
設計類API:為您的應用程序賦予強大的設計能力
機器學習是人工智能的一個子集,可以進行優化。如果設置得當,它可以幫助你進行預測,最大限度地減少僅憑猜測而產生的錯誤。例如,亞馬遜等公司利用機器學習,根據特定客戶之前查看和購買過的產品向其推薦產品。
經典或 “非深度 “機器學習依賴于人工干預,使計算機系統能夠識別模式、學習、執行特定任務并提供準確結果。人類專家決定特征的層次結構,以了解數據輸入之間的差異,通常需要更多的結構化數據來學習。
例如,假設我向你展示了一系列不同類型快餐的圖片–“披薩”、”漢堡 “和 “玉米卷”。人類專家在處理這些圖片時,會判斷出每張圖片區別于特定快餐類型的特征。每種食品中的面包可能就是一個區分特征。或者,他們也可以使用標簽,如 “披薩”、”漢堡 “或 “玉米卷”,通過監督學習來簡化學習過程。
雖然被稱為深度機器學習的人工智能子集可以在監督學習中利用標簽數據集為算法提供信息,但它并不一定需要標簽數據集。它可以攝取原始形式的非結構化數據(如文本、圖像),并能自動確定將 “披薩”、”漢堡 “和 “玉米卷 “區分開來的特征集。隨著我們產生更多的大數據,數據科學家將使用更多的機器學習。如需深入了解這些方法之間的差異,請參閱《監督學習與非監督學習》(Supervised vs. Unsupervised Learning):有什么區別?
機器學習的第三類是強化學習,即計算機通過與周圍環境互動并獲得行動反饋(獎勵或懲罰)來學習。在線學習是一種 ML,數據科學家會在獲得新數據時更新 ML 模型。
正如我們關于深度學習的文章所述,深度學習是機器學習的一個子集。機器學習和深度學習的區別在于每種算法如何學習,以及每種算法使用多少數據。
深度學習能自動完成大部分特征提取工作,從而省去了部分人工干預。它還能使用大型數據集,因此被稱為可擴展的機器學習。當我們進一步探索非結構化數據的使用時,這種能力令人興奮,特別是因為據估計,一個組織 80% 以上的數據都是非結構化的。
觀察數據中的模式可以讓深度學習模型對輸入進行適當的聚類。以前面的例子為例,我們可以根據圖像中的相似點或不同點,將披薩、漢堡和墨西哥卷餅的圖片歸入各自的類別。深度學習模型需要更多的數據點來提高準確性,而機器學習模型由于其底層數據結構,所依賴的數據更少。企業通常將深度學習用于更復雜的任務,如虛擬助手或欺詐檢測。
機器學習和深度學習的區別常見問題FAQ

神經網絡,也稱為人工神經網絡(ANN)或模擬神經網絡(SNN),是機器學習的一個子集,也是深度學習算法的支柱。它們之所以被稱為 “神經 “網絡,是因為它們模仿了大腦神經元相互傳遞信號的方式。
神經網絡由節點層(一個輸入層、一個或多個隱藏層和一個輸出層)組成。每個節點都是連接下一個節點的人工神經元,每個節點都有權重和閾值。當一個節點的輸出高于閾值時,該節點就會被激活,并將數據發送到網絡的下一層。如果低于閾值,則沒有數據傳輸。
訓練數據可以教導神經網絡,并有助于隨著時間的推移提高其準確性。一旦對學習算法進行了微調,它們就會成為強大的計算機科學和人工智能工具,因為它們能讓我們快速對數據進行分類和聚類。利用神經網絡,語音和圖像識別任務可以在幾分鐘內完成,而不是像人工識別那樣需要幾個小時。谷歌的搜索算法就是神經網絡的一個著名例子。
了解了機器學習和深度學習的區別之后,我們再來了解下深度學習和神經網絡的區別,如上文對神經網絡的解釋所述,但值得更明確地指出的是,深度學習中的 “深度 “指的是神經網絡的層深度。包括輸入和輸出在內,層數超過三層的神經網絡可視為深度學習算法。這可以用下圖來表示:
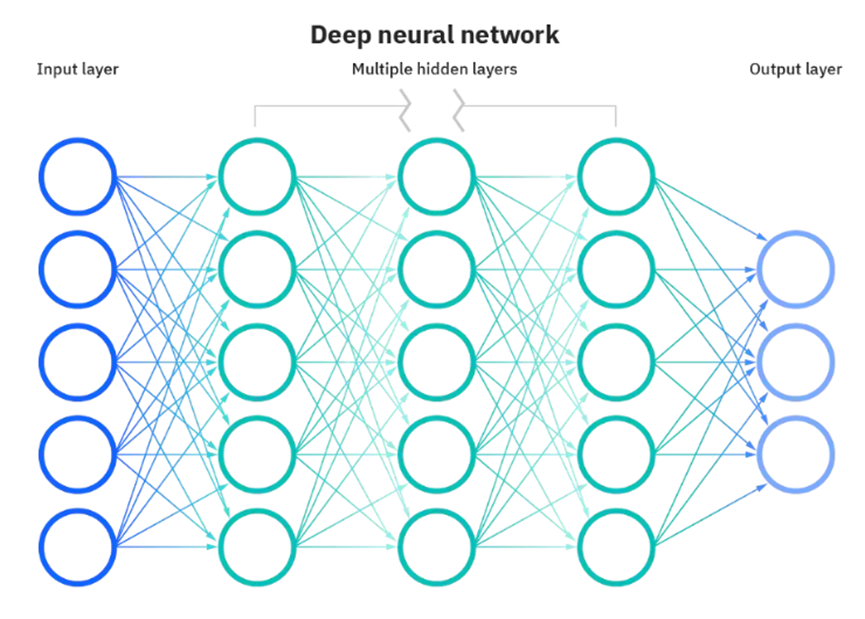
大多數深度神經網絡都是前饋式的,這意味著它們只能從輸入向輸出單向流動。不過,您也可以通過反向傳播來訓練模型,即從輸出到輸入的反向傳播。通過反向傳播,我們可以計算和歸因與每個神經元相關的誤差,從而對算法進行適當的調整和調整。
雖然所有這些人工智能領域都能幫助您簡化業務領域并改善客戶體驗,但實現人工智能目標可能具有挑戰性,因為您首先需要確保擁有正確的系統來構建學習算法并管理數據。數據管理不僅僅是建立業務模型。在開始構建任何東西之前,您需要一個存儲數據的地方以及清理數據和控制偏差的機制。
在 IBM,我們正在將機器學習和人工智能的力量結合到我們用于基礎模型、生成式人工智能和機器學習的新工作室 watsonx.ai。
原文鏈接:AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the difference?





