
9 個用于英國、歐盟和全球驗證的增值稅 API
因為無論學習什么,總是要先鳥瞰全局,再循序漸進,反正我是這么學的,有先學后學,但是更重要的先入門,對體系中的每一個部分都有一個最基本的知識,然后是不斷循環,不斷深入。

對于我們大部分人來說,我們學大模型,要么是為了微調,要么是為了應用開發。
然而,原理仍然很重要。
尤其是當你學到微調的時候,如果不了解底層原理,你根本無法理解各種微調的區別(比如說面試官可能問你Lora和Adapter的區別),那你也就更不可能輕松的理解更新的架構為什么這樣或者那樣去設計。
做應用開發也是。為什么要打扎實原理基礎 – 因為不深刻了解原理,你用LLM來做應用的時候心里就沒底。
當我們心中有了一個技術地圖,那么剩下的,更深入的東西就可以一點點地往這個技術地圖里面安插。那么當一個新的技術又突然來臨時,因為你胸中已有丘壑,你也就沒有那么焦慮了。
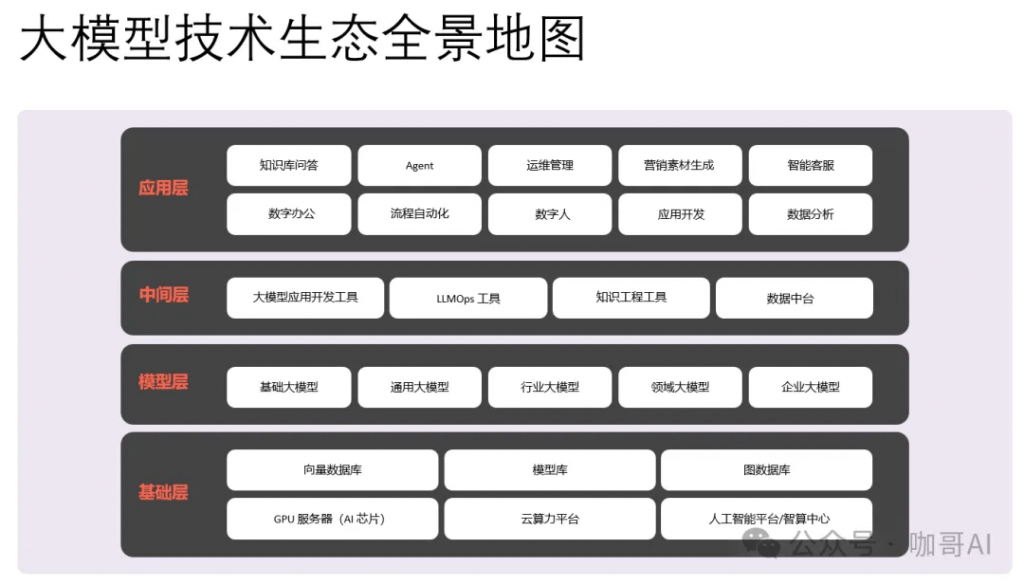
我們要從語言模型的定義和起源開始去理解到底什么是大語言模型,看看它是怎樣一步一步進化到今天這個狀態的。
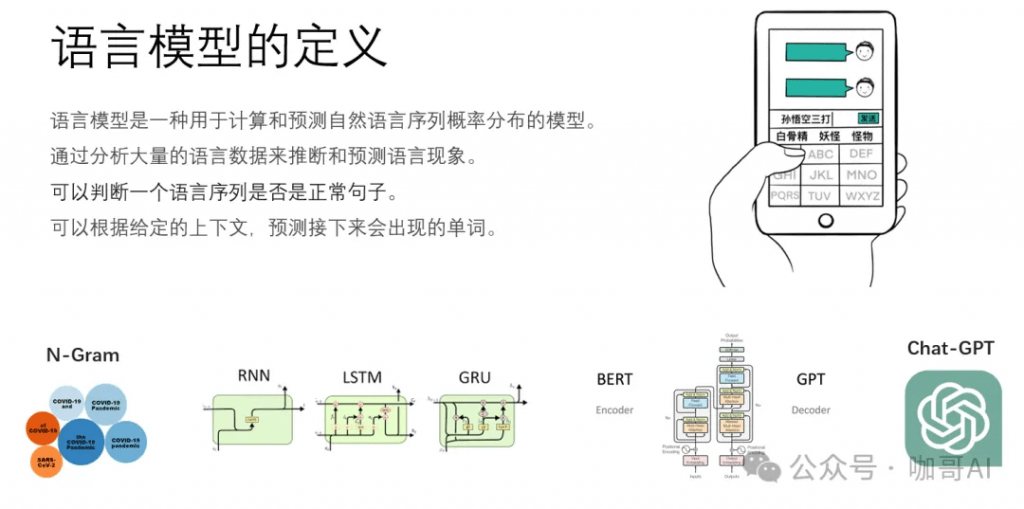
語言模型是一種用于計算和預測自然語言序列概率分布的模型,它通過分析大量的語言數據來推斷和預測語言現象,為自然語言上下文相關的這種特性來建立數學模型。簡單地說,它可以根據給定的上下文,預測接下來的單詞。
常見的語言模型n-Gram模型、循環神經網絡(RNN)模型、長短時記憶網絡(LSTM)模型,以及現在非常流行的基于Transformer架構的預訓練語言模型(Pre-trained Language Model,PLM),如BERT、GPT系列等,本質上都是語言模型。
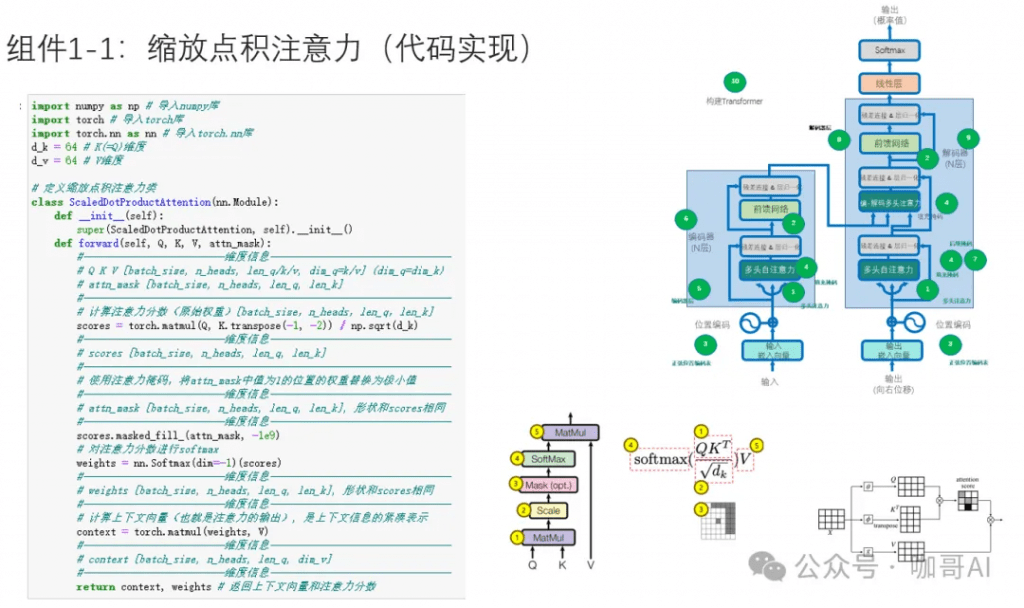
以我個人的經驗來看,對語言模型的原理,了解到科普的程度是遠遠不夠的,手撕幾次Transformer框架,無論對于后續做應用開發,還是做微調,或者是去面試,都是很有好處的。
那么具體到我們每個人,每一個企業,我們打開,也就是解鎖大模型能力的方式有哪幾種呢?
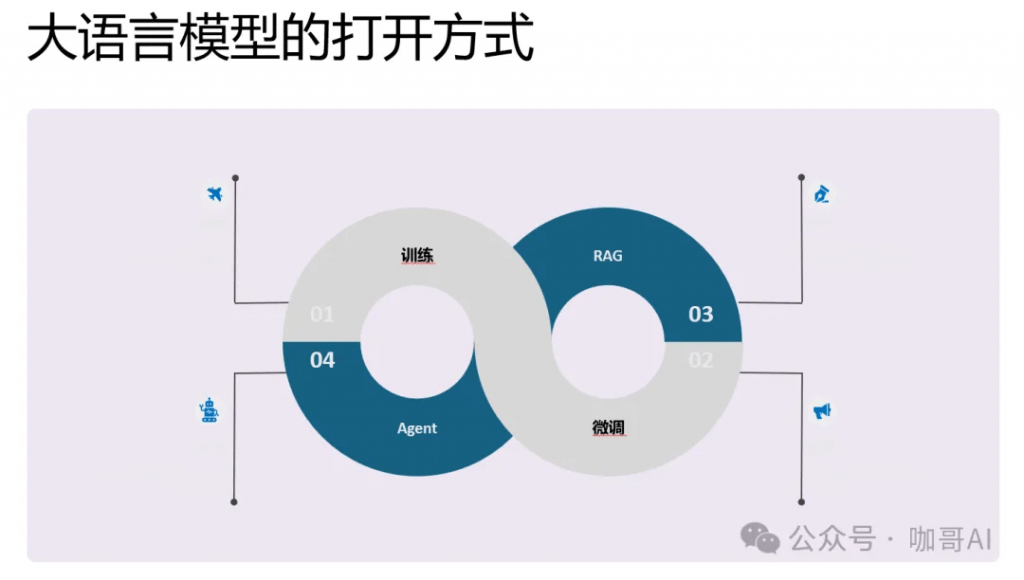
第一個就是從頭訓練出屬于你自己的企業大模型。
第二個就是基于基礎模型,微調一部分參數。二者的區別在于數據的數量需求不同。
那么第三個相對比較成熟的就是RAG應用。通過企業知識庫來構建檢索增強功能。
第四個就是尚未完全成熟但是大家都在探索的Agent技術。
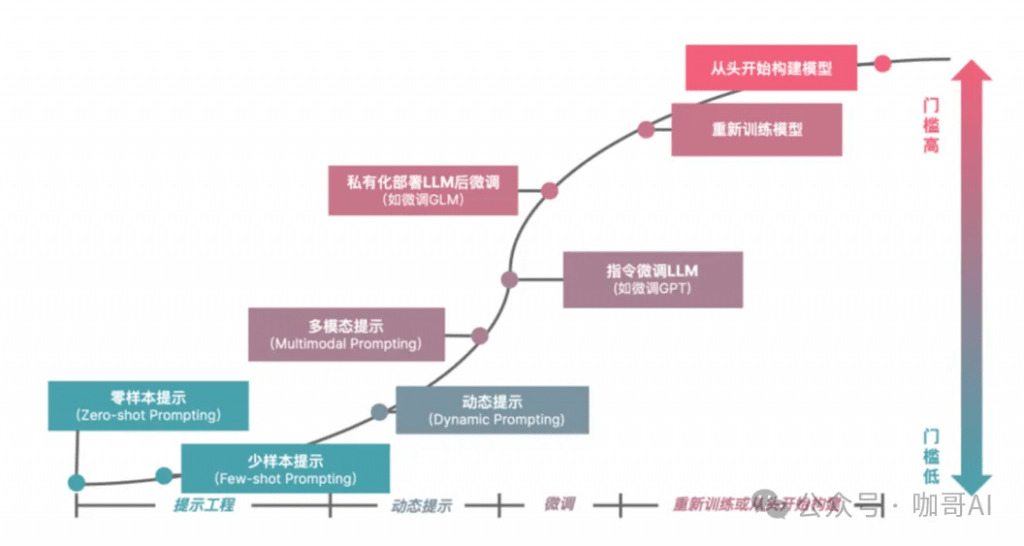
核心內容就是找到屬于你自己的應用場景。
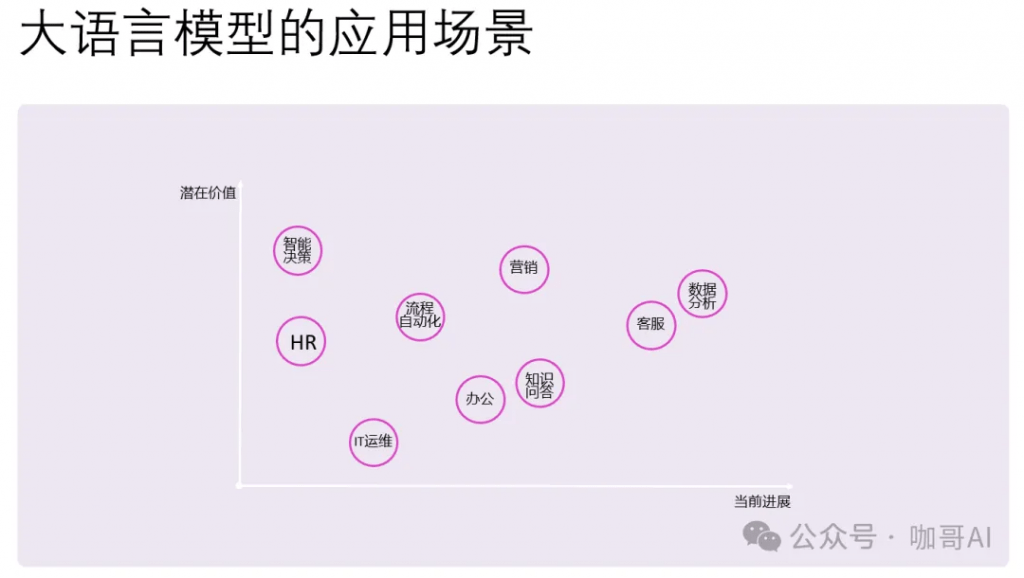
具體到大語言模型的應用場景,有兩個維度,一個是當前進展,也就是落地的難度。難度小,進展就大。
有些場景是很難落地的,但是潛在價值卻很大。比如如何讓AI進行智能化的決策,也就是AI Agent的應用,大家還都在摸索之中。
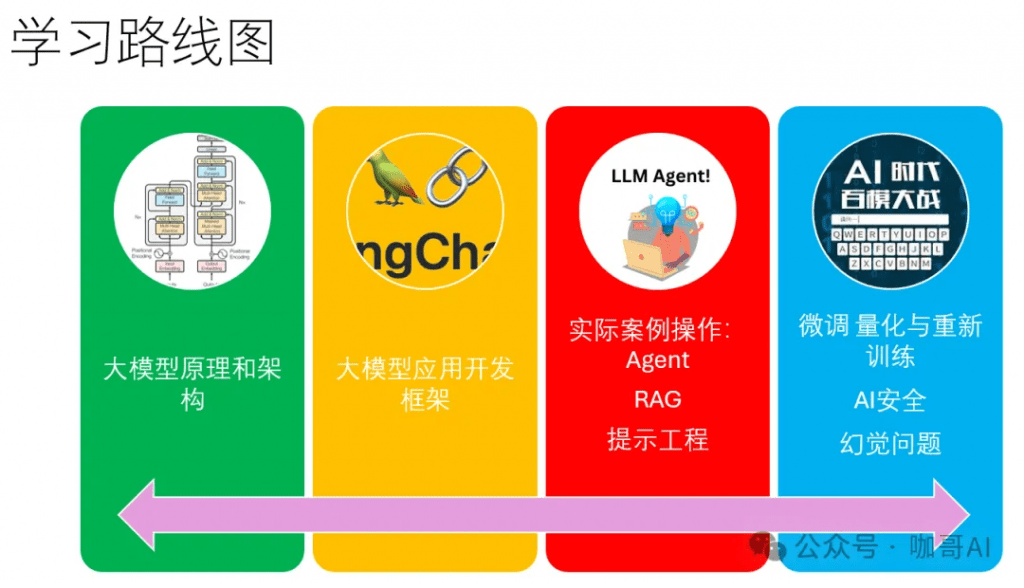
上圖中的這些技術,都是進軍大模型應用開發的良好切入點。
LangChain、LlamaIndex、Semantic Kernel 和 OpenAI API 都是為了加強與大型語言模型(LLMs)的交互而設計的開發工具,它們在特點和用途上各有側重。
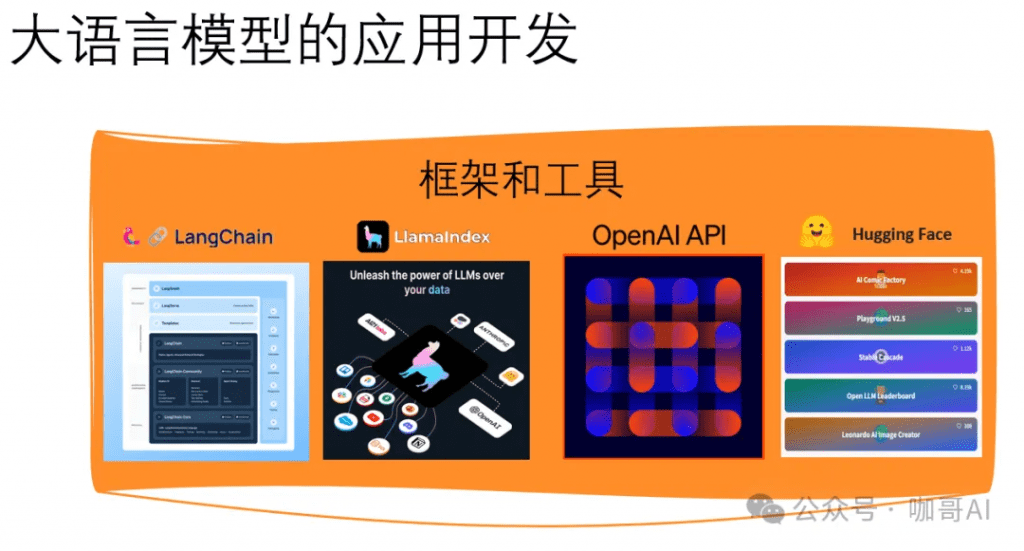
在選擇這些工具時,重要的是考慮您的具體需求:如果項目側重于數據驅動的交互和多數據源集成,LangChain可能是更好的選擇。如果需要高效的數據索引和檢索,LlamaIndex將非常適合。而如果希望在多種編程環境中快速集成語言模型,或者需要與Microsoft的工具和服務無縫協作,Semantic Kernel可能更加合適。對于直接訪問最新的語言模型并快速部署文本相關應用,OpenAI API則提供了一個非常直接和強大的選項。—— 對于我個人來說,現在我經常使用OpenAI API(或者其它任何國內LLM的API)直接創建LLM應用。
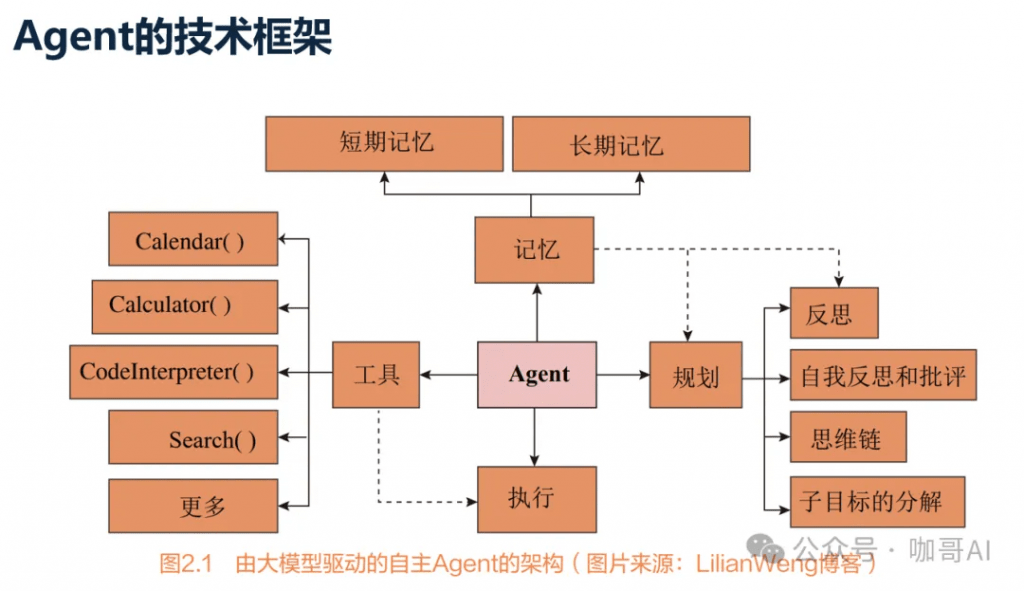
我們把所有能夠感知環境、做出決策并采取行動的實體或系統視為人工智能領域中的Agent。
Agent能夠自主推理。

Agent能夠調用工具。
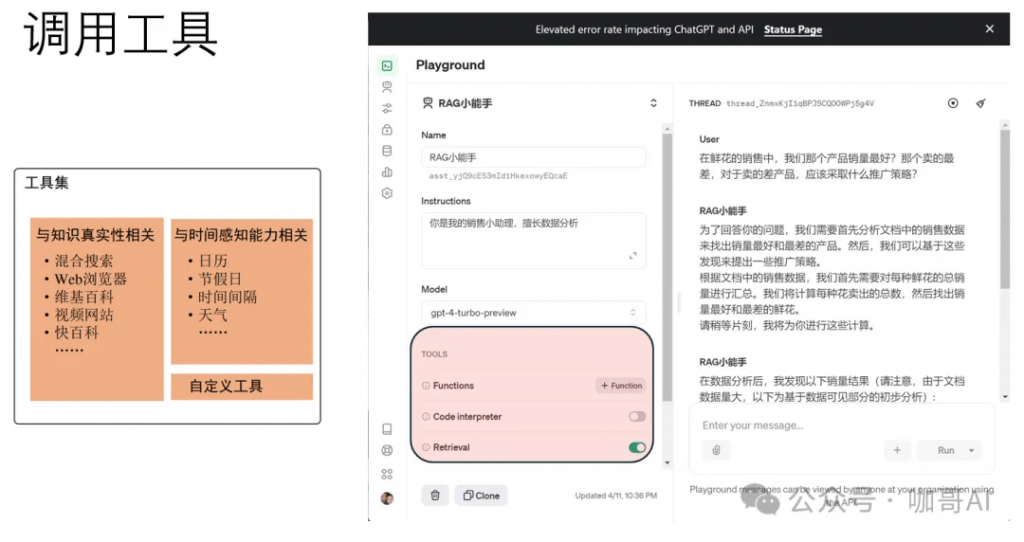

許多大型語言模型(LLM)的應用需要使用用戶特定的數據,而這些數據并不是模型訓練集的一部分。實現這一點的主要方法是通過檢索增強生成(RAG)。在這個過程中,會檢索外部數據,然后在生成步驟中傳遞給LLM。
RAG在基于LLM的應用開發中地位不低,堪稱AI大模型落地應用第一站。
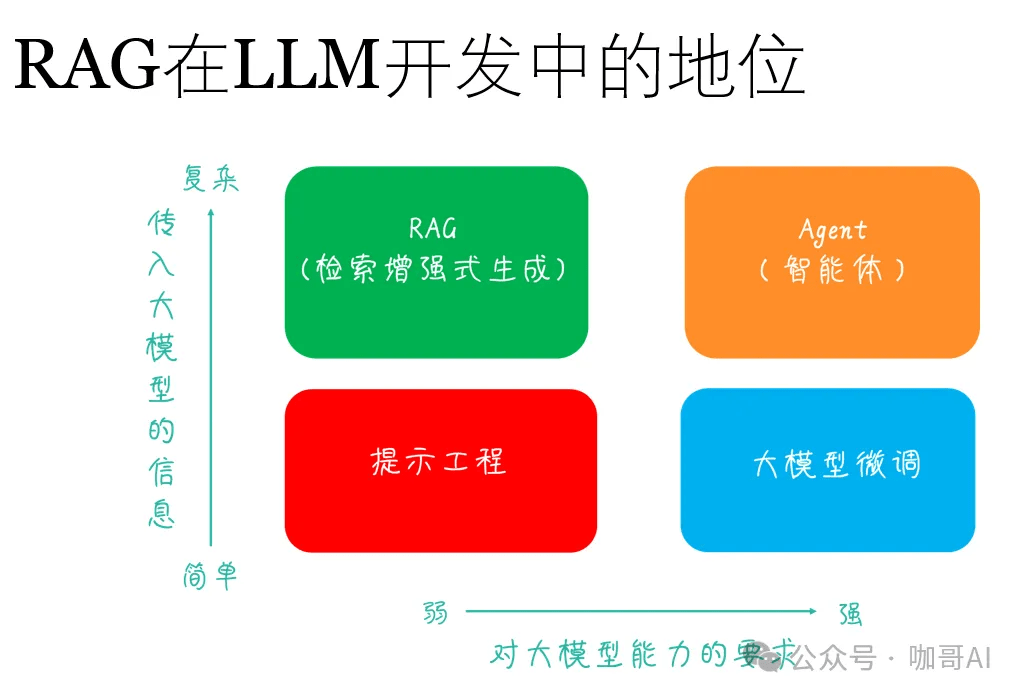
RAG的實現架構如下。
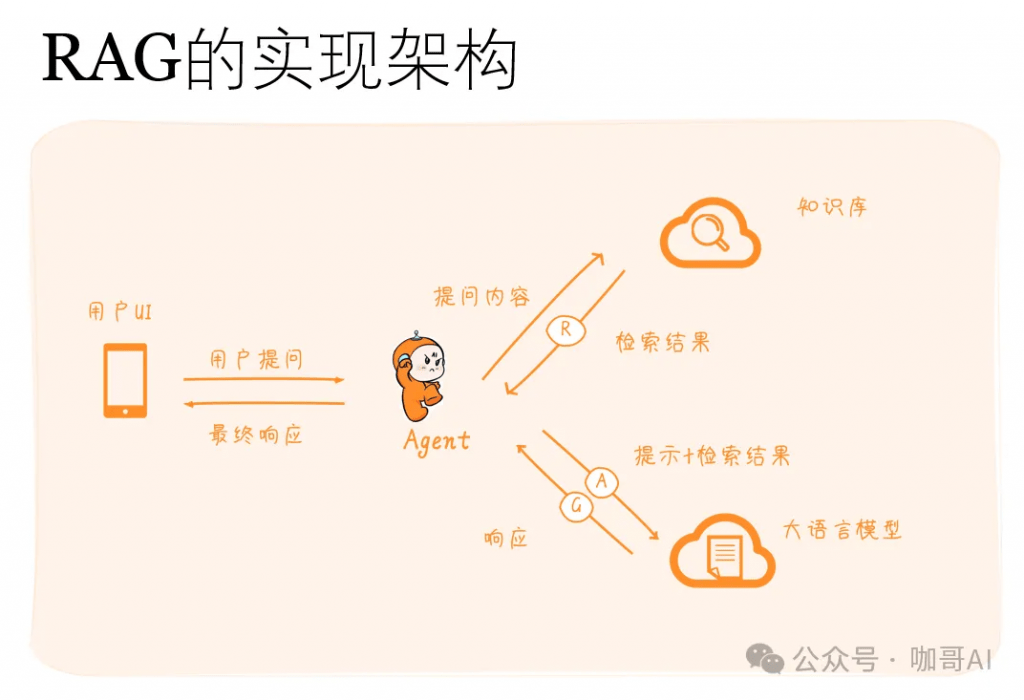
RAG 的工作原理可以分為如下兩個主要部分:
那么,遇到行業相關的LLM應用,做RAG,還是做微調,這是一個問題!
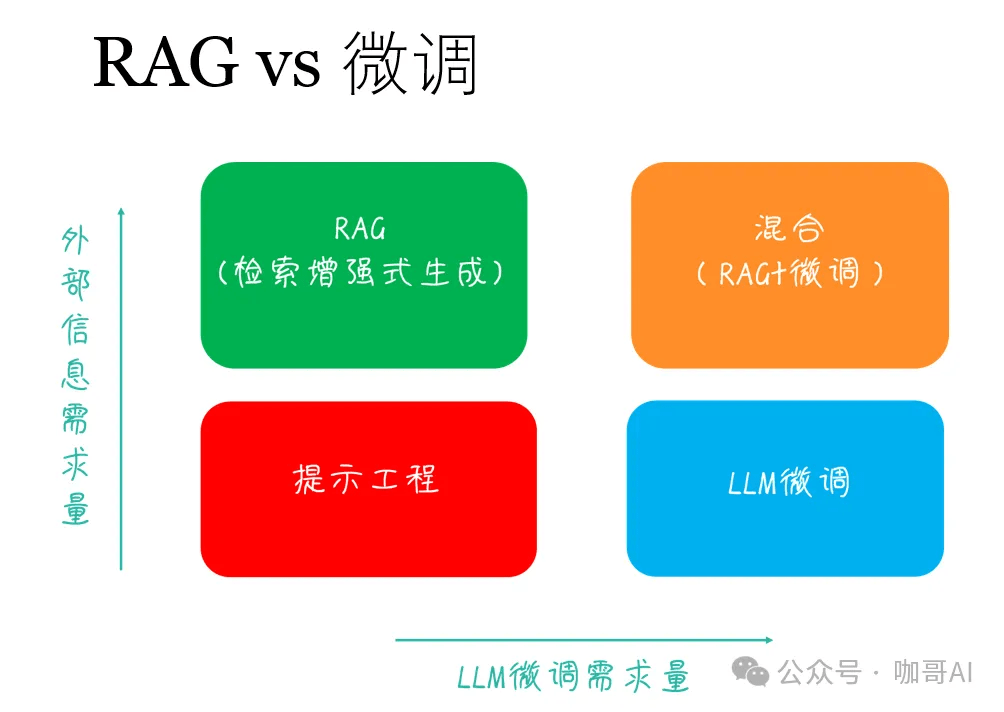
有論文指出——相對于做微調來說,RAG其實是性價比更高的選擇。
設計出產品級別的RAG系統并非易事,有很多工程細節需要思考。比如說,如果幾十萬甚至上百萬文檔,如何還能高效檢索。在文檔切片時,如何保留前后上下文。
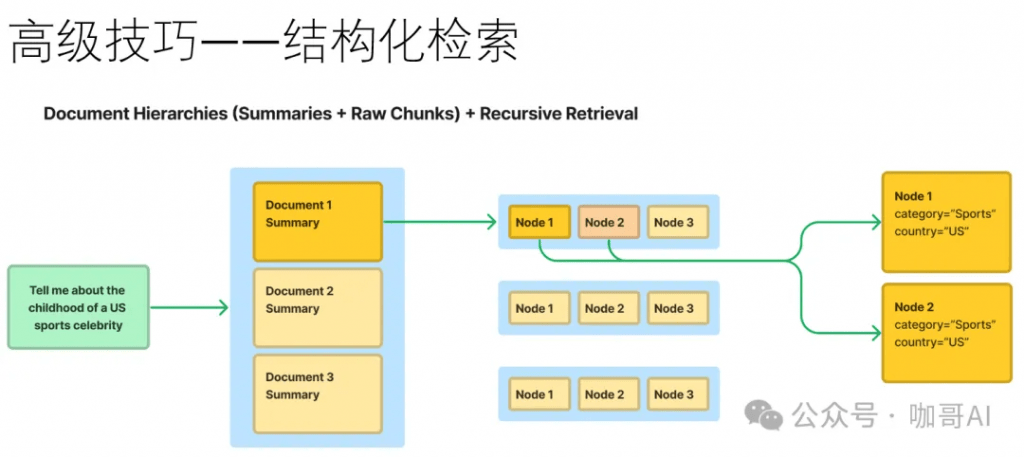
此時我們的確需要一些高級技巧,以及實戰經驗的總結和積累。有效地選擇Embedding模型,優秀的向量數據庫,優化的索引和檢索方案,以及強大的生成模型都是必不可少的。
對于這個問題,就更不是幾句話可以說清楚的了。

佳哥希望有機會帶著你,做一些LLM微調/量化和加速框架的項目實戰。

從新技術的爆發周期來看,AI革命正逢其時,這是技術帶給我們每一個人的千載難逢的良機。AI應用的爆發期可能還需要2-3年的時間,killer app暫時沒有進入大眾用戶人群是符合客觀規律的。

桌面程序時代,互聯網時代,移動互聯網時代,都催生了大量獨角獸,唯獨AI時代,仍然有大量空白區域虛位以待。——?這是我們程序員、開發人員、產品經理,每一個IT人的機會。
原文轉自 微信公眾號@咖哥AI




