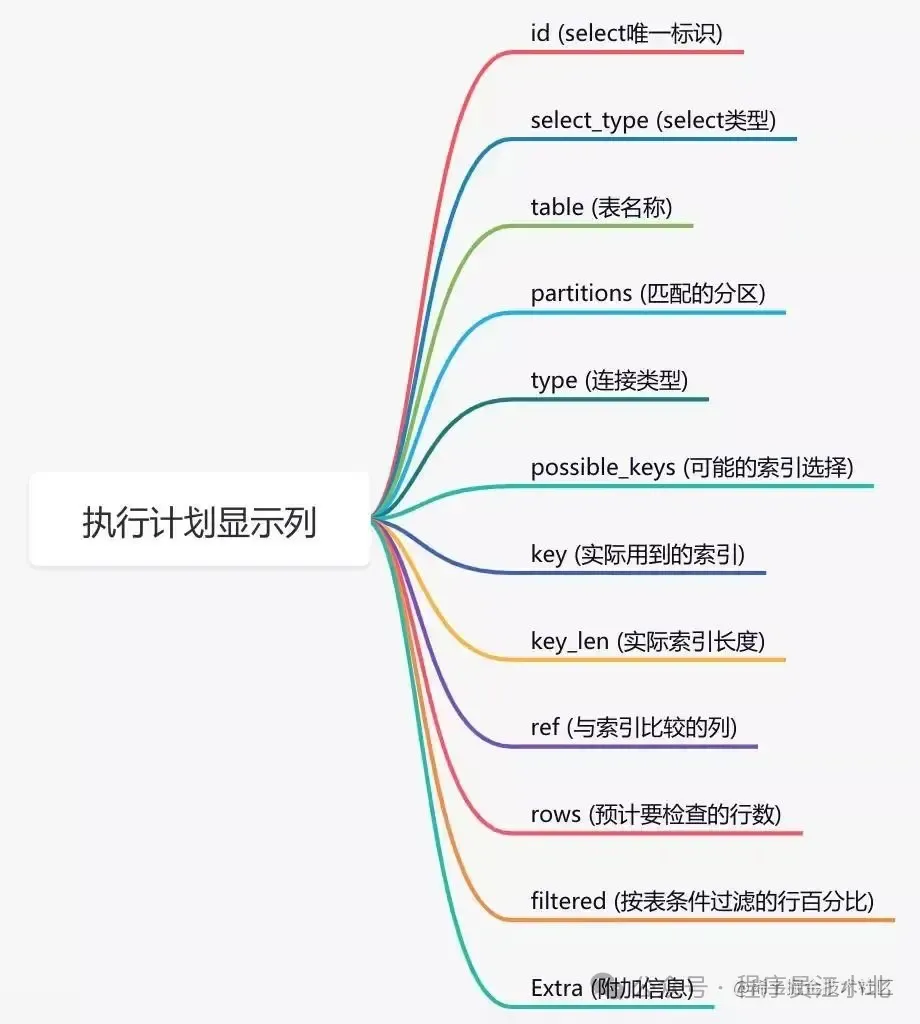
這個命令將顯示查詢的執行計劃,包括使用了哪些索引。
如果索引生效,你會在輸出結果中看到相關的信息。
通過這幾列可以判斷索引使用情況,執行計劃包含列的含義如下圖所示:
說實話,SQL語句沒有使用索引,除去沒有建索引的情況外,最大的可能性是索引失效了。
以下是索引失效的常見原因:
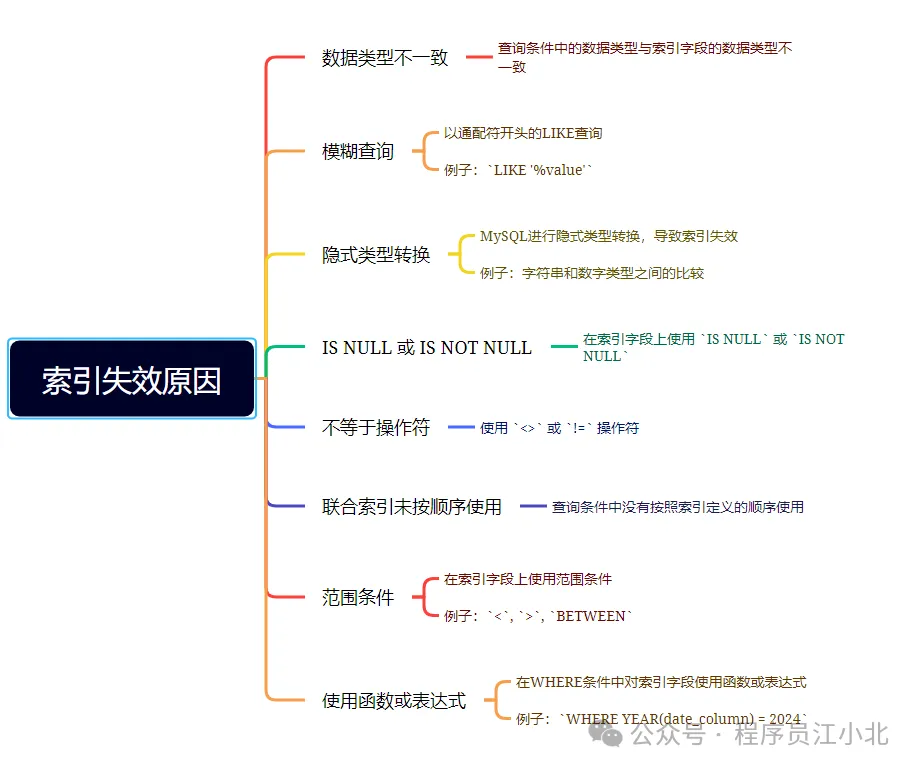
了解這些原因,可以幫助你在查詢優化時避免索引失效的問題,確保數據庫查詢性能保持最佳。
此外,你是否遇到過這樣一種情況:明明是同一條SQL語句,只是入參不同。
有時候使用的是索引A,有時候卻使用索引B?
沒錯,有時候MySQL會選錯索引。
必要時可以使用 FORCE INDEX 來強制查詢SQL使用某個索引。
例如:SELECT * FROM order FORCE INDEX (index_name) WHERE code='002';
至于為什么MySQL會選錯索引,原因可能有以下幾點:
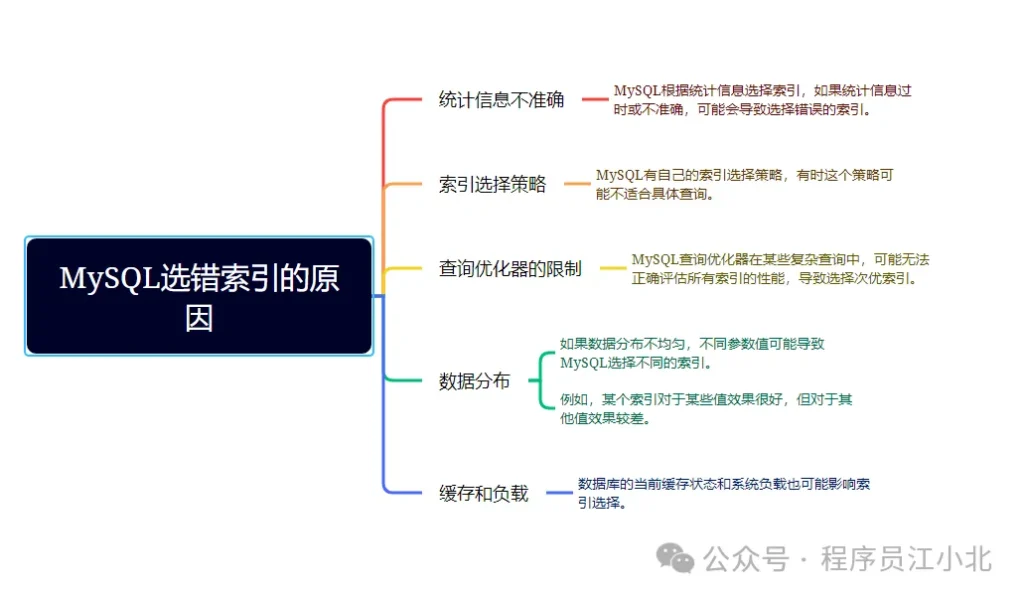
了解這些原因,可以幫助你更好地理解和控制MySQL的索引選擇行為,確保查詢性能的穩定性。
插播一條:如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題。
如果優化了索引之后效果不明顯,接下來可以嘗試優化一下SQL語句,因為相對于修改Java代碼來說,改造SQL語句的成本要小得多。
以下是SQL優化的15個小技巧:

多時候,我們需要在一個接口中調用其他服務的接口。
例如,有這樣的業務場景:
在用戶信息查詢接口中需要返回以下信息:用戶名稱、性別、等級、頭像、積分和成長值。
其中,用戶名稱、性別、等級和頭像存儲在用戶服務中,積分存儲在積分服務中,成長值存儲在成長值服務中。為了將這些數據統一返回,我們需要提供一個額外的對外接口服務。
因此,用戶信息查詢接口需要調用用戶查詢接口、積分查詢接口和成長值查詢接口,然后將數據匯總并統一返回。
調用過程如下圖所示:
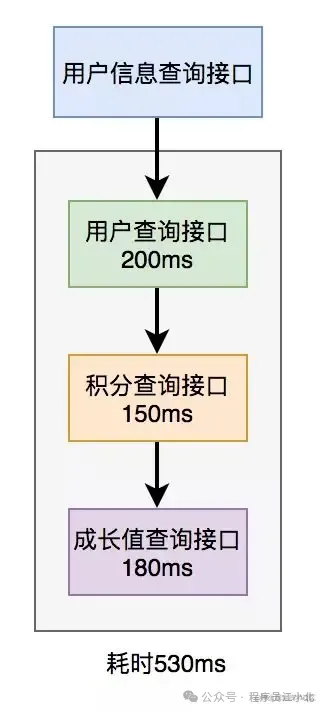
調用遠程接口總耗時 530ms = 200ms + 150ms + 180ms
顯然這種串行調用遠程接口性能是非常不好的,調用遠程接口總的耗時為所有的遠程接口耗時之和。
那么如何優化遠程接口性能呢?
上面說到,既然串行調用多個遠程接口性能很差,為什么不改成并行呢?
如下圖所示:
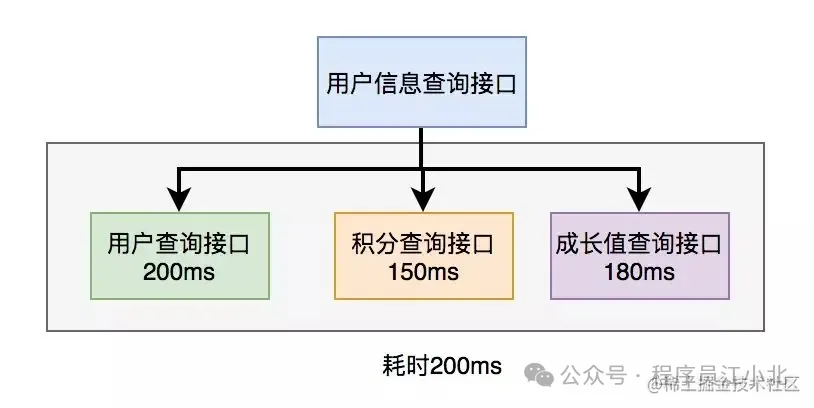
調用遠程接口的總耗時為200ms,這等于耗時最長的那次遠程接口調用時間。
在Java 8之前,可以通過實現Callable接口來獲取線程的返回結果。
在Java 8之后,可以通過CompletableFuture類來實現這一功能。
以下是一個使用CompletableFuture的示例:
public?class?RemoteServiceExample?{
????public?static?void?main(String[]?args)?throws?ExecutionException,?InterruptedException?{
????????//?調用用戶服務接口
????????CompletableFuture<String>?userFuture?=?CompletableFuture.supplyAsync(()?->?{
????????????//?模擬遠程調用
????????????simulateDelay(200);
????????????return?"User?Info";
????????});
????????//?調用積分服務接口
????????CompletableFuture<String>?pointsFuture?=?CompletableFuture.supplyAsync(()?->?{
????????????//?模擬遠程調用
????????????simulateDelay(150);
????????????return?"Points?Info";
????????});
????????//?調用成長值服務接口
????????CompletableFuture<String>?growthFuture?=?CompletableFuture.supplyAsync(()?->?{
????????????//?模擬遠程調用
????????????simulateDelay(100);
????????????return?"Growth?Info";
????????});
????????//?匯總結果
????????CompletableFuture<Void>?allOf?=?CompletableFuture.allOf(userFuture,?pointsFuture,?growthFuture);
????????//?等待所有異步操作完成
????????allOf.join();
????????//?獲取結果
????????String?userInfo?=?userFuture.get();
????????String?pointsInfo?=?pointsFuture.get();
????????String?growthInfo?=?growthFuture.get();
????}
}為了提升接口性能,尤其在高并發場景下,可以考慮數據冗余,將用戶信息、積分和成長值的數據統一存儲在一個地方,比如Redis。
這樣,通過用戶ID可以直接從Redis中查詢所需的數據,從而避免遠程接口調用
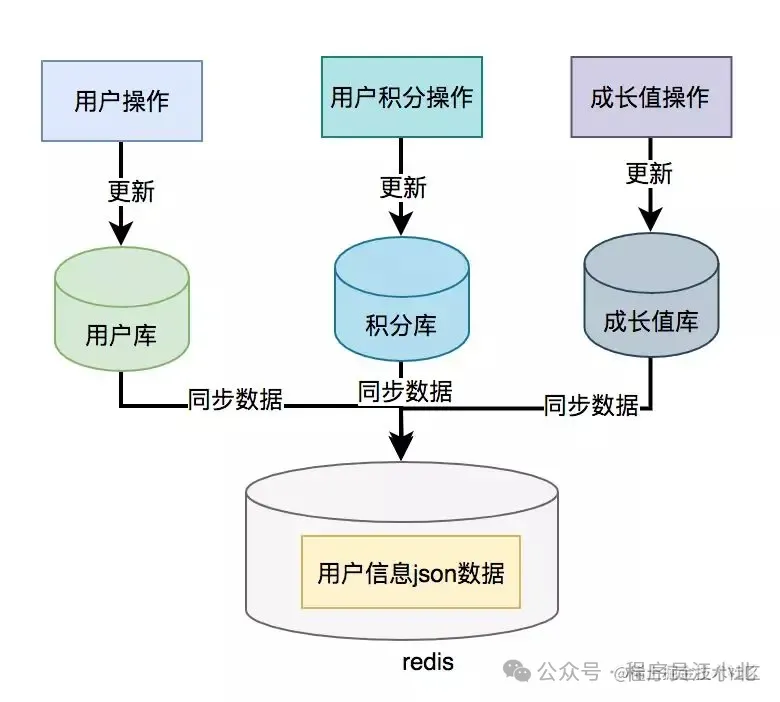
但需要注意的是,如果使用了數據異構方案,就可能會出現數據一致性問題。
用戶信息、積分和成長值有更新的話,大部分情況下,會先更新到數據庫,然后同步到redis。
但這種跨庫的操作,可能會導致兩邊數據不一致的情況產生。
那如何解決數據一致性問題呢?
由于篇幅有限,本文就不展開詳細說這塊了,感興趣的同學可以看我的另一篇文章《億級電商流量,高并發下Redis與MySQL的數據一致性如何保證》
在我們的日常工作代碼中,重復調用非常常見,但如果沒有控制好,會嚴重影響接口的性能。
讓我們一起來看看這個問題。
4.1 循環查數據庫 有時候,我們需要從指定的用戶集合中查詢出哪些用戶已經存在于數據庫中。
一種實現方式如下:
public?List<User>?findExistingUsers(List<String>?userIds)?{
????List<User>?existingUsers?=?new?ArrayList<>();
????for?(String?userId?:?userIds)?{
????????User?user?=?userRepository.findById(userId);
????????if?(user?!=?null)?{
????????????existingUsers.add(user);
????????}
????}
????return?existingUsers;
}上述代碼會對每個用戶ID執行一次數據庫查詢,這在用戶集合較大時會導致性能問題。
那么,我們如何優化呢?
我們可以通過批量查詢來優化性能,減少數據庫的查詢次數。public?List<User>?findExistingUsers(List<String>?userIds)?{
????//?批量查詢數據庫
????List<User>?users?=?userRepository.findByIds(userIds);
????return?users;
}
這里有個需要注意的地方是:id集合的大小要做限制,最好一次不要請求太多的數據。要根據實際情況而定,建議控制每次請求的記錄條數在500以內。
在進行接口性能優化時,有時候需要重新梳理業務邏輯,檢查是否存在設計不合理的地方。
假設有一個用戶請求接口,需要執行以下操作:
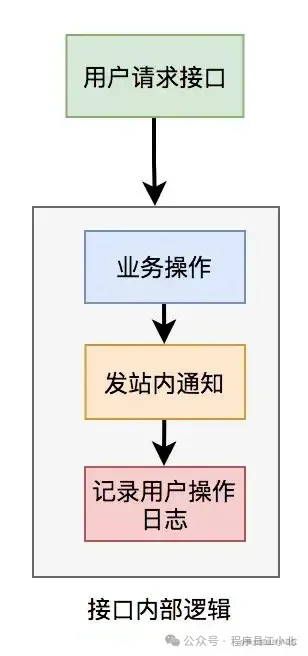
這個接口表面上看起來沒有問題,但如果你仔細梳理一下業務邏輯,會發現只有業務操作才是核心邏輯,其他的功能都是非核心邏輯。
在這里有個原則就是:
核心邏輯可以同步執行,同步寫庫。非核心邏輯,可以異步執行,異步寫庫。
上面這個例子中,發站內通知和用戶操作日志功能,對實時性要求不高,即使晚點寫庫,用戶無非是晚點收到站內通知,或者運營晚點看到用戶操作日志,對業務影響不大,所以完全可以異步處理。
異步處理方案
異步處理通常有兩種主要方式:多線程和消息隊列(MQ)
使用線程池改造之后,接口邏輯如下
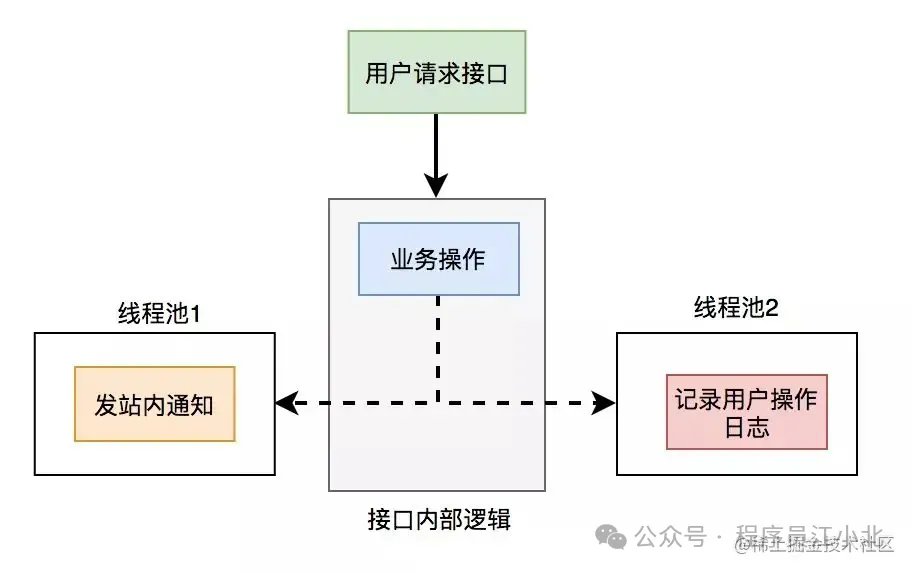
使用線程池有個小問題就是:如果服務器重啟了,或者是需要被執行的功能出現異常了,無法重試,會丟數據。
為了避免使用線程池處理異步任務時出現數據丟失的問題,可以考慮使用更加健壯和可靠的異步處理方案,如消息隊列(MQ)。消息隊列不僅可以異步處理任務,還能夠保證消息的持久化和可靠性,支持重試機制。
使用mq改造之后,接口邏輯如下:
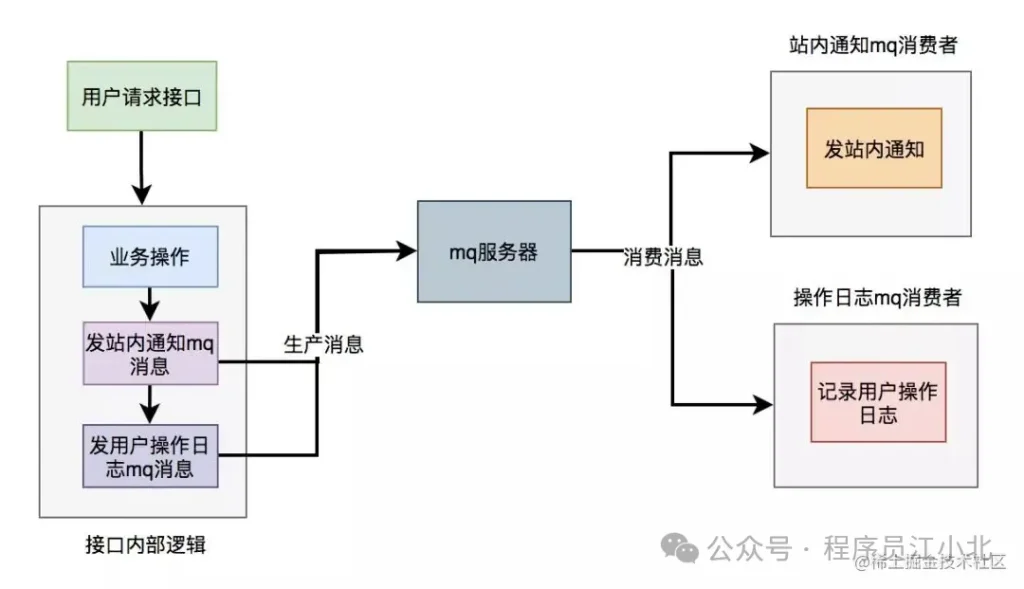
插播一條:如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題。
很多小伙伴在使用Spring框架開發項目時,為了方便,喜歡使用@Transactional注解提供事務功能。
沒錯,使用@Transactional注解這種聲明式事務的方式提供事務功能,確實能少寫很多代碼,提升開發效率。
但也容易造成大事務,引發性能的問題。
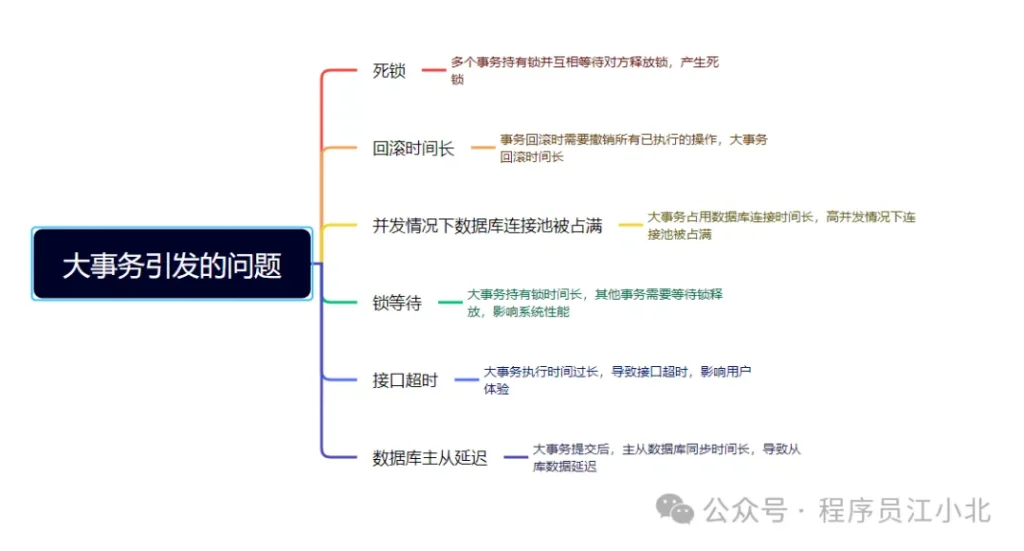
那么我們該如何優化大事務呢?
為了避免大事務引發的問題,可以考慮以下優化建議:
在一些業務場景中,為了避免多個線程并發修改同一共享數據而引發數據異常,通常我們會使用加鎖的方式來解決這個問題。
然而,如果鎖的設計不當,導致鎖的粒度過粗,也會對接口性能產生顯著的負面影響。
在Java中,我們可以使用synchronized關鍵字來為代碼加鎖。
通常有兩種寫法:在方法上加鎖和在代碼塊上加鎖。
1. 方法上加鎖
public?synchronized?void?doSave(String?fileUrl)?{
????mkdir();
????uploadFile(fileUrl);
????sendMessage(fileUrl);
}在方法上加鎖的目的是為了防止并發情況下創建相同的目錄,避免第二次創建失敗而影響業務功能。
但這種直接在方法上加鎖的方式,鎖的粒度較粗。
因為doSave方法中的文件上傳和消息發送并不需要加鎖,只有創建目錄的方法需要加鎖。
我們知道,文件上傳操作非常耗時,如果將整個方法加鎖,那么需要等到整個方法執行完之后才能釋放鎖。
顯然,這會導致該方法的性能下降,得不償失。
2. 代碼塊上加鎖我們可以將加鎖改在代碼塊上,從而縮小鎖的粒度, 如下:
public?void?doSave(String?path,?String?fileUrl)?{
????synchronized(this)?{
????????if?(!exists(path))?{
????????????mkdir(path);
????????}
????}
????uploadFile(fileUrl);
????sendMessage(fileUrl);
}這樣改造后,鎖的粒度變小了,只有并發創建目錄時才加鎖。
創建目錄是一個非常快的操作,即使加鎖對接口性能的影響也不大。
最重要的是,其他的文件上傳和消息發送功能仍然可以并發執行。
多節點環境中的問題 在單機版服務中,這種做法沒有問題。但在生產環境中,為了保證服務的穩定性,同一個服務通常會部署在多個節點上。如果某個節點掛掉,其他節點的服務仍然可用。
多節點部署避免了某個節點掛掉導致服務不可用的情況,同時也能分攤整個系統的流量,避免系統壓力過大。
但這種部署方式也帶來了新的問題:synchronized只能保證一個節點加鎖有效。
如果有多個節點,如何加鎖呢?
在分布式系統中,由于Redis分布式鎖的實現相對簡單且高效,因此它在許多實際業務場景中被廣泛采用。
使用Redis分布式鎖的偽代碼如下:
public?boolean?doSave(String?path,?String?fileUrl)?{
????try?{
????????String?result?=?jedis.set(lockKey,?requestId,?"NX",?"PX",?expireTime);
????????if?("OK".equals(result))?{
????????????if?(!exists(path))?{
????????????????mkdir(path);
????????????????uploadFile(fileUrl);
????????????????sendMessage(fileUrl);
????????????}
????????????return?true;
????????}
????}?finally?{
????????unlock(lockKey,?requestId);
????}
????return?false;
}與之前使用synchronized關鍵字加鎖時一樣,這里的鎖的范圍也太大了,換句話說,鎖的粒度太粗。這會導致整個方法的執行效率很低。
實際上,只有在創建目錄時才需要加分布式鎖,其余代碼不需要加鎖。
于是,我們需要優化代碼:
public?void?doSave(String?path,?String?fileUrl)?{
????if?(tryLock())?{
????????try?{
????????????if?(!exists(path))?{
????????????????mkdir(path);
????????????}
????????}?finally?{
????????????unlock(lockKey,?requestId);
????????}
????}
????uploadFile(fileUrl);
????sendMessage(fileUrl);
}
private?boolean?tryLock()?{
????String?result?=?jedis.set(lockKey,?requestId,?"NX",?"PX",?expireTime);
????return?"OK".equals(result);
}
private?void?unlock(String?lockKey,?String?requestId)?{
????//?解鎖邏輯
}上面的代碼將加鎖的范圍縮小了,只有在創建目錄時才加鎖。這樣的簡單優化后,接口性能可以得到顯著提升。
并發度越高,接口性能越好。因此,數據庫鎖的優化方向是:
插播一條:如果你近期準備面試跳槽,建議在cxykk.com在線刷題,涵蓋 1萬+ 道 Java 面試題,幾乎覆蓋了所有主流技術面試題、簡歷模板、算法刷題。
有時候,我需要調用某個接口來批量查詢數據,例如,通過用戶ID批量查詢用戶信息,然后為這些用戶贈送積分。
但是,如果一次性查詢的用戶數量太多,例如一次查詢2000個用戶的數據,傳入2000個用戶的ID進行遠程調用時,用戶查詢接口經常會出現超時的情況。
調用代碼如下:List<User> users = remoteCallUser(ids);
眾所周知,調用接口從數據庫獲取數據需要經過網絡傳輸。如果數據量過大,無論是數據獲取速度還是網絡傳輸速度都會受到帶寬限制,從而導致耗時較長。
那么,這種情況下該如何優化呢?
答案是:分頁處理。
將一次性獲取所有數據的請求,改為分多次獲取,每次只獲取一部分用戶的數據,最后進行合并和匯總。
其實,處理這個問題可以分為兩種場景:同步調用和異步調用。
如果在job中需要獲取2000個用戶的信息,它要求只要能正確獲取到數據即可,對獲取數據的總耗時要求不高。
但對每一次遠程接口調用的耗時有要求,不能大于500ms,否則會有郵件預警。
這時,我們可以同步分頁調用批量查詢用戶信息接口。
具體示例代碼如下:
List<List<Long>>?allIds?=?Lists.partition(ids,?200);
for?(List<Long>?batchIds?:?allIds)?{
????List<User>?users?=?remoteCallUser(batchIds);
}代碼中我使用了Google Guava工具中的Lists.partition方法,用它來做分頁簡直太好用了,不然要寫一大堆分頁的代碼。 8.2 異步調用 如果是在某個接口中需要獲取2000個用戶的信息,需要考慮的因素更多。
除了遠程調用接口的耗時,還需要考慮該接口本身的總耗時,也不能超過500ms。
這時,使用上面的同步分頁請求遠程接口的方法肯定是行不通的。
那么,只能使用異步調用了。
代碼如下:
List<List<Long>>?allIds?=?Lists.partition(ids,?200);
final?List<User>?result?=?Lists.newArrayList();
allIds.stream().forEach(batchIds?->?{
????CompletableFuture.supplyAsync(()?->?{
????????result.addAll(remoteCallUser(batchIds));
????????return?Boolean.TRUE;
????},?executor);
});使用CompletableFuture類,通過多個線程異步調用遠程接口,最后匯總結果統一返回。
通常情況下,我們最常用的緩存是:Redis和Memcached。
但對于Java應用來說,絕大多數情況下使用的是Redis,所以接下來我們以Redis為例。
在關系型數據庫(例如:MySQL)中,菜單通常有上下級關系。某個四級分類是某個三級分類的子分類,三級分類是某個二級分類的子分類,而二級分類又是某個一級分類的子分類。
這種存儲結構決定了,想一次性查出整個分類樹并非易事。這需要使用程序遞歸查詢,而如果分類很多,這個遞歸操作會非常耗時。
因此,如果每次都直接從數據庫中查詢分類樹的數據,會是一個非常耗時的操作。
這時我們可以使用緩存。在大多數情況下,接口直接從緩存中獲取數據。操作Redis可以使用成熟的框架,比如:Jedis和Redisson等。 使用Jedis的偽代碼如下:
String?json?=?jedis.get(key);
if?(StringUtils.isNotEmpty(json))?{
????CategoryTree?categoryTree?=?JsonUtil.toObject(json);
????return?categoryTree;
}
return?queryCategoryTreeFromDb();注意引入緩存之后,我們的系統復雜度就上升了,這時候就會存在數據不一致的問題
如何解決數據不一致的問題,感興趣的小伙伴可以看我的另一篇文章,《億級電商流量,高并發下Redis與MySQL的數據一致性如何保證》
有時候,接口性能受限的并不是其他方面,而是數據庫。
當系統發展到一定階段,用戶并發量增加,會有大量的數據庫請求,這不僅需要占用大量的數據庫連接,還會帶來磁盤IO的性能瓶頸問題。
此外,隨著用戶數量的不斷增加,產生的數據量也越來越大,一張表可能無法存儲所有數據。由于數據量太大,即使SQL語句使用了索引,查詢數據時也會非常耗時。
那么,這種情況下該怎么辦呢?
答案是:需要進行分庫分表。
如下圖所示:
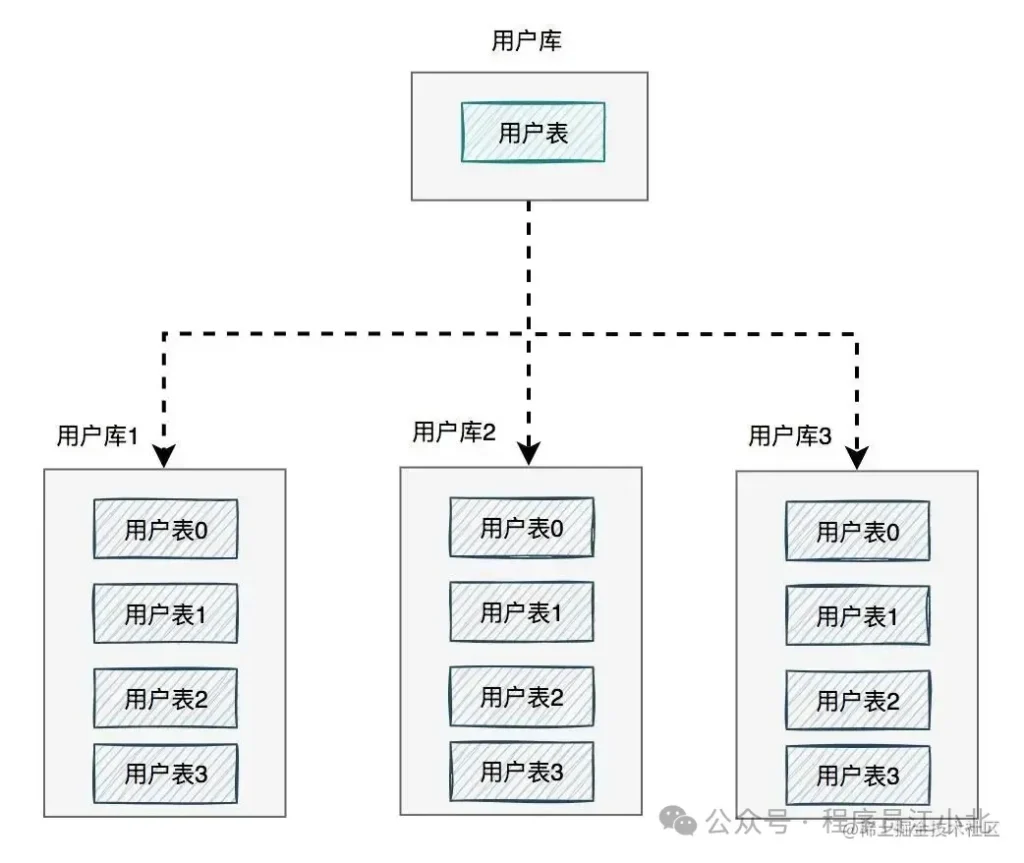
圖中將用戶庫拆分成了三個庫,每個庫都包含了四張用戶表。
如果有用戶請求過來,先根據用戶ID路由到其中一個用戶庫,然后再定位到某張表。
路由的算法有很多:
7%4=3,模為3,路由到用戶表3。1. 垂直分庫分表
垂直分庫分表(即業務方向)更簡單,將不同的業務數據存儲在不同的庫或表中。
例如,將用戶數據和訂單數據存儲在不同的庫中。
2. 水平分庫分表
水平分庫分表(即數據方向)上,分庫和分表的作用有區別,不能混為一談。
優化接口性能問題,除了上面提到的這些常用方法之外,還需要配合使用一些輔助功能,因為它們真的可以幫我們提升查找問題的效率。
通常情況下,為了定位SQL的性能瓶頸,我們需要開啟MySQL的慢查詢日志。把超過指定時間的SQL語句單獨記錄下來,方便以后分析和定位問題。
開啟慢查詢日志需要重點關注三個參數:
通過MySQL的SET命令可以設置:
SET?GLOBAL?slow_query_log?=?'ON';
SET?GLOBAL?slow_query_log_file?=?'/usr/local/mysql/data/slow.log';
SET?GLOBAL?long_query_time?=?2;
設置完之后,如果某條SQL的執行時間超過了2秒,會被自動記錄到slow.log文件中。
當然,也可以直接修改配置文件my.cnf:
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 2
但這種方式需要重啟MySQL服務。
很多公司每天早上都會發一封慢查詢日志的郵件,開發人員根據這些信息優化SQL。
為了在出現SQL問題時能夠及時發現,我們需要對系統做監控。
目前業界使用比較多的開源監控系統是:Prometheus。
它提供了監控和預警的功能。
架構圖如下:
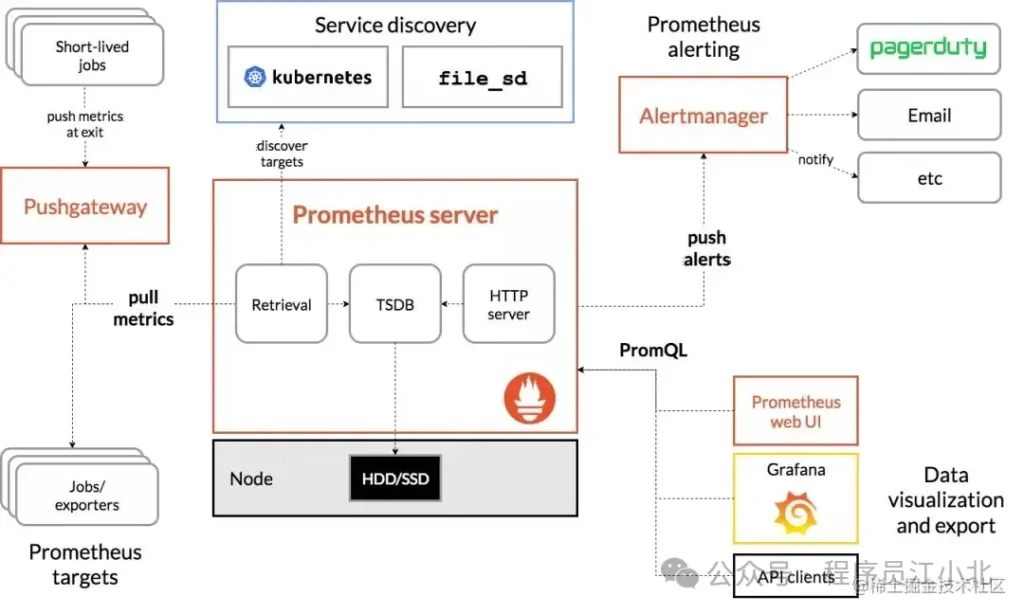
我們可以用它監控如下信息:
它的界面大概長這樣子:
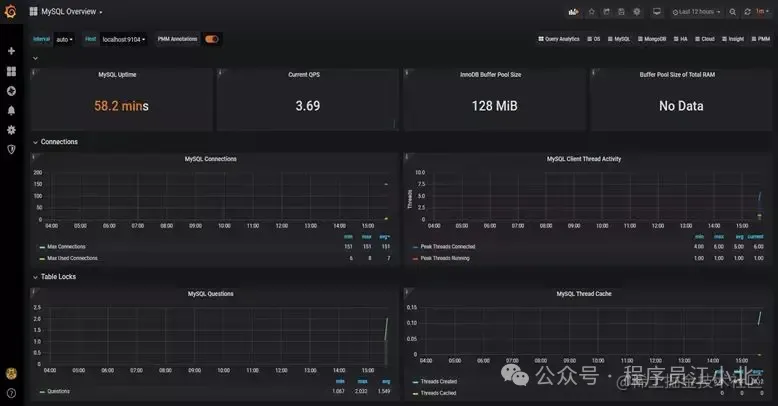
可以看到MySQL的當前QPS、活躍線程數、連接數、緩存池的大小等信息。
如果發現連接池占用的數據量太多,肯定會對接口性能造成影響。
這時可能是由于代碼中開啟了連接卻忘記關閉,或者并發量太大導致的,需要進一步排查和系統優化
有時候,一個接口涉及的邏輯非常復雜,例如查詢數據庫、查詢Redis、遠程調用接口、發送MQ消息以及執行業務代碼等等。
這種情況下,接口的一次請求會涉及到非常長的調用鏈路。如果逐一排查這些問題,會耗費大量時間,此時我們已經無法用傳統的方法來定位問題。
有沒有辦法解決這個問題呢?
答案是使用分布式鏈路跟蹤系統:SkyWalking。
SkyWalking的架構圖如下:
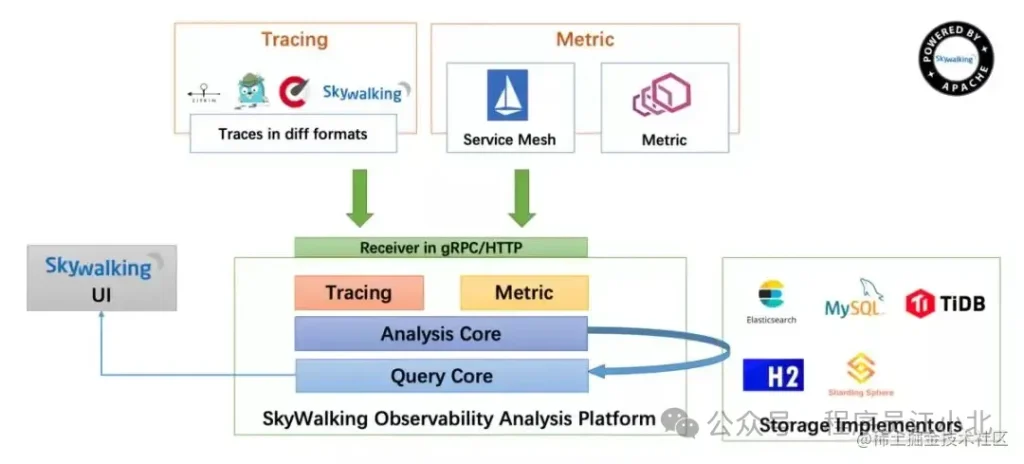
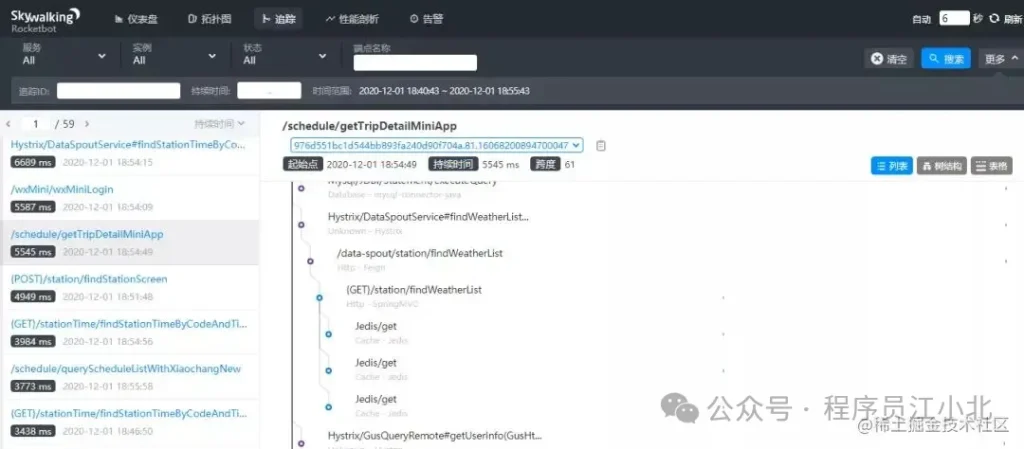
在SkyWalking中,可以通過traceId(全局唯一的ID)來串聯一個接口請求的完整鏈路。你可以看到整個接口的耗時、調用的遠程服務的耗時、訪問數據庫或者Redis的耗時等,功能非常強大。
之前沒有這個功能時,為了定位線上接口性能問題,我們需要在代碼中加日志,手動打印出鏈路中各個環節的耗時情況,然后再逐一排查。這種方法不僅費時費力,而且容易遺漏細節。
如果你用過SkyWalking來排查接口性能問題,你會不自覺地愛上它的功能。如果你想了解更多功能,可以訪問SkyWalking的官網:skywalking.apache.org。
認真看到這里的同學,相信已經對API接口性能優化有一個清晰的、系統的認知了,如果在面試中能夠完整的說出這11種API接口性能優化的思路,相信面試官一定會對你刮目相看的。
文章轉自 微信公眾號@程序員江小北