GraphRAG:基于PolarDB+通義千問api+LangChain的知識圖譜定制實踐
圖1. LLM推理的預測概率示意
因此,這個依概率采樣的推理過程決定了LLM不可能100%按要求輸出JSON格式。錯誤的JSON輸出導致了我們在工程鏈路上無法作后續的解析,因此,能100%嚴格限制JSON格式輸出的方法非常重要。
推出于2023年12月份,基于提示詞優化,用戶仍需要在提示詞中給出JSON示例,不能保證嚴格100%輸出JSON。
近期推出。類似OpenAI的 JSON Mode,用戶仍需要在提示詞中給出JSON示例,不能保證嚴格100%輸出JSON。
推出于2024年8月份,根據用戶給出的JSON示例,嚴格保證100%輸出JSON格式。
https://openai.com/index/introducing-structured-outputs-in-the-api/
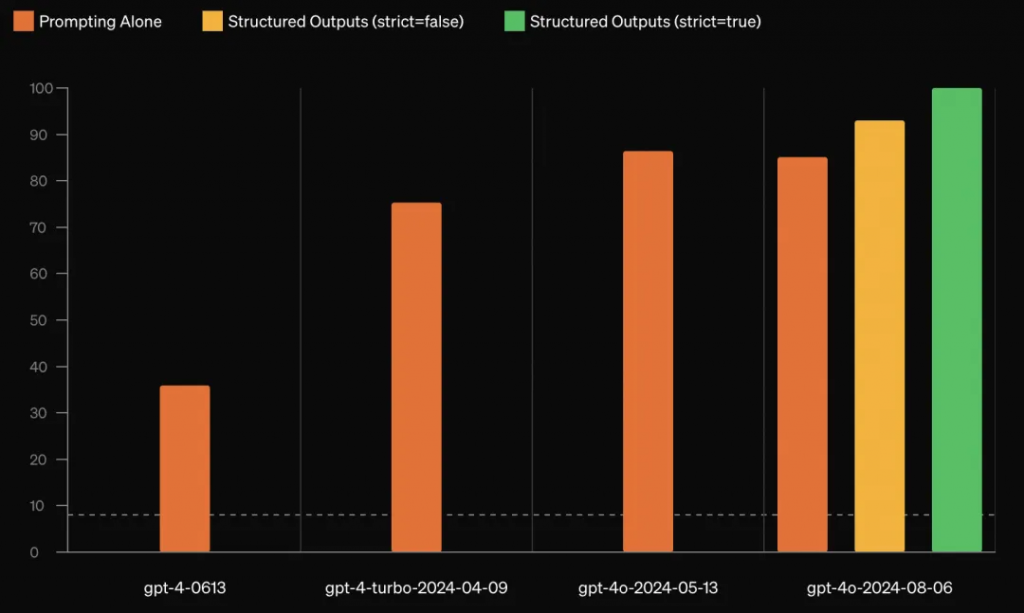
圖2. OpenAI輸出JSON格式的方法,橙、黃、綠分別代表提示詞優化、微調、動態限制解碼法的JSON輸出準確率
(動態限制解碼法準確率為100%)
Motivation: 在一個基于通義千問的AI教評項目場景中,JSON格式輸出對客戶十分重要。因此,我們在該項目實踐中由淺入深,從LLM推理的前、中、后三個階段探索了限制輸出JSON格式的方法。其中,“推理前”和“推理后”這兩個階段的方法用在了項目實踐中,大大提高了AI教評任務中JSON格式的輸出概率。為了進一步研究如何100%輸出JSON格式,我們借他山之石,研究了OpenAI的Structured Outputs方法,在“推理中”這一階段探索并驗證了基于動態限制解碼的100%輸出JSON格式方法。
在分析相關工作基礎上,我們將深入討論每階段的方法、優劣及其實現方式,以期幫助讀者掌握提升JSON輸出概率的辦法,并應用在實踐中。
(以下提示詞來自大量項目實踐驗證)
在提示詞中加入這句話“The JSON object:json”可提高JSON輸出概率。(別問,問就是大量實踐總結的經驗~)
在提示詞中給出”##輸出格式規范”,并給出JSON示例“json ... “
## 輸出格式規范:
```json
[{
"name":"<評價維度>",
"mentions":"< 提及次數 >",
"references":[{
"time":"<發言時間>",
"text":"<原文內容>"}]}]
```
The JSON object:json在利用Qwen-long作AI教評的一個項目中,我們需要從教師的課堂錄音文本中提取結構化的教學維度信息。采用本節中的prompt加上2.3中的JSON后處理方法后,輸出樣本基本是符合預期的結構化JSON。JSON正確概率從50%左右上升到了95%。可見僅靠prompt和后處理,已經能以很高的概率使得大模型按照JSON格式輸出。然而,在一些需要嚴謹輸出JSON格式的場景,100%嚴格輸出JSON格式的方法仍值得研究。
實施簡便,無需模型架構調整,可以大幅提高輸出JSON的概率。
高度依賴于人工設計的prompt,靈活性受限。不能100%輸出JSON
2.2 推理“中”:基于動態限制解碼實現100%輸出JSON
LLM依據已輸出的詞,從詞匯表中預測下一個詞,可以在詞匯表中將不符合JSON規范的詞概率置零,從而防止輸出不符合JSON規范。(原理偏復雜,可跳過本節直接看結論)。假設我們想讓LLM的輸出為一個城市的如下信息:
city_info_schema=[{
"name":"城市名",
"country":"城市所屬國家",
"latitude":"城市緯度",
"population":"城市人口(千萬)",
"top 3 landmarks":["知名景點1","知名景點2","知名景點3"]
}]如上代碼塊所示,在內存中定義JSON輸出的模式city_info_schema。LLM每輪逐個單詞輸出”response”,對于JSON的”key”值,如”name”,我們直接從內存拼接到輸出字符串”response_str”中;對于JSON的”value”,則讓LLM通過推理產生。當用戶提出問題“請填寫杭州的城市信息”后,動態限制解碼流程如下:
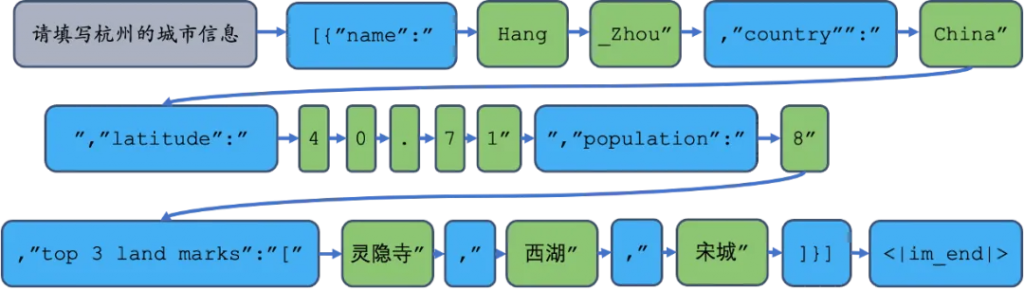
圖3. 動態限制解碼法示意圖。其中只有綠色詞是LLM的推理產生。
上圖展示了動態限制解碼的工作流程,每一輪推理過程我們給定了JSON的“鍵”,僅讓模型推理“值”。可以進一步用正則式(Python re庫)限制我們想要的輸出格式:
city_regex = (
r"""\{\n"""
+ r""" "name": "[\w\d\s]{1,16}",\n"""
+ r""" "country": "[\w\d\s]{1,16}",\n"""
+ r""" "latitude": [-+]?[0-9]*\.?[0-9]{0,2},\n"""
+ r""" "population": [-+]?[0-9]{1,9},\n"""
+ r""" "top 3 landmarks": \["[\w\d\s]{1,16}", "[\w\d\s]{1,16}", "[\w\d\s]{1,16}"\]\n"""
+ r"""\}"""
)在推理過程中,根據正則式限制輸出格式的流程如下:
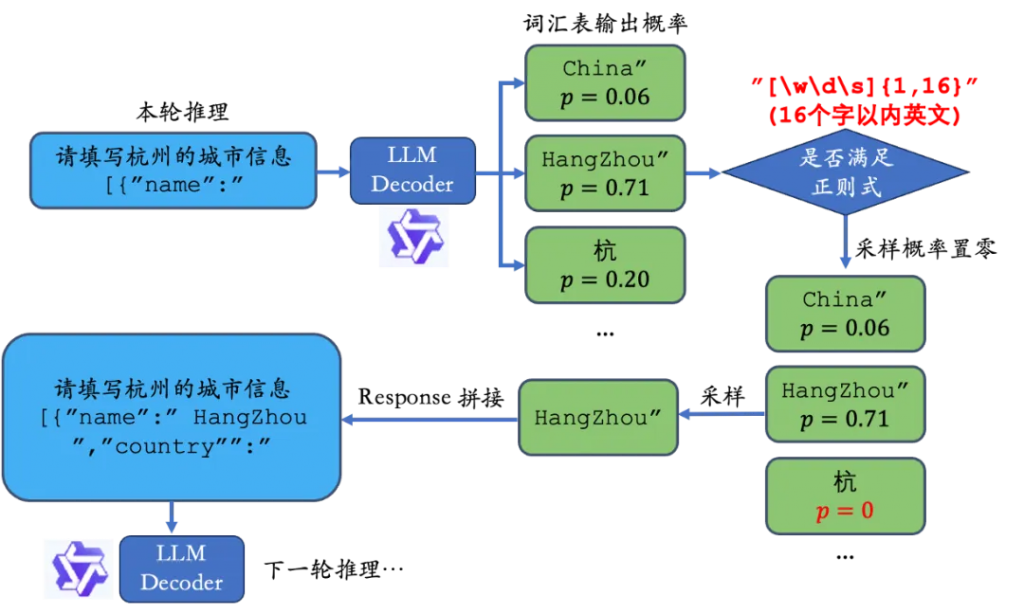
圖4. 動態限制解碼法的”推理-限制-采樣-拼接”流程
如第一個鍵”key”對應的”name”,我們用正則式限制其必須輸出16個字以內的英文,則”杭”的概率由于不符合正則式要求,預測概率置零,模型一定會按照我們的要求輸出。
由于動態限制解碼技術需要我們有凍結模型解碼過程、改變詞匯表采樣概率、改變模型輸入的權限,目前在線的API接口。
不支持編寫動態限制解碼算法。但是可以在本地部署模型以實現動態限制解碼。
在PAI平臺的免費體驗DSW(NVIDIA A10)上本地部署Qwen2-7B-Instruct實現動態限制解碼。基于開源的sglang庫,可快速部署動態限制解碼算法。
pip install --upgrade pip
pip install "sglang[all]"
# Install FlashInfer CUDA kernels
wget "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/flashinfer-0.1.2%2Bcu121torch2.3-cp310-cp310-linux_x86_64.whl"
pip install flashinfer-0.1.2+cu121torch2.3-cp310-cp310-linux_x86_64.whlmodelscope download --model=qwen/Qwen2-7B-Instruct --local_dir ./Qwen2-7B-Instructpython3 -m sglang.launch_server --model-path Qwen2-7B-Instruct --port 30000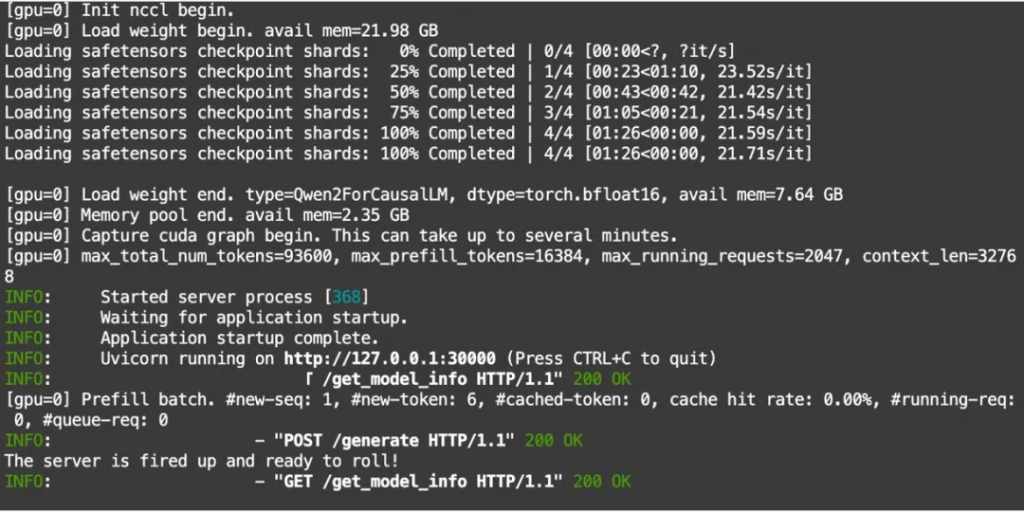
圖5. sglang框架下的千問模型本地部署成功示意圖
顯示上圖即部署成功。
###導入庫
import json
import time
from sglang import set_default_backend, RuntimeEndpoint
import sglang as sgl
from sglang.test.test_utils import (
add_common_sglang_args_and_parse,
select_sglang_backend,
)
from sglang.utils import dump_state_text, read_jsonl
##定義“限制模型輸出的正則式”
city_regex = (
r"""\{\n"""
+ r""" "name": "[\w\d\s]{1,16}",\n"""
+ r""" "country": "[\w\d\s]{1,16}",\n"""
+ r""" "latitude": [-+]?[0-9]*\.?[0-9]{0,2},\n"""
+ r""" "population": [-+]?[0-9]{1,9},\n"""
+ r""" "top 3 landmarks": \["[\w\d\s]{1,16}", "[\w\d\s]{1,16}", "[\w\d\s]{1,16}"\]\n"""
+ r"""\}"""
)
## 將正則式應用在輸出范式中
@sgl.function
def chat_example(s,question):
s += sgl.system("You are a helpful assistant.")
# Same as: s += s.system("You are a helpful assistant.")
with s.user():
s += question
s += sgl.assistant_begin()
s += "Answer: " + sgl.gen("json_output", max_tokens=256, regex=city_regex)
s += sgl.assistant_end()
## 設置Qwen2的本地通信端口,上圖設置為port30000
set_default_backend(RuntimeEndpoint("http://localhost:30000"))
## 捕捉用戶輸入
state = chat_example.run(
question=input("請輸入城市名:"),
# temperature=0.1,
stream=True
)
## 打印必然的JSON輸出結果
for out in state.text_iter():
print(out, end="", flush=True)運行效果:試輸入“杭州”和“紐約”兩個城市。輸出嚴格按照了正則式的限制。
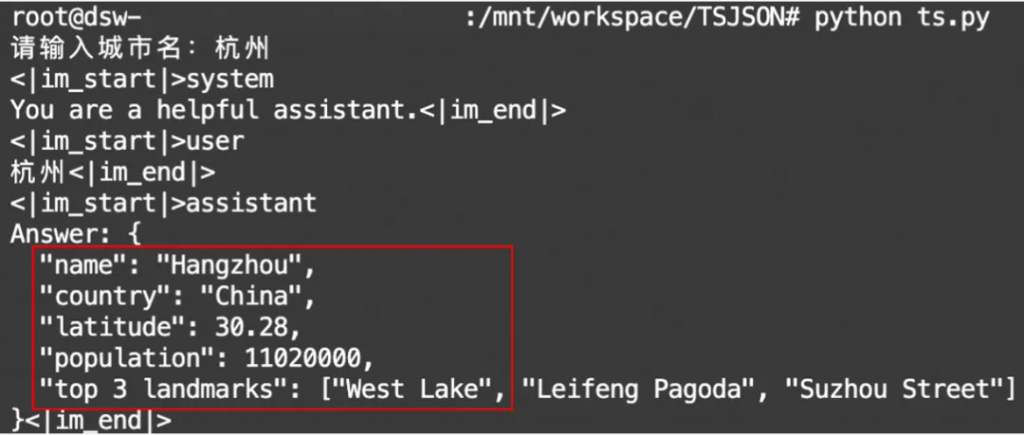
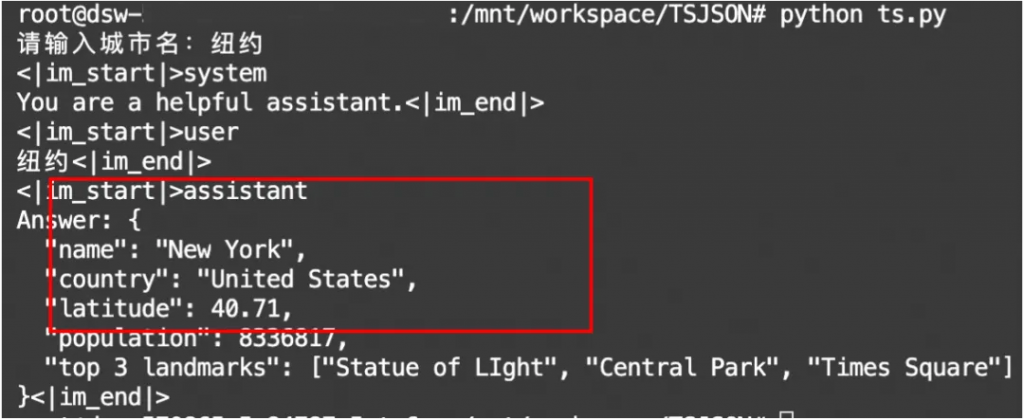
圖6. 基于動態限制解碼的JSON格式輸出結果。
在模型返回response后,也可以利用后處理的技術,校正JSON結構以提高JSON輸出的概率。
Python 的json_repair庫,可以解決一部分模型輸出JSON格式不規范的問題。
from json_repair import loads #pip install json_repair
import json
if __name__ == '__main__':
bad_string= '''
[
{
"foo": "Foo bar baz",
"tag": "foo-bar-baz"
},
{
"中文": "foo bar foobar foo bar baz.",
"標簽": "foo-bar-foobar"
}
]
'''
parsed_json = loads(bad_string)
json_str = json.dumps(parsed_json,ensure_ascii=False)
print(json_str)經實踐驗證,json_repair可以解決輸出的JSON中缺少”},],”的問題。
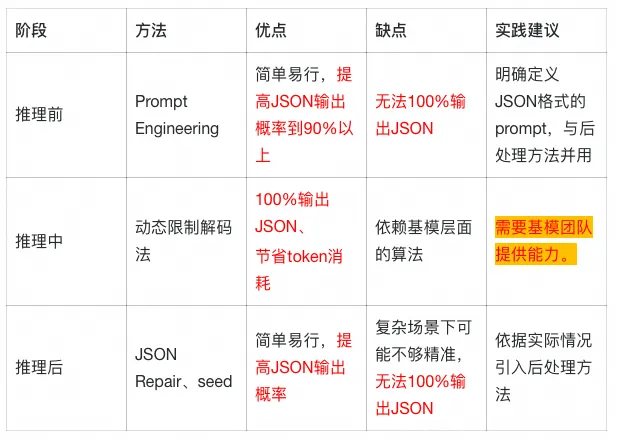
以上介紹的三種類型的方法,可以同時使用,但需要注意不同的場景限制:
文章轉自微信公眾號@阿里云開發者