
應用程序開發中不可或缺的開放API
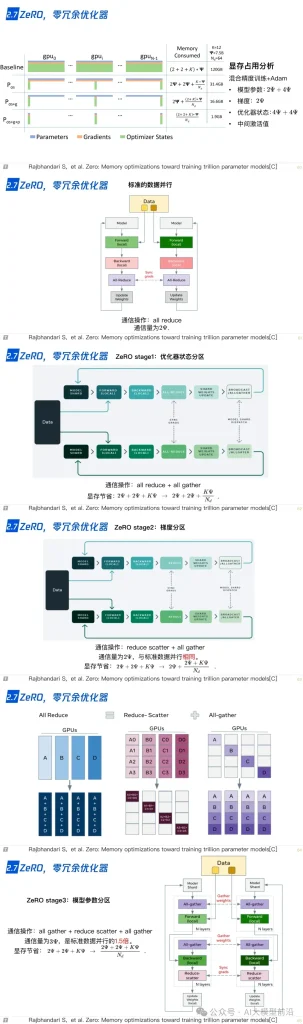
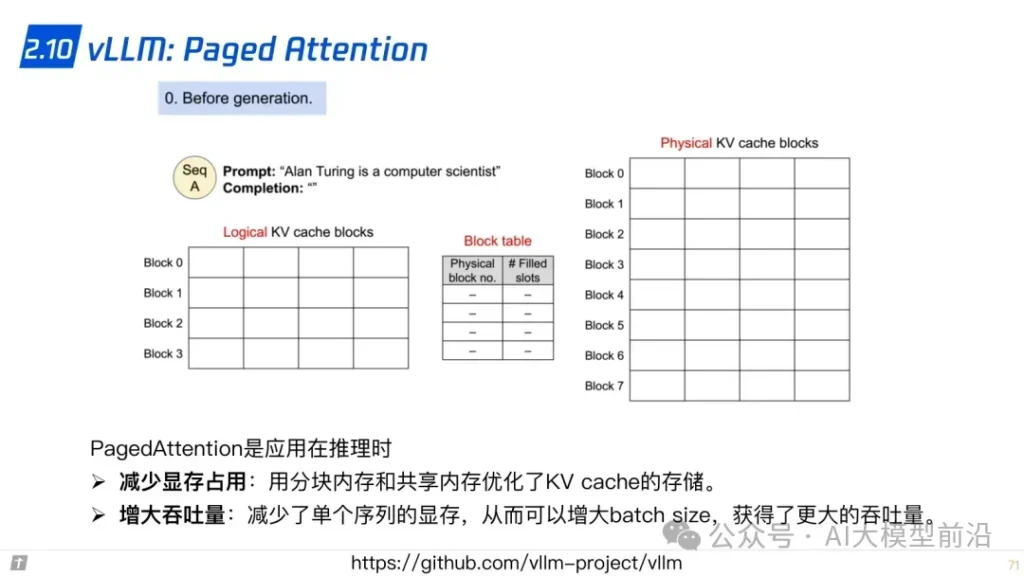
同時,零冗余優化器ZeRO(Zero Redundancy Optimizer)和CPU卸載技術ZeRo-offload,通過減少內存占用和提高計算效率,進一步加速了訓練過程。混合精度訓練(Mixed Precision Training)則通過結合不同精度的計算,平衡了計算速度與內存占用。激活重計算技術(Activation Recomputation)和Flash Attention、Paged Attention等優化策略,則進一步提升了模型的訓練效率和準確性。

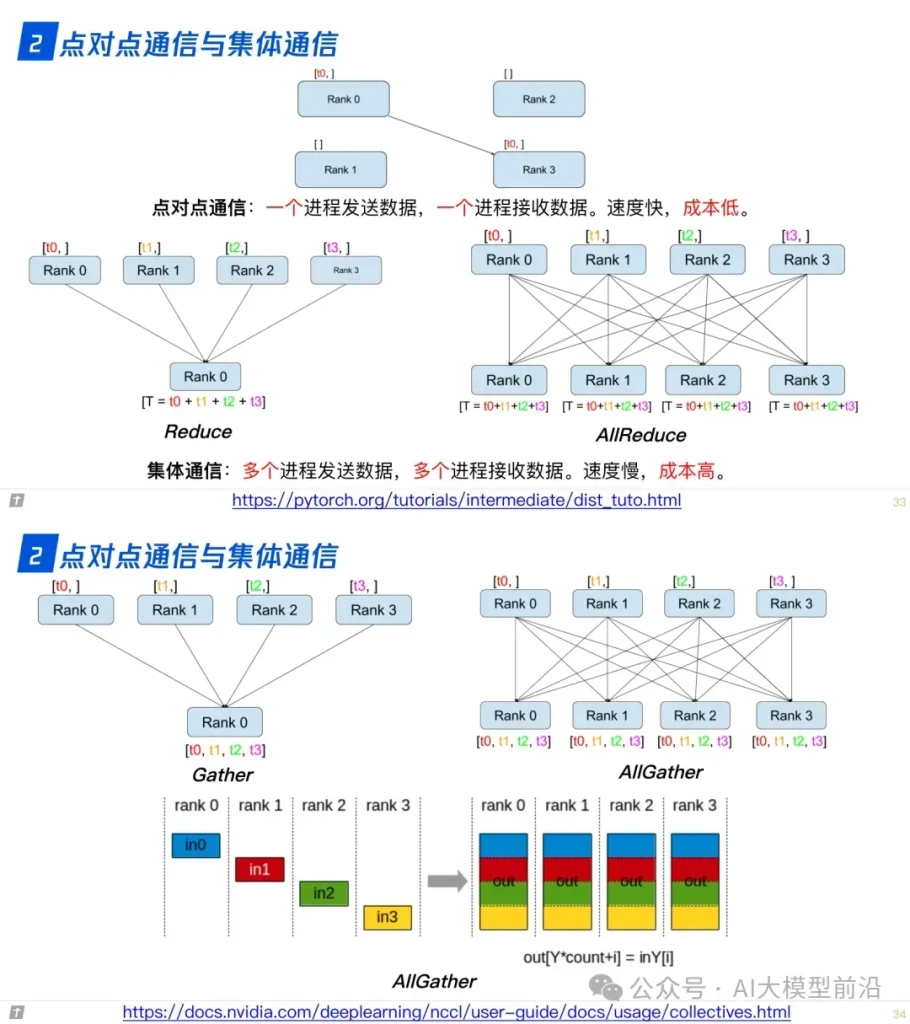
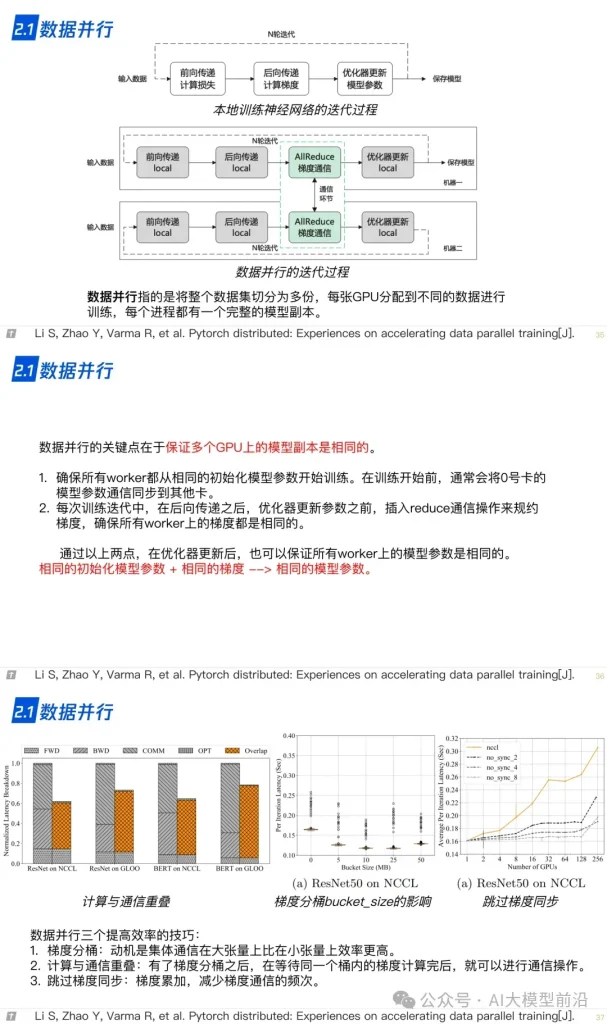

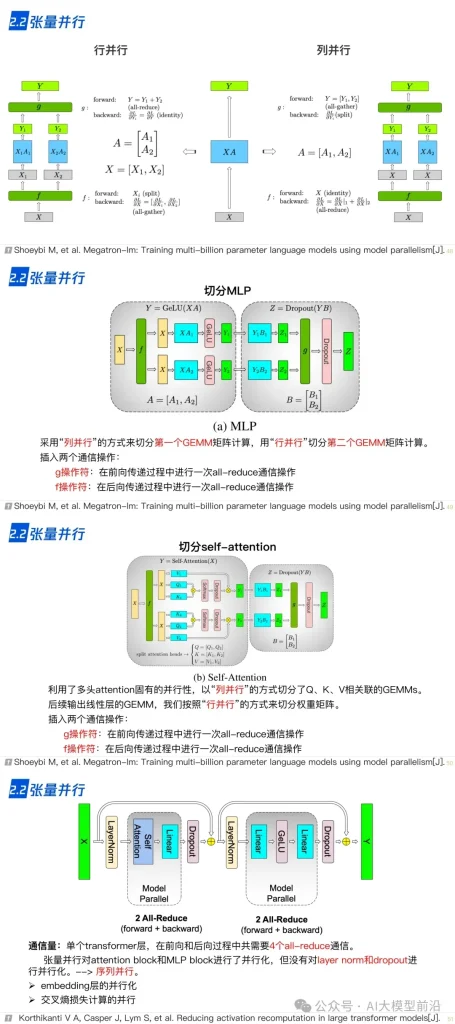
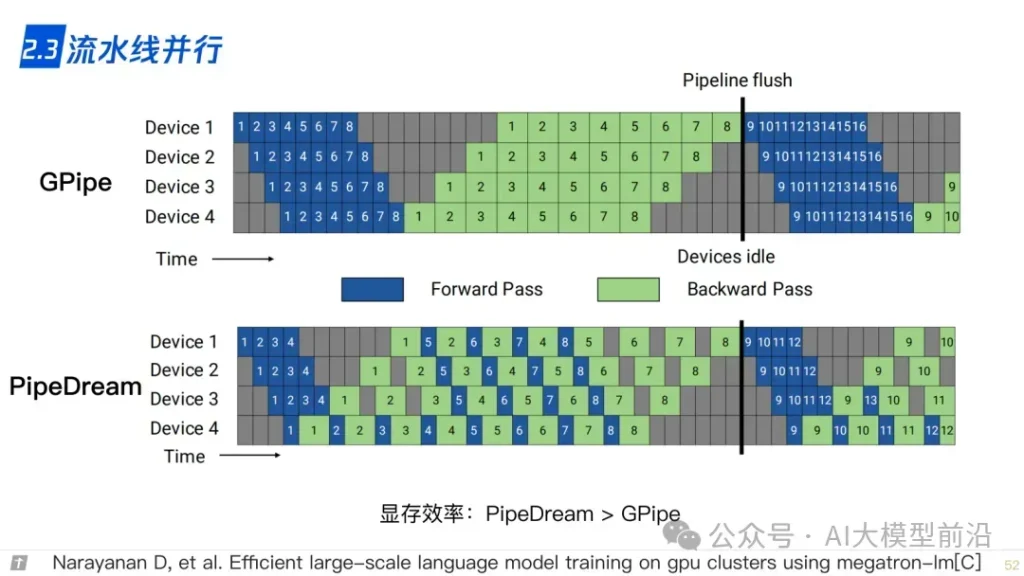


理解大語言模型,可以從‘LLM的架構、LLL的訓練、LLL的微調’三個方面進行,也可以針對需求重點理解一部分。例如,訓練+微調,可以讀后兩篇,只做微調,讀最后一篇。

原文轉自 微信公眾號@AI大模型前沿







