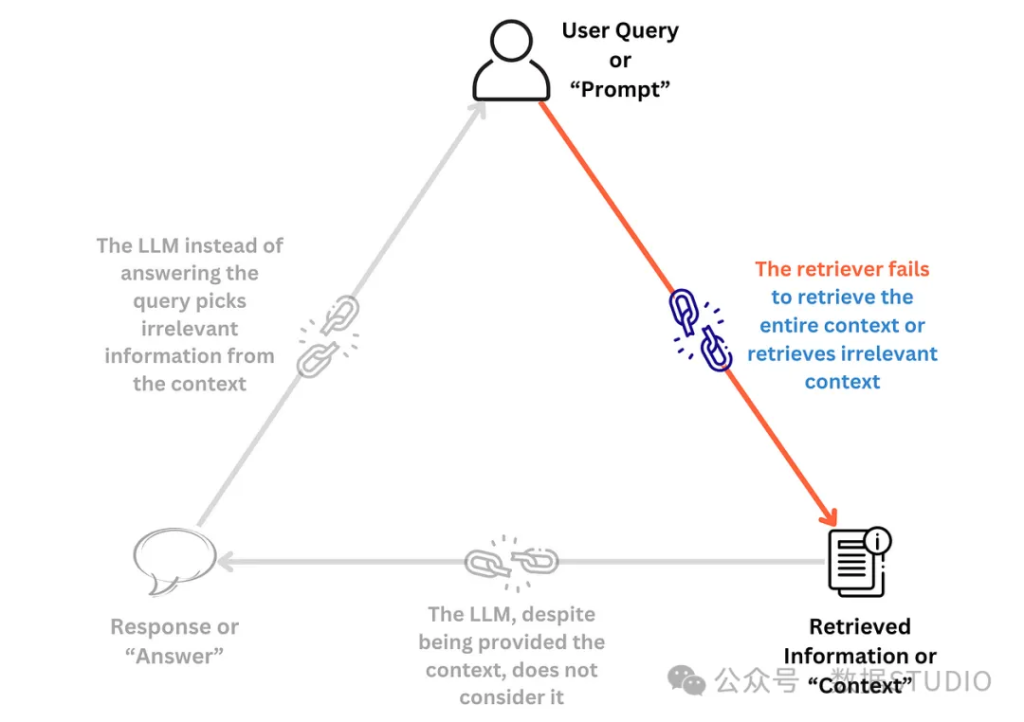
本文將重點(diǎn)討論幾個(gè)專注于評估第一個(gè)失效點(diǎn)的指標(biāo) —— “檢索器未能檢索到完整或相關(guān)上下文”。換言之這些指標(biāo)旨在評估檢索器的質(zhì)量。
用于評估RAG系統(tǒng)的指標(biāo)可以大致分為三類:
RAG的檢索組件可以獨(dú)立評估確定檢索器滿足用戶查詢的能力。我們將詳細(xì)介紹七個(gè)廣泛應(yīng)用于RAG、搜索引擎、推薦系統(tǒng)等信息檢索任務(wù)的重要指標(biāo)。
注:在RAG中,知識庫是一個(gè)核心概念。它是一個(gè)非參數(shù)記憶存儲,用于存儲RAG系統(tǒng)將處理的所有文檔。
準(zhǔn)確率在信息檢索領(lǐng)域通常定義為正確預(yù)測(包括真陽性和真陰性)占總樣本的比例。這一概念源自監(jiān)督學(xué)習(xí)中的分類問題,但在檢索和RAG語境下有其特定解釋:準(zhǔn)確率檢索到的相關(guān)文檔數(shù)未檢索到的不相關(guān)文檔數(shù)知識庫中總文檔數(shù)
盡管準(zhǔn)確率是一個(gè)直觀的指標(biāo),但它并不是評估檢索系統(tǒng)的最佳選擇。在大型知識庫中,對于任何給定查詢大多數(shù)文檔通常都是不相關(guān)的,這可能導(dǎo)致準(zhǔn)確率呈現(xiàn)誤導(dǎo)性的高值。此外該指標(biāo)并不考慮檢索結(jié)果的排序質(zhì)量。
精確率聚焦于檢索結(jié)果的質(zhì)量,衡量檢索到的文檔中與用戶查詢相關(guān)的比例。它回答了這樣一個(gè)問題:在所有被檢索到的文檔中,有多少是真正相關(guān)的?
精確率檢索到的相關(guān)文檔數(shù)檢索到的總文檔數(shù)
高精確率表明檢索器能夠有效地識別和提取相關(guān)文檔。
注:精確率在分類任務(wù)中也是一個(gè)常用指標(biāo),定義為模型預(yù)測為正例的樣本中實(shí)際為正例的比例,即真陽性 /(真陽性 + 假陽性)。
Precision@k是精確率的一個(gè)變體,它僅考慮檢索結(jié)果中排名前k的文檔。這一指標(biāo)在RAG系統(tǒng)中尤為重要,因?yàn)橥ǔV挥信琶壳暗慕Y(jié)果會被用于增強(qiáng)。例如如果RAG系統(tǒng)僅使用前5個(gè)文檔進(jìn)行增強(qiáng),那么Precision@5就成為一個(gè)關(guān)鍵指標(biāo)。
例如,Precision@5為0.8(或4/5)意味著在前5個(gè)檢索結(jié)果中,有4個(gè)是相關(guān)的。
Precision@k在比較不同系統(tǒng)的檢索性能時(shí)特別有用,尤其是當(dāng)系統(tǒng)間檢索的總文檔數(shù)可能不同時(shí)。但是它的局限性在于k值的選擇可能帶有主觀性,且該指標(biāo)不考慮k之外的結(jié)果。
召回率評估檢索系統(tǒng)的覆蓋范圍,衡量從知識庫中所有相關(guān)文檔中成功檢索到的比例。它回答了這樣一個(gè)問題:在所有相關(guān)文檔中,實(shí)際檢索到了多少?
與精確率不同召回率的計(jì)算需要預(yù)先知道知識庫中相關(guān)文檔的總數(shù)。在大規(guī)模系統(tǒng)中這可能是一個(gè)挑戰(zhàn)。召回率同樣不考慮檢索文檔的排序。理論上檢索所有文檔可以獲得完美的召回率,但這顯然不符合實(shí)際需求。
類似于Precision@k,Recall@k考慮了前k個(gè)檢索結(jié)果中的相關(guān)文檔比例:
Recall@k = 前k個(gè)結(jié)果中相關(guān)文檔的數(shù)量 / 知識庫中相關(guān)文檔總數(shù)
召回率和精確率的不同場景
F1分?jǐn)?shù)是精確率和召回率的調(diào)和平均值,提供了一個(gè)平衡檢索器質(zhì)量和覆蓋范圍的單一指標(biāo)。
F1分?jǐn)?shù)的特點(diǎn)是當(dāng)精確率或召回率任一指標(biāo)較低時(shí),分?jǐn)?shù)會受到顯著影響。只有當(dāng)兩個(gè)指標(biāo)都較高時(shí),F(xiàn)1分?jǐn)?shù)才會較高。這種特性使得F1分?jǐn)?shù)不會被單一指標(biāo)的高值所誤導(dǎo)。
分?jǐn)?shù)平衡了精確率和召回率。中等水平的精確率和召回率可能獲得比一個(gè)指標(biāo)很高而另一個(gè)很低時(shí)更高的F1分?jǐn)?shù)。
F1分?jǐn)?shù)提供了一個(gè)綜合度量,便于比較不同系統(tǒng)的整體性能。但是它不考慮檢索結(jié)果的排序,且默認(rèn)給予精確率和召回率相同的權(quán)重,這在某些應(yīng)用場景中可能不夠理想。
重要說明:
文檔相關(guān)性判定:大多數(shù)討論的指標(biāo)都涉及”相關(guān)”文檔的概念。確定文檔相關(guān)性的最直接方法是通過人工評估。通常由領(lǐng)域?qū)<覍彶槲臋n并判定其相關(guān)性。為減少個(gè)人偏見,這種評估往往由專家小組而非個(gè)人完成。但是從規(guī)模和成本的角度考慮,人工評估存在局限性。因此任何能可靠建立相關(guān)性的數(shù)據(jù)都變得極為寶貴。在這一背景下,基準(zhǔn)事實(shí)(Ground Truth)指的是已知真實(shí)或正確的信息。在RAG和生成式AI領(lǐng)域,基準(zhǔn)事實(shí)通常表現(xiàn)為一組預(yù)先準(zhǔn)備的提示-上下文-響應(yīng)或問題-上下文-響應(yīng)示例,類似于監(jiān)督學(xué)習(xí)中的標(biāo)記數(shù)據(jù)。為知識庫創(chuàng)建的基準(zhǔn)事實(shí)數(shù)據(jù)可用于RAG系統(tǒng)的評估和優(yōu)化。
前面討論的四個(gè)指標(biāo)主要關(guān)注檢索的整體效果,而不考慮結(jié)果的排序。接下來介紹的三個(gè)指標(biāo)則進(jìn)一步考慮了檢索結(jié)果的排序質(zhì)量,為評估提供了更深入的視角。
平均倒數(shù)排名(MRR)是一個(gè)專門用于評估相關(guān)文檔排名的指標(biāo)。它計(jì)算的是一組查詢中,每個(gè)查詢的第一個(gè)相關(guān)文檔的排名倒數(shù)的平均值。其數(shù)學(xué)表達(dá)式如下:
其中,N為查詢總數(shù),rank(i)為第i個(gè)查詢中第一個(gè)相關(guān)文檔的排名
MRR特別適用于評估系統(tǒng)快速找到相關(guān)文檔的能力,因?yàn)樗紤]了結(jié)果的排序。但是由于MRR只關(guān)注第一個(gè)相關(guān)結(jié)果,在需要多個(gè)相關(guān)結(jié)果的場景中,其應(yīng)用可能受到限制。
MRR考慮了排名,但僅關(guān)注第一個(gè)相關(guān)文檔
平均精確率均值(MAP)是一個(gè)綜合性指標(biāo),它結(jié)合了不同截?cái)嗉墑e(k值)的精確率和召回率。MAP首先計(jì)算每個(gè)查詢的平均精確率,然后取所有查詢的平均值。其計(jì)算過程如下:
其中,R(i)為查詢i的相關(guān)文檔總數(shù),Precision@k為前k個(gè)結(jié)果中的精確率,rel(k)為第k個(gè)文檔的相關(guān)性(0或1)
其中,N為查詢總數(shù)
MAP提供了一個(gè)在不同召回率水平上的綜合質(zhì)量度量。當(dāng)結(jié)果的排序質(zhì)量很重要時(shí),MAP是一個(gè)非常有效的指標(biāo)。但是其計(jì)算過程相對復(fù)雜。
MAP考慮了所有檢索到的文檔,并對更好的排序給予更高的分?jǐn)?shù)
歸一化折損累積增益(nDCG)是一個(gè)更為精細(xì)的排序質(zhì)量評估指標(biāo)。它不僅考慮了相關(guān)文檔的位置,還為較早出現(xiàn)的相關(guān)文檔分配更高的權(quán)重。nDCG特別適用于文檔具有不同程度相關(guān)性的場景。
計(jì)算nDCG涉及以下步驟:
其中,rel(i)為第i個(gè)文檔的相關(guān)性分?jǐn)?shù)
nDCG考慮了文檔的相關(guān)性程度,并對不正確的排序進(jìn)行懲罰
nDCG是一個(gè)計(jì)算較為復(fù)雜的指標(biāo)。它要求為每個(gè)文檔分配相關(guān)性分?jǐn)?shù),這可能引入一定的主觀性。折損因子的選擇也會顯著影響最終結(jié)果。盡管如此nDCG能夠有效地處理文檔間不同程度的相關(guān)性,并給予排名較高的項(xiàng)目更多權(quán)重,使其成為評估高級檢索系統(tǒng)的有力工具。
檢索系統(tǒng)不僅在RAG中發(fā)揮關(guān)鍵作用,還廣泛應(yīng)用于網(wǎng)絡(luò)和企業(yè)搜索引擎、電子商務(wù)產(chǎn)品搜索、個(gè)性化推薦、社交媒體廣告投放、檔案管理系統(tǒng)、數(shù)據(jù)庫查詢優(yōu)化、智能虛擬助手等多個(gè)領(lǐng)域。上述檢索指標(biāo)為評估和改進(jìn)這些系統(tǒng)的性能提供了重要依據(jù),有助于更好地滿足用戶需求。
本文詳細(xì)介紹了七個(gè)核心檢索指標(biāo),從簡單的準(zhǔn)確率到復(fù)雜的nDCG,每個(gè)指標(biāo)都有其特定的應(yīng)用場景和優(yōu)缺點(diǎn)。在實(shí)際應(yīng)用中,選擇合適的指標(biāo)組合對于全面評估和優(yōu)化RAG系統(tǒng)至關(guān)重要。
文章轉(zhuǎn)自微信公眾號@數(shù)據(jù)STUDIO
node.js + express + docker + mysql + jwt 實(shí)現(xiàn)用戶管理restful api
nodejs + mongodb 編寫 restful 風(fēng)格博客 api
表格插件wpDataTables-將 WordPress 表與 Google Sheets API 連接
手把手教你用Python和Flask創(chuàng)建REST API
使用 Django 和 Django REST 框架構(gòu)建 RESTful API:實(shí)現(xiàn) CRUD 操作
ASP.NET Web API快速入門介紹

2024年在線市場平臺的11大最佳支付解決方案

完整指南:如何在應(yīng)用程序中集成和使用ChatGPT API

選擇AI API的指南:ChatGPT、Gemini或Claude,哪一個(gè)最適合你?