
企業工商數據API用哪種?
就會發現返回的 json 結果里包含一個 profile 模塊。由于 json 返回比較長,這里就不貼了,我們簡要的來看看 profile 模塊主要的組成結構:
{
"profile": {
"shards": [
{
"id": "[q2aE02wS1R8qQFnYu6vDVQ][my-index-000001][0]", //這里返回了分片的 id,由 節點名[q2aE02wS1R8qQFnYu6vDVQ] + 索引名[my-index-000001] + 分片號 [0]
"node_id": "q2aE02wS1R8qQFnYu6vDVQ",
"shard_id": 0,
"index": "my-index-000001",
"cluster": "(local)", //是不是本地集群解析的
"searches": [
{
"query": [...], // query 階段的耗時,其中包括各種 query 執行類、執行描述以及相關方法的執行耗時
"rewrite_time": 51443, // 總共的 rewrite 耗時
"collector": [...] // collector 階段的耗時,包括階段名稱、階段描述和執行耗時
}
],
"aggregations": [...], //分析聚合階段的各個執行類、執行描述以及相關方法的耗時
"fetch": {...} //fetch 階段的執行類、執行描述以及相關方法的耗時
}
]
}
}注意:
_search?human=true可以增加 profile 數據的可讀性,在主要階段的耗時數據后加上ms,micros單位。行業內有句話“一圖勝千言”,清晰明了的圖形化工具能大大提高分析的效率。
更何況 ES 默認返回 json 數據常常成百上千行,很容易讓人讀不下去。
因此 ES 在 kibana 上做了一個圖形化分析模塊,在 Dev Tools -> Search Profiler。
你可以將需要被解析的索引名和查詢 DSL 貼入相應的區域進行直接執行Profile解析。
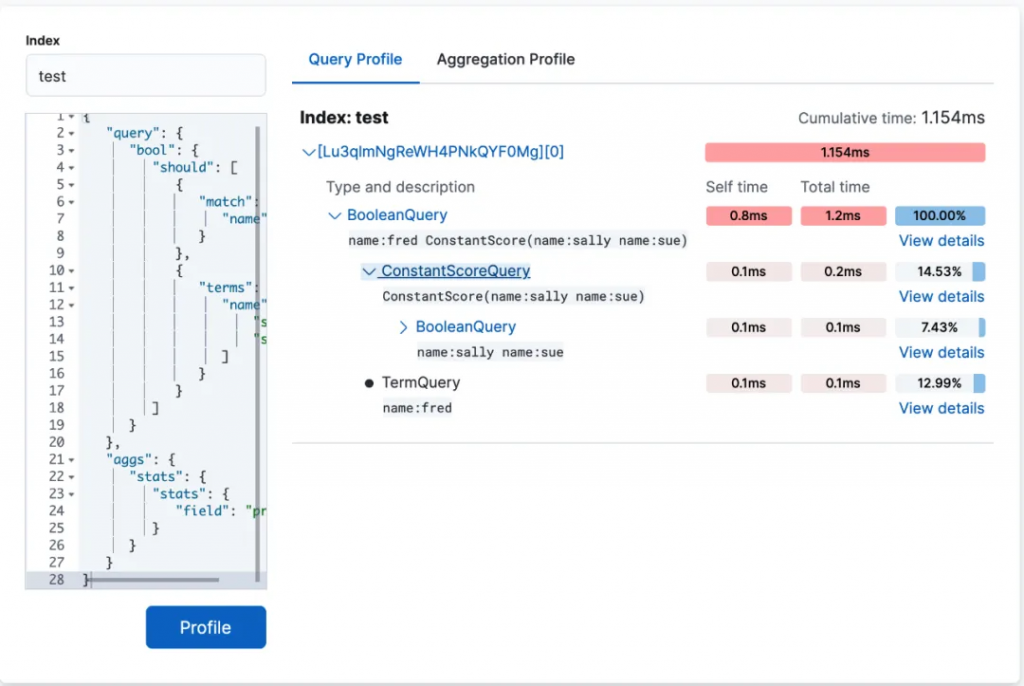
除了 query 階段,也可以看到有 aggregation 聚合階段。
view detail 我們還可以看到各個執行方法的耗時。
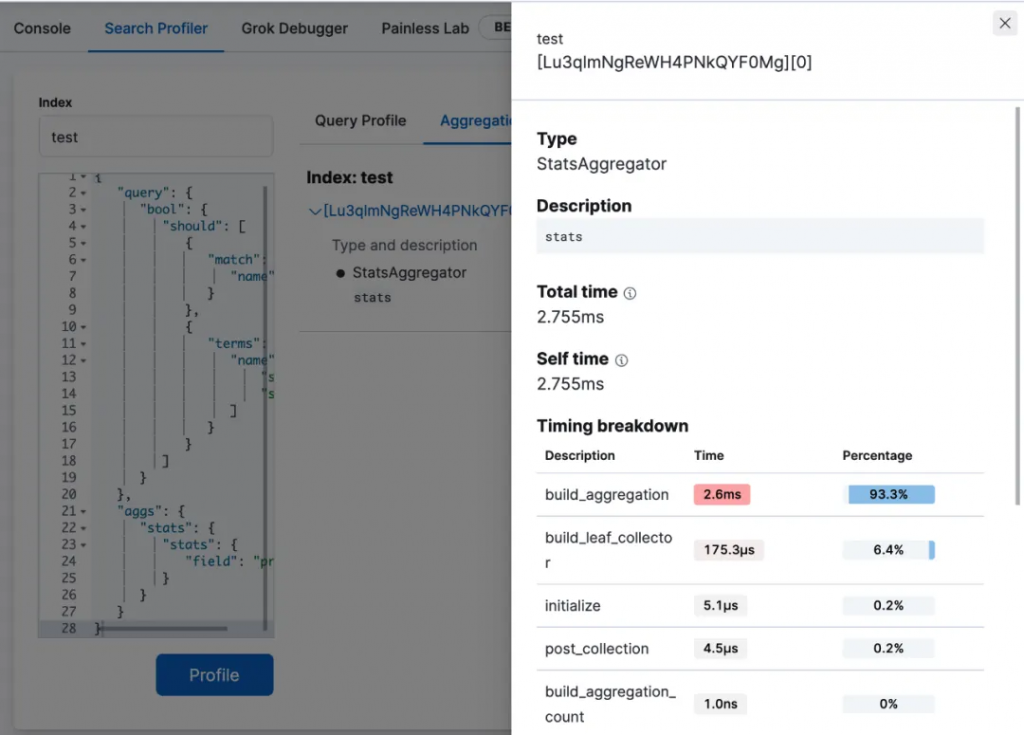
除了解析執行語句,也可以直接解析 profile 結果,將 profile API 返回 json 數據直接貼入查詢 DSL (Elasticsearch 查詢語句)的區域執行。
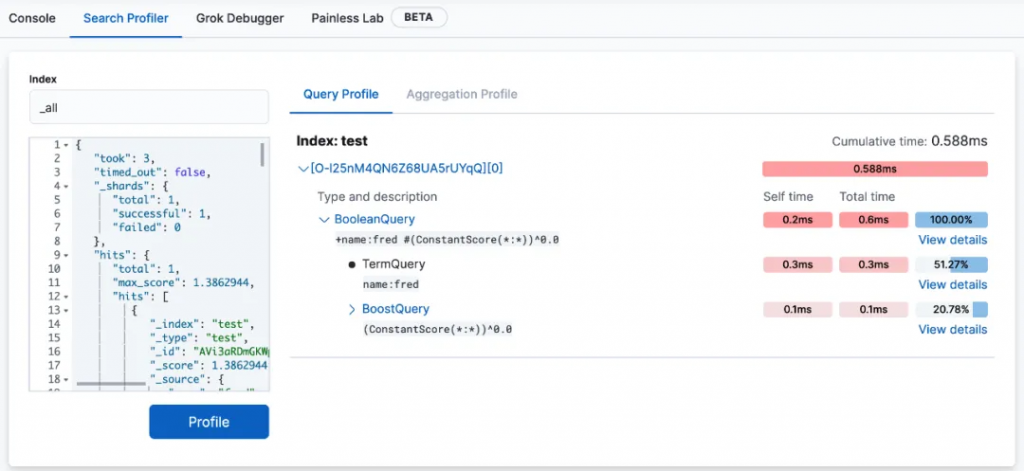
不管是 Profile API 還是 kibana 的 Search Profiler,提供的只是 ES 執行查詢各階段的方法細節。
想要判斷出各個階段的執行效率是否最佳,有沒有使用誤區,我們還得從 ES 查詢主要階段說起。
ES 是一個分布式系統,一個索引數據查詢需要匯總每個索引分片的結果。
如下圖,search 請求發送給 ES 后,會由內部的協調節點發送到數據節點,由數據節點上的分片去執行具體的查詢任務。
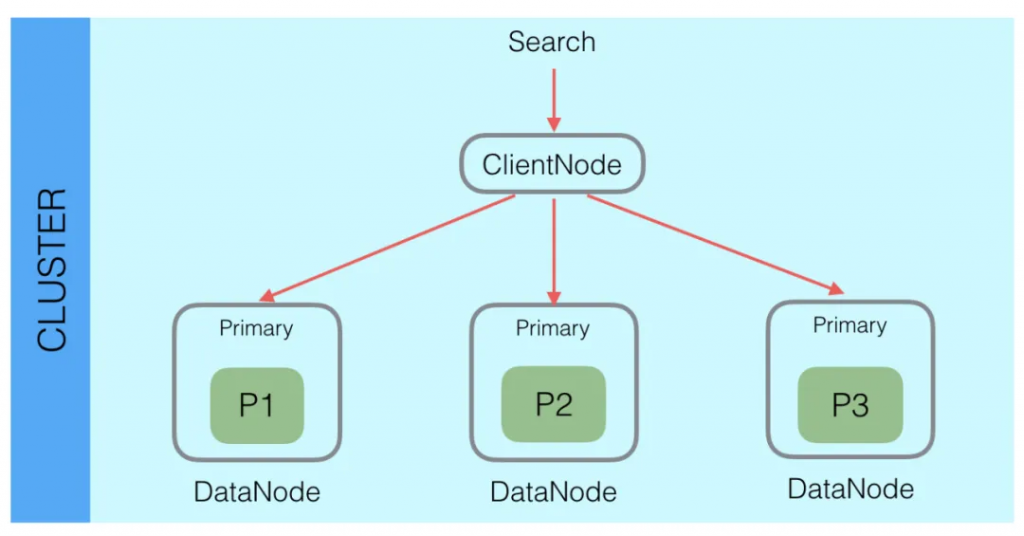
同時,大多數的 ES 查詢請求是一個二階段的查詢。
第一階段數據節點上的分片接收到協調節點傳來的查詢請求,分片執行查詢任務后,會將查詢到匹配的 DocID 反饋給協調節點,協調節點會對各個分片的結果進行匯總。
第二階段協調節點根據匯總后的 DocID,到數據對應的分片上去獲取完整文檔。
整個過程叫做 query and fetch,query 和 fetch 也是分片在這兩個階段主要執行的任務,也是 profile 主要分析的階段(低版本只分析 query 階段)。
進行二階段查詢的主要原因是為了減少 fetch 階段的資源損耗,獲取完整的文檔信息涉及數據文件的讀取和解壓縮,需要相對多的 IO 和 cpu 資源。
為了保證數據的召回率和準確性,query 階段需要在每個分片上獲取查詢完整結果,比如一個查詢需要 Top 10 的結果,每個分片都會找出它的 Top 10,返回給協調節點。如果有 10 個分片,那么就需要返回 100 個結果,再由協調節點排出所有分片的 Top 10。
如果由一階段完成,則需要 fetch 100 個文檔,二階段則只需要 fetch 10 個文檔。
完整的二階段查詢流程如下圖:
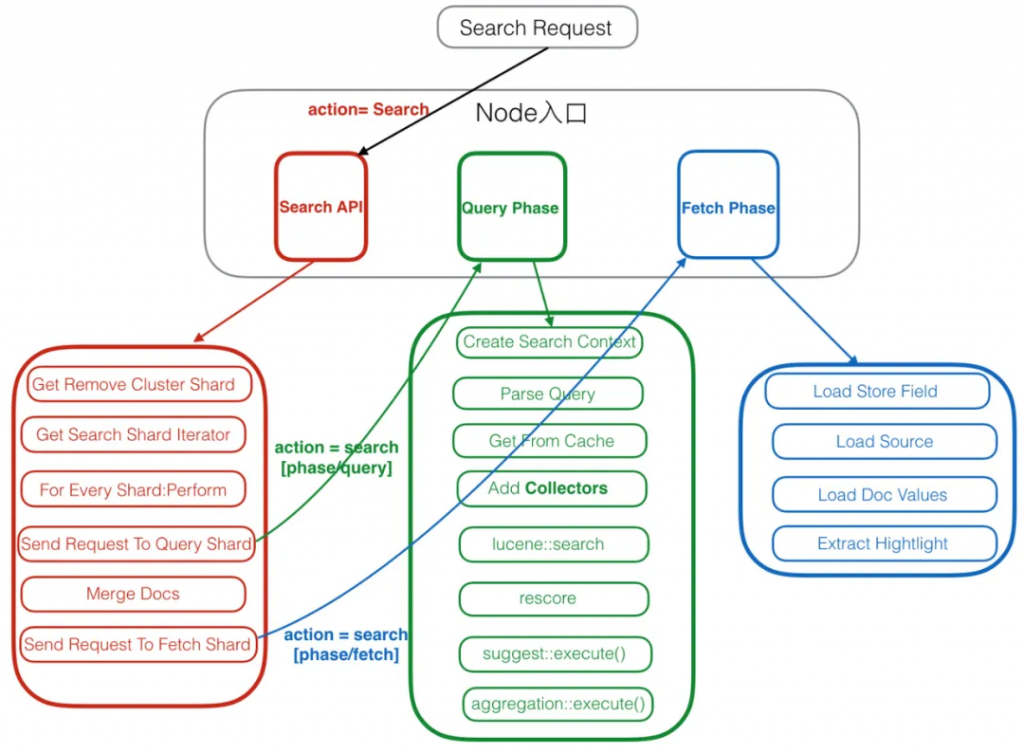
注:這里的流程圖來自于文末的參考文檔《Elasticsearch內核解析 – 查詢篇》
現在我們來看看 Profile API 可以解析的階段。
Query 階段是一階段查詢的主體,我理解是主要在二階段查詢流程中lucene::search和rescore這2個環節,這里 Profile API 將查詢涉及的 lucene 執行代碼類構成的一個查詢樹,這個查詢樹通過名稱和描述把查詢條件與執行類進行完整的勾兌,這樣可以精確定位到是哪個查詢條件造成了慢查詢的主要耗時。
查詢樹重寫的過程是將查詢語句拆分成一個個不可被拆解的基礎查詢(比如 term 查詢)的過程。
大部分時候查詢樹的結構與查詢 DSL 的結構相似,有些情況下會重寫的面目全非,比如:ngram 分詞器,它會根據 ngram 分詞器將查詢內容進行細維度的拆解,最終形成一大堆 TermQuery。
下面一個例子是一個 match 查詢的拆解,首先來看查詢條件。
GET /_search
{
"query": {
"match": {
"message": {
"query": "get search"
}
}
}
}返回的結果。
"query": [
{
"type": "BooleanQuery",
"description": "message:get message:search",
"time_in_nanos": "11972972",
"breakdown": {...},
"children": [
{
"type": "TermQuery",
"description": "message:get",
"time_in_nanos": "3801935",
"breakdown": {...}
},
{
"type": "TermQuery",
"description": "message:search",
"time_in_nanos": "205654",
"breakdown": {...}
}
]
}
]這里的主要過程:
message:get message:search,展現了其總耗時(包括它的子查詢耗時)和 breakdown。值得注意的是,Query 階段是 ES 查詢中最容易出現慢查詢的階段。
Collector 也由各類的子 Collector 組成,它們的主要目標是在分片內收集各個 segment 的查詢結果,實現排序,對自定義結果集過濾和收集等,這也導致了在查詢流程中,Add Collectors在執行 lucene 的 search 之前。
Collector 耗時獨立于 Query 耗時。
它們是獨立進行計算和組合的。由于 Lucene 執行的性質,不可能將來自 Collector 的耗時“合并”到 Query 部分。
"collector": [
{
"name": "QueryPhaseCollector",
"reason": "search_query_phase",
"time_in_nanos": 775274,
"children" : [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 775274
}
]
}
]Collector 提供的信息相對較少只提供了名稱/原因/耗時。各類原因如下:
Lucene中的所有查詢都經歷了一個“重寫”過程。查詢(及其子查詢)可能被重寫一次或多次,直到只剩基礎查詢。
這個過程允許Lucene執行優化,例如刪除冗余子句,替換一個查詢以獲得更有效的執行路徑等。
例如,Boolean→Boolean→TermQuery可以重寫為TermQuery,最終把 boolean 查詢全都解析完。Query 查詢樹的變化也正是這個重寫過程的體現。
重寫過程復雜且難以顯示,因為查詢可能會發生巨大變化。總重寫時間不是顯示中間結果,該值是累積的,包含重寫所有查詢的總時間。
聚合部分的結構與 Query 部分類似,也是將查詢樹的結構展現出來。
有時候聚合可能會返回 debug 信息,這些信息描述了聚合的底層執行的特性,但大部分情況下沒什么用。隨著版本、聚合和聚合執行策略等條件的變化,這些信息差異很大。
這個就是二階段查詢中 fetch 階段的耗時分析。
其主要內容就是加載 store_field/source/docvalue 三類存儲信息。使用者也可以根據這三類字段處理格式的使用耗時,進行實際方案的選擇。
其中,next_reader展示的是每個 segment 的讀取計數和耗時,load_stored_fields中加載存儲字段所花費的時間。
Debug 包含的是一些非耗時信息,特別是會展示 stored_fields 列出的 fetch 必須加載的存儲字段;如果它是一個空列表,那么 fetch 將完全跳過加載存儲字段。
當然 Profile API 和 kibana 的 Search Profiler 也有相關的使用限制:
在 Elasticsearch 中,分片是一個最小級別的“工作單元”,它保存了索引中所有數據的一部分,同時每一個分片還是一個Lucene實例。
因此 Elasticsearch 分片執行查詢過程基礎類都與 lucene 相關,了解 lucene 的查詢類可以增加對查詢執行細節的理解。
相比起 lucene 的學習成本,Profile API 則提供了一種更為直觀高效又低成本的慢查詢分析工具。
通過聚焦各個執行階段的耗時,我們直接可以定位到最大耗時的查詢條件,它有可能是整個查詢過于復雜,也有可能是某個字段類型不適合查詢的場景。
也就是說,解決慢查詢的方法并不一定要從 ES/lucene 本身去尋找,因為造成慢查詢的原因并不只源于程序本身,它會是各種各樣的原因,甚至是系統配置的錯誤、網絡不穩定等等。
而 Profile API 給我們提供了更直接的印證。
除了使用 Profile API 定位耗時的查詢條件外,這里附帶一些慢查詢優化的建議,供讀者參考:
ES 設計了多種緩存模式,有效利用緩存能保持查詢的低延遲,做好緩存的監控。
特別是針對關鍵詞字段,number 和 keyword 類型在查詢和聚合方面有完全不同的查詢效率,資源足夠的情況下,設計雙字段。
有興趣的讀一下這篇,
https://elasticsearch.cn/article/446
精確匹配注重查詢效率但是需要設計好數據模型;
全文檢索可以面對自然語言信息的提煉,但是解析效果依賴分詞器,并占用資源較多。
MultiTermQuery 是 wildcard/正則/前綴等查詢常見的執行子類,這些查詢容易引發大規模的資源消耗。
Fetch 階段的高耗時,可以通過行存屬性 source 與列存屬性 doc value 的讀取測試比較來選取最優方案。
這里的介紹主要用于參考,lucene 實現類的方法是各種基礎算法的實現,優化或者規避這些方法造成的高耗時需要對 ES 源碼以及 lucene 數據文件有相當的理解和知識儲備。
這也導致了,即便能看到慢查詢具體的花費時間在哪個方法上,你也沒辦法輕易的改變它(除非自己重新實現基礎的算法去維護私有版本或者貢獻給社區 PR)。
每個階段各個主要方法的耗時體現在 breakdown 內,下面做了詳盡匯總,僅供參考:
| 方法名 | 含義 | 涉及lucene的類或者方法 |
|---|---|---|
| create_weight | Lucene要求每個查詢生成一個Weight對象,這個對象作為一個臨時上下文對象來保存多個IndexSearcher與query相關的狀態。權重度量顯示了這個過程需要多長時間 | Query抽象類createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost):Constructs an appropriate Weight implementation for this query. |
| build_scorer | 此參數顯示為查詢構建Scorer所需的時間。Scorer是一種迭代匹配文檔并為每個文檔生成分數的機制(例如,“foo”與文檔的匹配程度如何?)注意,這記錄了生成Scorer對象所需的時間,而不是實際對文檔進行評分。一些查詢的Scorer初始化速度更快或更慢,這取決于優化、復雜性等。如果啟用和/或適用于查詢,這還可以顯示與緩存相關的時間 | Scorer抽象類:A Scorer exposes an iterator() over documents matching a query in increasing order of doc id. |
| next_doc | Lucene 方法next_doc返回與查詢匹配的下一個文檔的 Doc ID。此統計數據顯示確定下一個匹配的文檔所需的時間,該過程根據查詢的性質而有很大差異,不同的實現類以及數據結構會有完全不同的效率。Next_doc 是 advance() 的一種特殊形式,對于 Lucene 中的許多查詢來說更為方便。它相當于 advance(docId() + 1) | DISI 抽象類 nextDoc():Advances to the next document in the set and returns the doc it is currently on, or NO_MORE_DOCS if there are no more docs in the set. |
| advance | advance是 next_doc 的“低級”版本:它用于查找下一個匹配的文檔,但需要調用查詢執行額外的任務,例如識別和跳過跳過等。但是,并非所有查詢都可以使用 next_doc,因此advance這些查詢也會計時。 | DISI抽象類 advance(int target):Advances to the first beyond the current whose document number is greater than or equal to target, and returns the document number itself. |
| match | 某些查詢(例如短語查詢)使用“兩階段”過程匹配文檔。首先,文檔“近似”匹配,如果近似匹配,則使用更嚴格(且昂貴)的過程再次檢查。第二階段驗證是統計數據所衡量的match。由于只有少數查詢使用這個兩階段過程,因此match統計數據通常為零 | PhraseMatcher類:Base class for exact and sloppy phrase matching |
| score | 這記錄了通過評分器對特定文檔進行 Scorer 所花費的時間 | Scorer 抽象類 score():Returns the score of the current document matching the query. |
| *_count | 記錄特定方法的調用次數。例如,”next_doc_count”: 2, 表示該nextDoc()方法在兩個不同的文檔上被調用。這可以通過比較不同查詢類之間的計數來幫助判斷查詢的選擇性。 |
| 方法名 | 含義 |
|---|---|
| build_aggregation | 創建聚合對象需要的時間 |
| initialize | 初始化聚合所耗費的時間 |
| collect | 對聚合結果進行 collect |
| build_leaf_collector | 運行聚合的 getLeafCollector() 方法所花費的時間 |
| post_collection | post 查詢 collect 耗時 |
| reduce | reduce 屬性保留以供將來使用,并且總是返回0 |
| *_count | 記錄特定方法的調用次數 |
[1] kibana search profiler:
https://www.elastic.co/guide/en/kibana/current/xpack-profiler.html
[2] Profile API:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-profile.html
[3] Elasticsearch內核解析 – 查詢篇:
https://zhuanlan.zhihu.com/p/34674517
金多安,Elastic 認證專家,Elastic 資深運維工程師,死磕 Elasticsearch 知識星球嘉賓,星球Top活躍技術專家,搜索客社區日報責任編輯
銘毅天下審稿并做了部分微調。
本文章轉載微信公眾號@SearchKit






