 文本相似度比較API【杭州數脈】【數脈科技】
文本相似度比較API【杭州數脈】【數脈科技】 
- API介紹
- API渠道
- API接口
- 定價


什么是文本相似度比較?
基于當前市場需求,文本相似度比較API服務應運而生。這類API服務利用全網海量數據和先進的深度神經網絡技術,為用戶提供高精度的文本相似度比較服務。通過分析語義相似度,這些API能夠幫助用戶快速實現推薦、檢索和排序等應用。
文本相似度比較API的核心功能在于分析兩個文本之間的語義相似程度。這些API借助先進的算法,如基于余弦相似度的文本向量計算等,可以準確評估文本之間的相似度。其優勢在于提供高效、快速的搜索與替換語義功能,同時能夠幫助用戶進行文本排序,更好地表達句意。
企業可以通過接入文本相似度比較API,提升其搜索引擎的準確性,并降低人工識別成本。這類API不僅可以用于電商購物平臺,幫助消費者快速獲得答案,還可以應用于搜索引擎平臺,幫助用戶解決描述問題的困難。通過短文本相似度比較API,用戶可以更加便捷地獲取相關信息,提升了用戶體驗,也為企業節約了成本,實現了雙贏局面。
本相似度比較API服務的出現,為用戶提供了一種高效、準確的文本相似度比較解決方案,助力用戶實現多種文本處理任務,提升了搜索引擎的準確性,降低了企業的人工成本。

文本相似度比較有哪些核心功能?
1. 短文本相似度計算
- 語義深度分析:不同于簡單的字符串匹配或關鍵詞比對,短文本相似度計算能夠深入到文本的語義層面,理解文本背后的含義和上下文。這通常依賴于自然語言處理(NLP)技術,如詞嵌入(Word Embeddings)、BERT等預訓練語言模型,它們能夠捕捉詞匯之間的語義關系。
- 量化評估:通過計算得到的相似度值(通常是0到1之間的實數),可以直觀地反映兩個短文本之間的相似程度。這個值不僅便于人類理解,也便于機器處理,為后續的數據分析、決策制定等提供基礎。
- 應用場景廣泛:短文本相似度計算在信息檢索、內容推薦、抄襲檢測、問答系統等多個領域都有重要應用。例如,在搜索引擎中,通過計算用戶查詢與網頁內容的相似度,可以返回更相關的結果;在內容推薦系統中,則可以根據用戶的歷史行為推薦相似的內容。
2. 短文本相似聚合
- 信息去冗:在大量短文本數據中,往往存在內容相近或重復的文本。通過短文本相似聚合功能,可以自動識別和歸類這些文本,減少信息的冗余,提高信息處理的效率。
- 內容精簡:聚合后的文本集合更加緊湊,便于用戶快速瀏覽和理解。在新聞聚合、社交媒體內容整理等場景中,這有助于提升用戶體驗。
- 優化決策制定:在電商、科研等領域,短文本相似聚合可以幫助決策者快速了解市場趨勢、研究熱點等信息,從而做出更加明智的決策。
- 自動化處理:該功能通常能夠自動化運行,無需人工干預,大大提高了處理大量文本數據的效率。
文本相似度比較的技術原理是什么?
- 文本表示:
- 分詞:首先,將待比較的文本進行分詞處理,即將文本切分為一系列有意義的詞語或詞組。
- 向量化:然后,利用詞袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)模型、詞嵌入(Word Embeddings)等方法,將文本轉換為高維向量空間中的點(即文本的數值化表示)。其中,詞嵌入方法如Word2Vec、GloVe等,能夠更好地捕捉詞語之間的語義關系。
- 相似度計算:
- 在文本被表示為向量后,可以通過計算向量之間的距離或相似度來評估文本之間的相似程度。常用的相似度度量方法包括余弦相似度(Cosine Similarity)、歐氏距離(Euclidean Distance)、曼哈頓距離(Manhattan Distance)等。
- 余弦相似度是通過計算兩個向量在夾角上的余弦值來評估它們的相似度,值越接近1表示越相似;而歐氏距離和曼哈頓距離則是通過計算兩個向量在空間中的直線距離來評估它們的差異,距離越小表示越相似。
文本相似度比較的核心優勢是什么?
 |
 |
 |
|
標準API接口 |
服務商賬號統一管理 |
零代碼集成服務商 |
 |
 |
 |
|
智能路由
|
服務擴展 服務擴展不僅提供特性配置和歸屬地查詢等增值服務,還能根據用戶需求靈活定制解決方案,滿足多樣化的業務場景,進一步提升用戶體驗和滿意度。
|
可視化監控 |
在哪些場景會用到文本相似度比較?
1. 信息檢索
在信息檢索領域,"文本相似度比較"API接口的應用極為廣泛且深入。它不僅能夠處理傳統的純文本檢索任務,幫助用戶從海量數據中快速找到與查詢文本相似的內容,提升檢索的準確性和效率;還能夠跨越媒體界限,結合標簽、元數據等信息,實現對圖片、視頻等非文本內容的相似度檢索。例如,在圖像搜索引擎中,通過提取圖片中的文本描述或標簽,利用文本相似度算法,可以為用戶推薦視覺上相似或主題相關的圖片;在視頻平臺,則可以基于視頻標題、簡介或自動生成的字幕進行相似視頻推薦,滿足用戶多樣化的信息需求。

2. 新聞推薦
新聞推薦系統是"文本相似度比較"API接口的又一重要應用場景。隨著新聞媒體的快速發展,用戶每天面對的信息量呈爆炸式增長。為了提升用戶體驗,新聞推薦系統會根據用戶的歷史瀏覽記錄,特別是用戶剛剛瀏覽的新聞標題,利用文本相似度算法快速檢索出與之相似的其他新聞,并個性化地推送給用戶。這樣不僅能夠幫助用戶發現更多感興趣的內容,還能有效緩解信息過載問題,提升新聞閱讀的針對性和滿意度。

3. 智能客服
在智能客服領域,"文本相似度比較"API接口同樣扮演著關鍵角色。當用戶輸入一個問題時,智能客服系統首先會利用文本相似度算法在已有的問題庫中尋找與之相似的問題及其答案。如果找到高度相似的問題,系統便能迅速給出相應的答案,實現快速響應;如果沒有找到完全匹配的問題,系統還可以根據相似度排序,提供可能相關的答案或引導用戶進一步描述問題。這種方式不僅提高了客服響應的速度和準確性,還減輕了人工客服的負擔,提升了用戶滿意度和企業的服務效率。此外,隨著對話的深入,系統還能不斷學習和優化,提升對用戶意圖的理解能力,提供更加精準和個性化的服務。

4. 學術論文查重
在學術研究和出版領域,"文本相似度比較"API接口是防止學術不端行為(如抄襲、剽竊)的重要工具。當學者或出版商提交學術論文時,系統可以自動運行文本相似度比較算法,將待檢查的論文與數據庫中的已有文獻進行比對。這不僅能夠識別出直接的文本復制,還能捕捉到經過改寫但仍保留原意的相似段落。通過設定合適的相似度閾值,系統能夠輔助評審人員快速篩選出可能存在抄襲嫌疑的論文,從而維護學術界的誠信和研究的原創性。
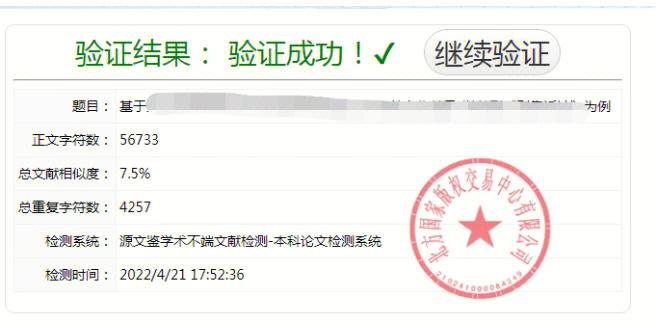
什么是文本相似度比較API?
文本相似度比較API通過語義分析技術,計算兩段文本之間的相似度得分。這一解決方案適用于文本比對、內容審核及相同內容檢測,無論是自然語言處理、機器翻譯還是信息檢索領域,都能提供高效的支持。
文本相似度比較API的核心功能有哪些?
高精度相似度計算
利用語義分析算法,精準評估兩文本相似程度,為用戶提供明確的相似度得分,助力相關應用的性能提升。
多語言支持
不僅支持中文文本,還能處理多種語言,擴展了API的適用范圍,為全球用戶提供便利。
實時響應
高效的計算能力確保API能夠及時返回相似度得分,支持實時應用需求,提升用戶體驗。
靈活集成
API設計簡潔易用,可無縫集成入各種系統,使開發者能夠快速應用此功能提升項目的智能化程度。
文本相似度比較API的技術原理是什么?
文本相似度比較有哪些應用場景?
為什么要進行文本相似度比較API試用?
文本相似度計算的精度可能因應用場景不同而存在差異,試用可以幫助您確認此API是否滿足特定業務需求。
通過試用文本相似度API,您可以直觀感受調用流程及文檔質量,判斷集成的簡易程度。
試用文本相似度API提前發現調用次數或語言支持等限制,確保后續使用不受影響。
通過試用API來測試其穩定性和響應速度,降低正式集成時出現技術障礙的風險。
為什么要集成通用API
標準API接口
我們提供標準的API接口和詳細的接入文檔,幫助用戶快速、便捷地將服務集成到自己的應用程序中。接入流程簡單明了,無需復雜的配置和調試即可實現快速接入。
零代碼集成服務商
通過一套改進過的流程來實現研發過程的零采購、零干擾。讓程序員優先對接API服務,匹配業務需求,驗證項目可行性上線之后再啟動采購,24小時內即可上線運行
智能路由
采用智能路由規則,動態分配識別通道,有效提升了驗證的準確率,其性能高于同行業平臺,通過不斷優化算法和模型,確保精準度和準確性
服務擴展
服務擴展不僅提供文本相似度比較API的特性配置與增值服務,還能根據用戶需求靈活定制解決方案,滿足多樣化的業務場景,進一步提升用戶體驗和滿意度。
| 參數名 | 參數類型 | 默認值 | 是否必傳 | 描述 |
|---|---|---|---|---|
| text1 | string | 是 | ||
| text2 | string | 是 | ||
| lang | string | 是 | 支持的文本語言類型,默認為“zh” |
| 參數名 | 參數類型 | 默認值 | 描述 |
|---|---|---|---|
| similarity | number |
| 錯誤碼 | 錯誤信息 | 描述 |
|---|---|---|
| FP00000 | SUCCESS | |
| FP03333 | FAILURE |
請求參數{
"text1": "",
"text2": "",
"lang": ""
}
返回參數
{
"similarity": ""
}
錯誤碼
{
"FP00000": "SUCCESS",
"FP03333": "FAILURE"
}
